背景 在软件开发过程中CI/CD是不可或缺的环节,在提高交付效率的同时能规范整套流程。然而不同公司的产品不一,部署环境差异导致所需的编译环境,单一的saas平台不一定能满足,同时售价也较高。这时通过自研一套公司定制的CI/CD系统,能够灵活控制每个环境,结合公司所处环境进行定制化研发。能够带了效率上的提升与各个流程的规范。
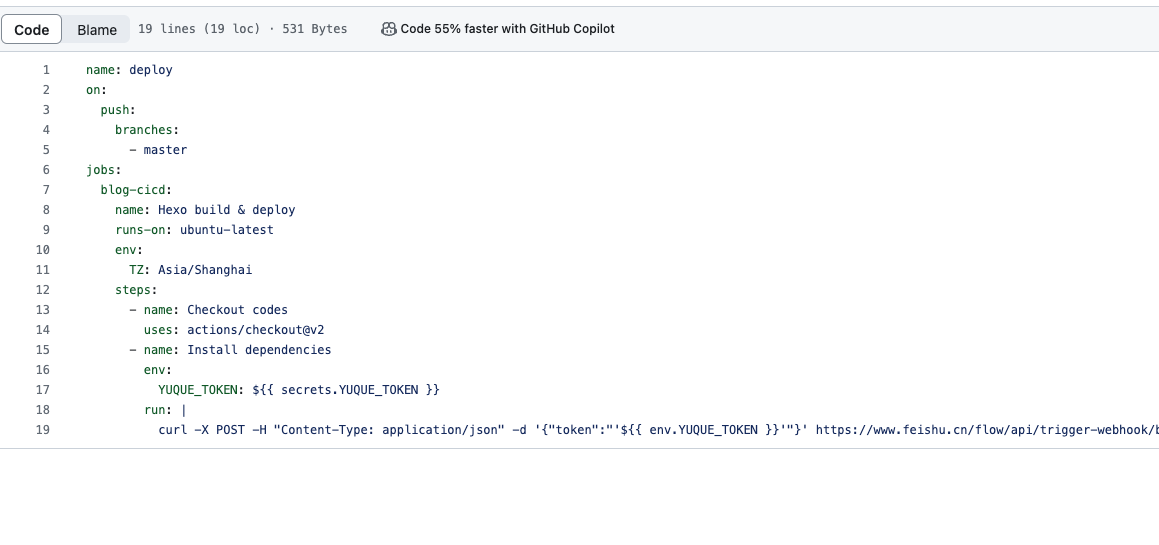
调研 github action定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 name: deployjobs :env :'16.x' ${{ runner.os } }-node-${{ hashFiles('**/package-lock.json') } }env :${{ secrets.YUQUE_TOKEN } }${{ secrets.YUQUE_TOKEN } } yuque-hexo-lyrics sync ${{ secrets.GITHUB_TOKEN } }
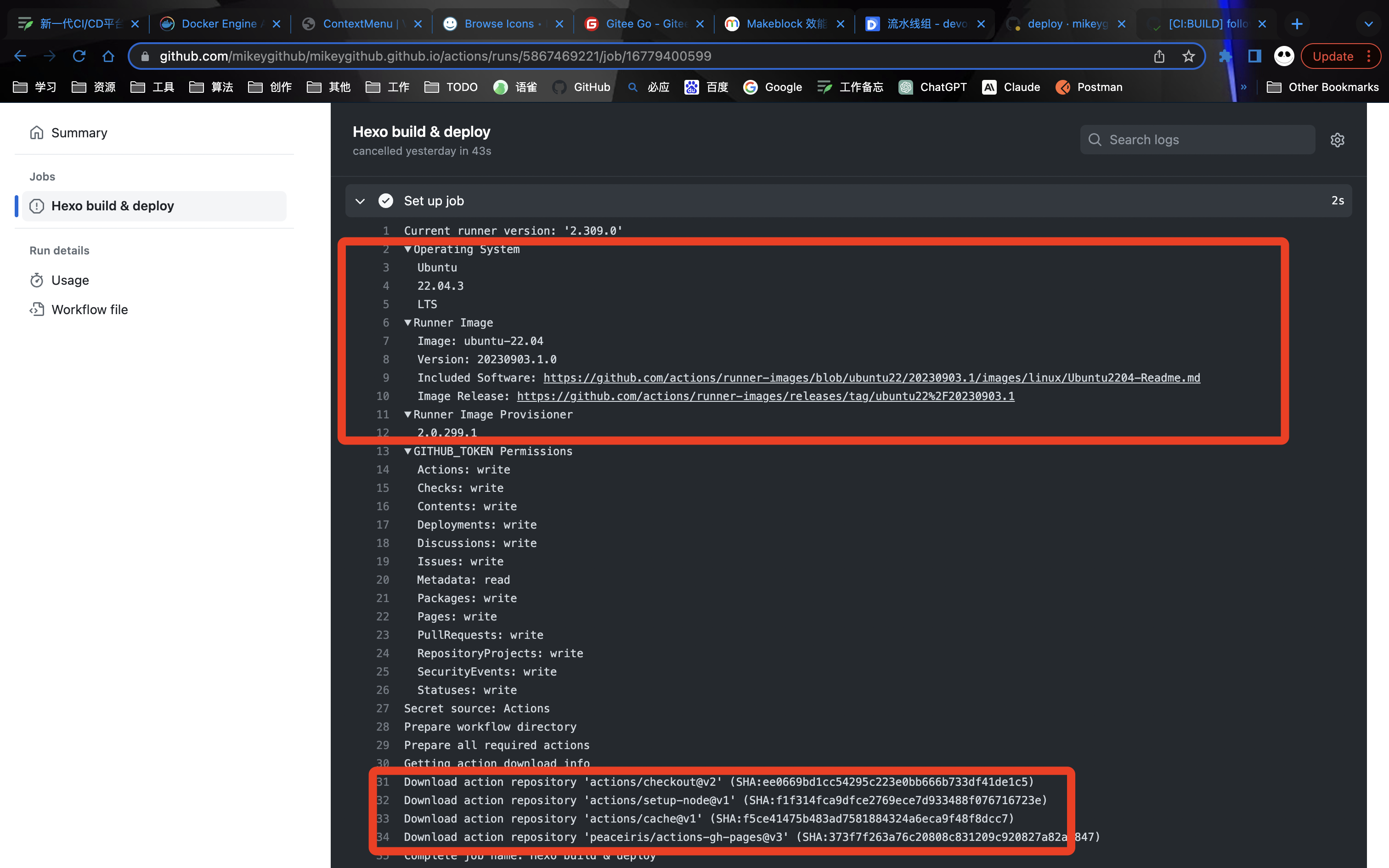
工作运行原理 根据yaml配置的job详细进行设置运行环境,同一个job会在一个runner中运行,所产生的数据每个step共享
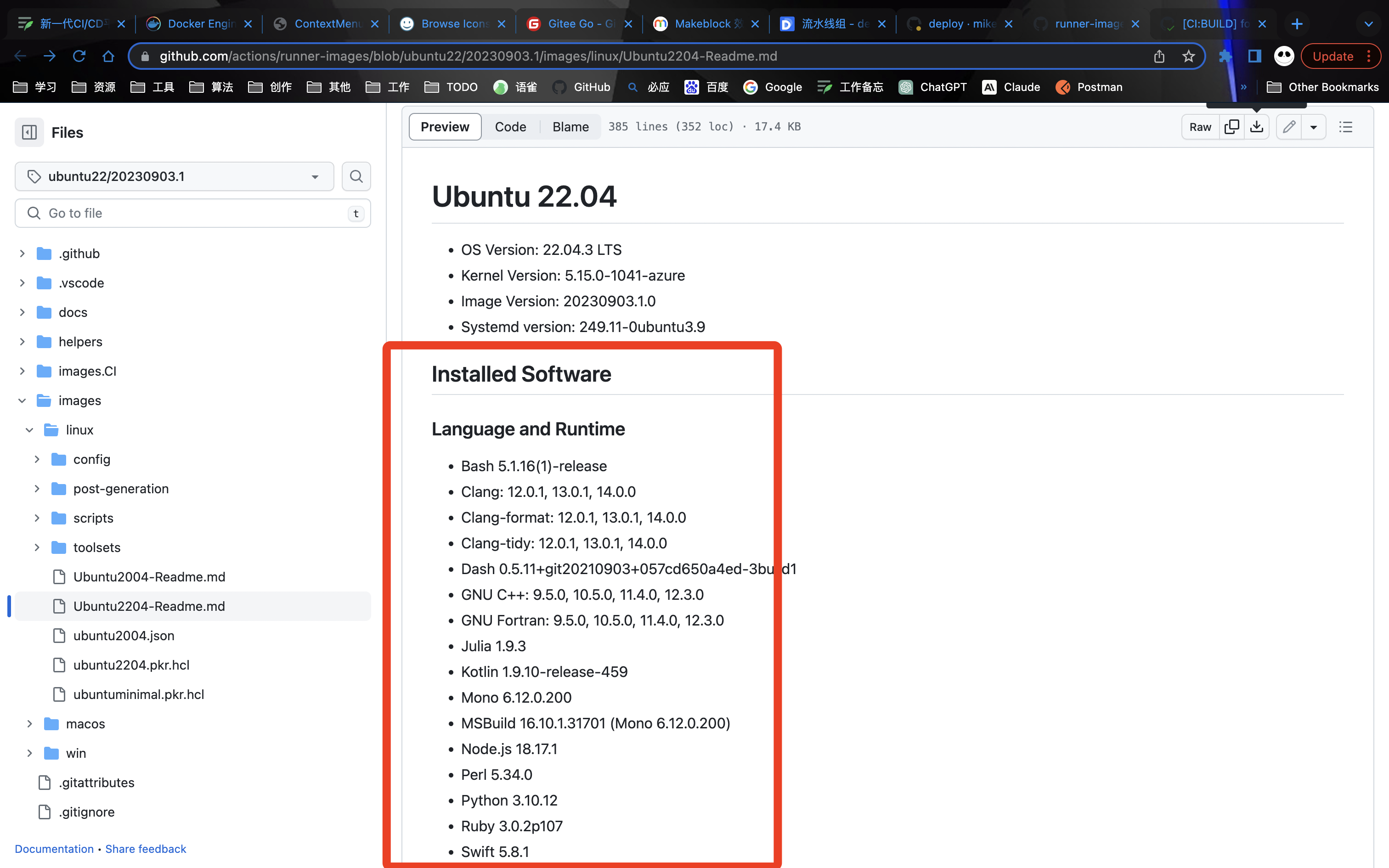
在镜像中预先安装的相关软件,如 git 、maven、node、kubectl等等。
镜像中安装的软件详细数据:Ubuntu2204-Readme.md
action插件 参考github action自定义插件,支持自定义镜像和插件
actions是通过js或者ts编写的,每次在执行pipeline时扫描当前配置文件引用了哪些actions进行下载后到容器里面在进行执行该插件的入口文件
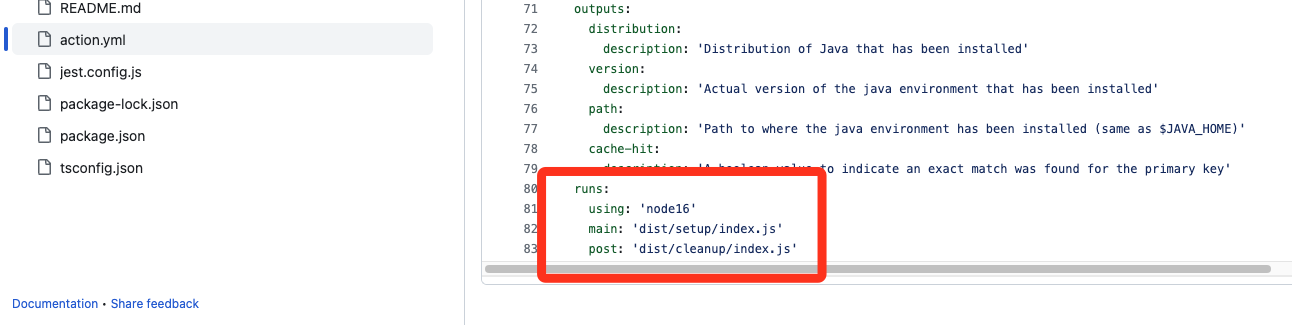
在插件的仓库中有配置该插件的执行入口文件是哪个,同时插件会在文件中说明好所需的运行环境如下图 ‘node16’
actions的执行日志通过调用 import * as core from '@actions/core' core 库进行打印
runs-on支持self-hosted和Ubuntu镜像
self-hosted 表示使用我们自己的机器来跑 job,其实就是将 runner 安装到本地机器来跑任务
总结 优点:
基于插件的方式灵活到爆炸,同时插件生态丰富,基于社区一起进行维护。
runner 独立部署,能够适应不同的平台环境跑特定的任务。
缺点:
不支持人工卡点。
权限管控不够完善,仓库所有者都能进行修改。
gitee Pipeline定义 代码方式进行编辑
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 version: '1.0' name: pipeline-full displayName: pipeline-full triggers: trigger: auto push: branches: prefix: - 00 - stages: - name: stage-592913d5 displayName: '000' strategy: fast trigger: auto executor: - mikeygitee steps: - step: build@gcc name: build_gcc displayName: GCC 构建 gccVersion: '9.4' commands: - '# 新建build目录,切换到build目录' - 'mkdir build && cd build ' - '# 生成Unix平台的makefiles文件并执行构建' - cmake -G 'Unix Makefiles' ../ && make -j artifacts: - name: BUILD_ARTIFACT path: - ./bin caches: []notify: []strategy: retry: '0' - step: build@docker name: build_docker displayName: 镜像构建 type: cert certificate: '' tag: ${GITEE_PIPELINE_BUILD_NUMBER} dockerfile: ./Dockerfile context: '' artifacts: []isCache: false parameter: {}notify: []strategy: retry: '0' - step: build@ruby name: build_ruby displayName: Ruby 构建 rubyVersion: 3.0 .2 commands: - bundle install - chmod +x -R bin - bin/rails webpacker:install - bin/rails db:migrate RAILS_ENV=test - bin/rails test - RAILS_ENV=production bin/rails assets:precompile artifacts: - name: BUILD_ARTIFACT path: - ./ - name: '' path: - '' caches: - '' notify: []strategy: retry: '0' - step: build@php name: build_php displayName: PHP 构建 phpVersion: '8.0' commands: - '# 设置全局composer依赖仓库地址' - composer config -g secure-http false - composer config -g repo.packagist composer https://mirrors.aliyun.com/composer/ - composer install - php -v artifacts: - name: BUILD_ARTIFACT path: - ./ caches: []notify: []strategy: retry: '0' - step: build@python name: build_python displayName: Python 构建 pythonVersion: '3.9' commands: - pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple - '# 可以使用pip下载依赖' - '# pip install --user -r requirements.txt' - python --version artifacts: - name: BUILD_ARTIFACT path: - ./ caches: []notify: []strategy: retry: '0' - step: build@golang name: build_golang displayName: Golang 构建 golangVersion: '1.12' commands: - '# 默认使用goproxy.cn' - export GOPROXY=https://goproxy.cn - '# 输入你的构建命令' - make build artifacts: - name: BUILD_ARTIFACT path: - ./output caches: - /go/pkg/mod notify: []strategy: retry: '0' - step: build@gradle name: build_gradle displayName: Gradle 构建 jdkVersion: '8' gradleVersion: '4.4' commands: - '# Gradle默认构建命令' - chmod +x ./gradlew - ./gradlew build artifacts: - name: BUILD_ARTIFACT path: - ./target caches: - ~/.gradle/caches notify: []strategy: retry: '0' - step: build@maven name: build_maven displayName: Maven 构建 jdkVersion: '8' mavenVersion: 3.3 .9 commands: - '# 功能:打包' - '# 参数说明:' - '# -Dmaven.test.skip=true:跳过单元测试' - '# -U:每次构建检查依赖更新,可避免缓存中快照版本依赖不更新问题,但会牺牲部分性能' - '# -e -X :打印调试信息,定位疑难构建问题时建议使用此参数构建' - '# -B:以batch模式运行,可避免日志打印时出现ArrayIndexOutOfBoundsException异常' - '# 使用场景:打包项目且不需要执行单元测试时使用' - mvn clean package -Dmaven.test.skip=true -U -e -X -B - '' - '# 功能:自定义settings配置' - '# 使用场景:如需手工指定settings.xml,可使用如下方式' - '# 注意事项:如无需自定义settings配置且需要私有依赖仓库,可在该任务配置《私有仓库》处添加私有依赖' - '# mvn -U clean package -s ./settings.xml' - '' artifacts: - name: BUILD_ARTIFACT path: - ./target settings: []caches: - ~/.m2 notify: []strategy: retry: '0' - step: build@nodejs name: build_nodejs displayName: Nodejs 构建 nodeVersion: 14.16 .0 commands: - '# 设置NPM源,提升安装速度' - npm config set registry https://registry.npmmirror.com - '' - '# 执行编译命令' - npm install && npm run build artifacts: - name: BUILD_ARTIFACT path: - ./dist caches: - ~/.npm - ~/.yarn notify: []strategy: retry: '0' - name: stage-ae79d813 displayName: 未命名 strategy: naturally trigger: auto executor: []steps: - step: ut@maven name: unit_test_maven displayName: Maven 单元测试 jdkVersion: '8' mavenVersion: 3.3 .9 commands: - '# Maven单元测试默认命令' - mvn -B test -Dmaven.test.failure.ignore=true - mvn surefire-report:report-only - mvn site -DgenerateReports=false report: path: ./target/site index: surefire-report.html checkpoints: []settings: []caches: - ~/.m2 notify: []strategy: retry: '0' - name: stage-374ffefd displayName: 未命名 strategy: naturally trigger: auto executor: []steps: - step: deploy@k8s name: deploy_k8s displayName: K8S部署 version: v1.16.4 certificate: '' namespace: default yaml: ./deployment.yaml isReplace: false skiptls: false params: null notify: []strategy: retry: '0'
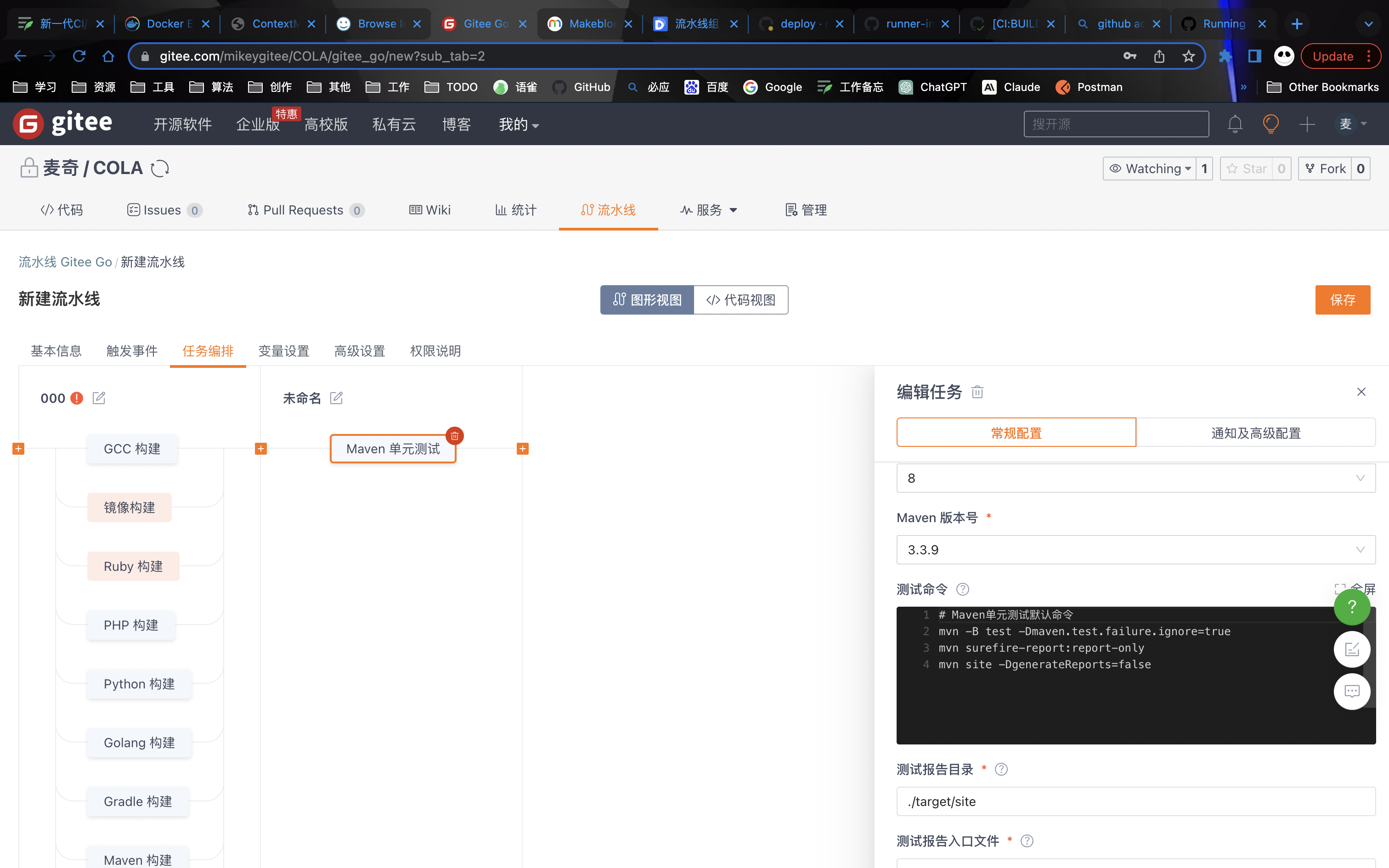
可视化方式进行编辑
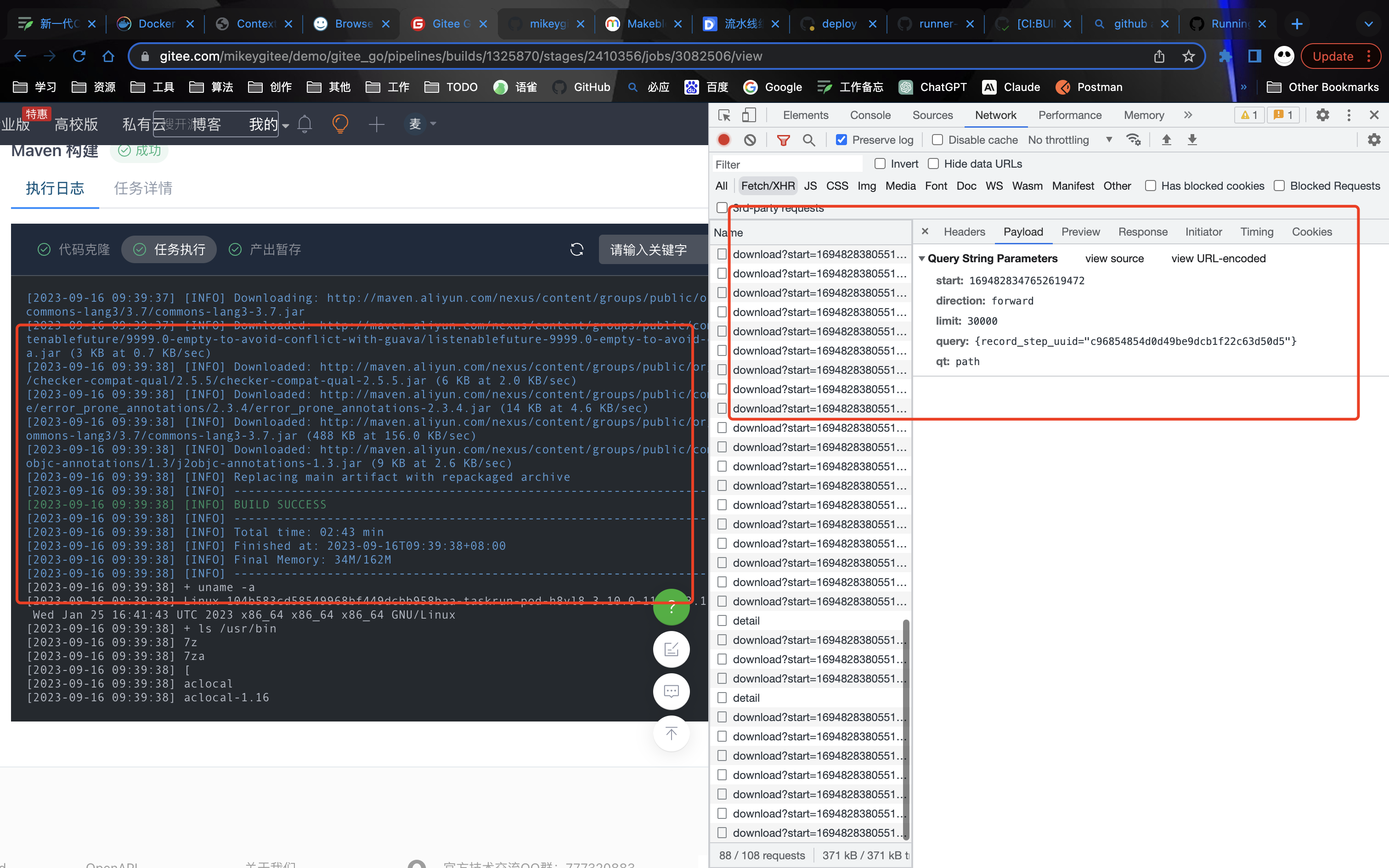
工作运行原理 拉取代码直接通过shell脚本方式进行传递给容器进行执行,如下面看到的代码 clone 方式
日志模块是通过不断的从前端去请求拿到指定时间区间内的日志数据
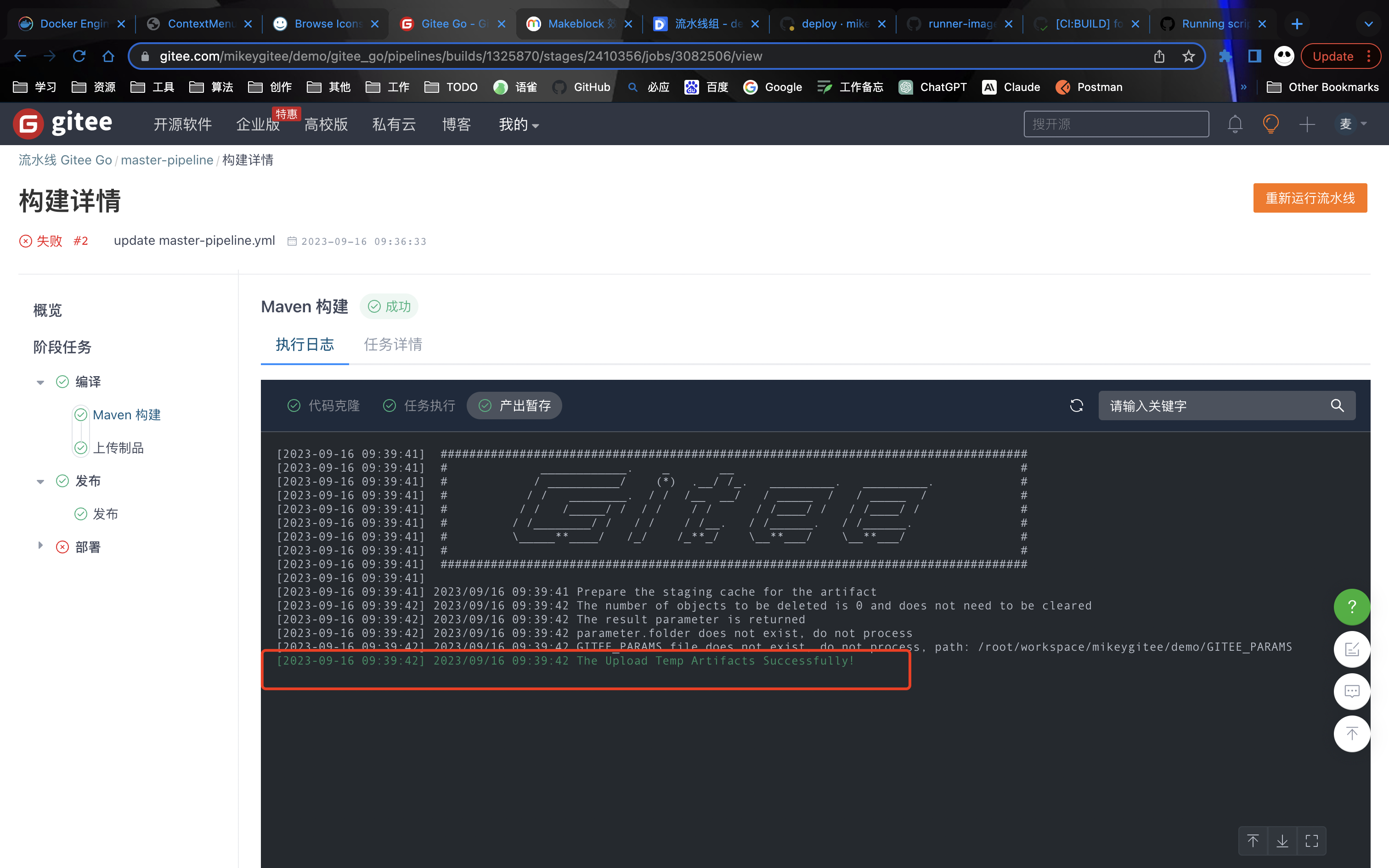
构建后的产物会进行缓存(上传)到
总结分析 优点:
支持可视化界面编辑和yaml代码方式进行编辑、灵活方便。
支持人工卡点,消息通知支持的平台丰富,权限管控完善,每个阶段都可控制执行人。
构建产物能直接传递给下一个stage,作为下个任务的输入,因为gitee的job都是直接跑在容器中,没有指定机器架构的功能所以所有任务都可以在一个节点上运行,数据共享的比较方便(盲猜通过容器挂载方式实现或者上传到OSS在需要的节点再下载)。
缺点:
不runner 独立部署,能够适应不同的平台环境跑特定的任务。
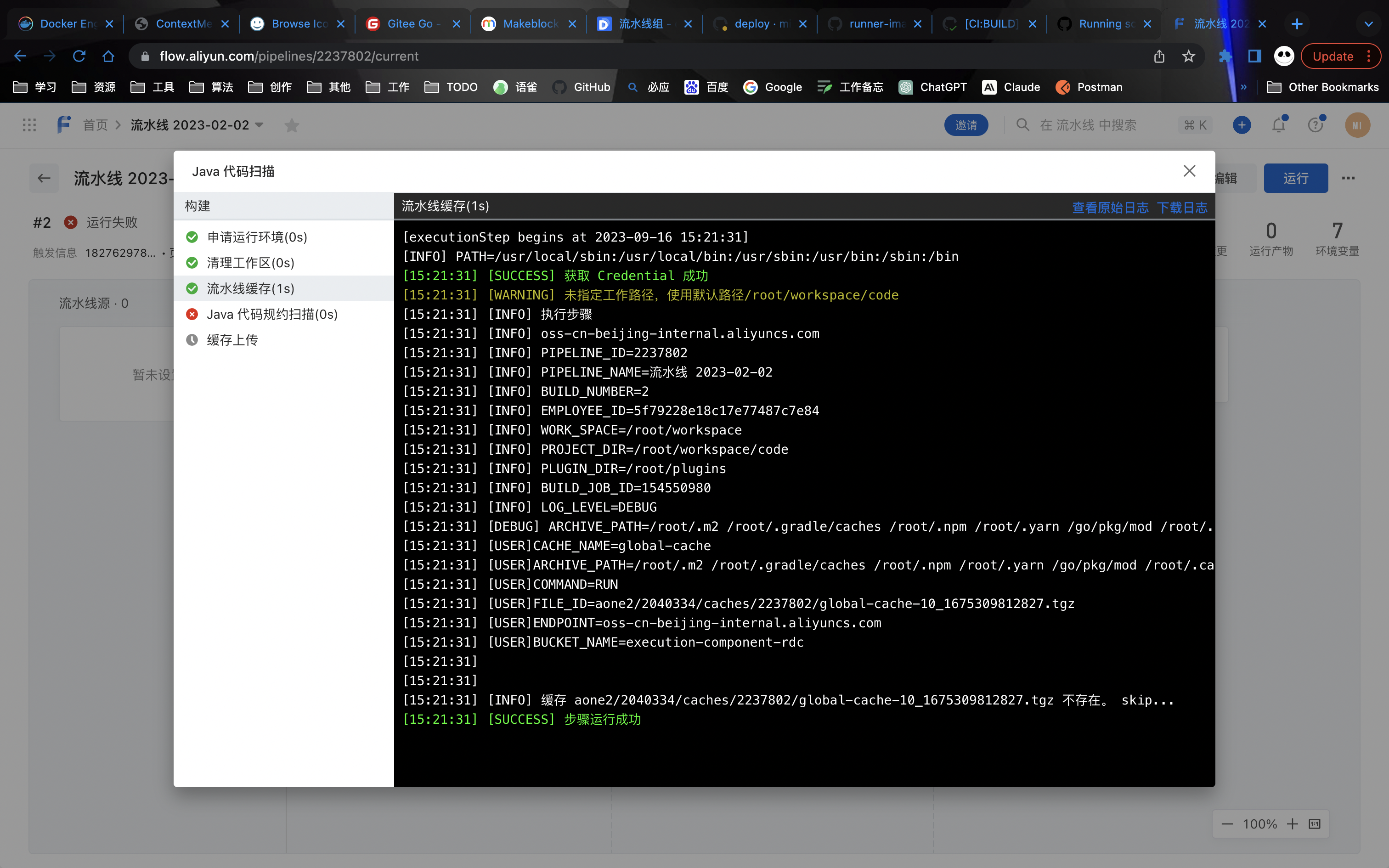
云效 Pipeline定义
工作运行原理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 rm rm "https://devops.aliyuncs.com/execution-component/getRunTimeParam?paramsId=5ba0b708-9bd9-479b-a1fc-57e31f8d270a&token=460536cfadbd323e1f8937ceecc0c5ed&stamp=1695829382492" build-steps-public-registry.cn-beijing.cr.aliyuncs.com/build-steps/cache:2.90-f815440f&&rm true -e TASK_URL="https://devops.aliyuncs.com/execution-component/getRunTimeParam?paramsId=9743b1b9-daf4-4e52-b351-91f4e71b9420&token=ae8a4181b4b498000cd1f6ff41abd351&stamp=1695829382496" rm workspace-474936350&&docker volume rm cache-474936350
总结分析 优点:
支持可视化界面编辑和yaml代码方式进行编辑、灵活方便。
支持人工卡点。
与阿里云绑定、各种资源能直接联系上,非常适合所有资源都在阿里云上的客户使用。
缺点:
不支持代码方式编辑流水线,全部需要在界面上配置
不runner 独立部署,能够适应不同的平台环境跑特定的任务。
企业使用费用较高。
总结 通过对以上三个平台的分析可知他们都有各自的优劣,github的runner能实现不同平台机器的运行能最大程度的满足自己所配置的环境,而后面两个平台提供了可视化方式进行编辑更加直观,上手难点更加低。
分析 需求
满足多环境适配,混合云、私有云部署、kubernetes、docker等
权限划分明确,严格限制每个人只能管理自己的应用。
安全可靠,能够保证秘钥安全,对普通用户将敏感数据进行加密防止泄露。
效率优先,能够支撑大量的应用并行发布,随时进行扩容伸缩。
All in one 原则,能够极大降低维护成本,提高使用效率。
个别应用的构建需要特定的环境来执行,如election、mac应用等,所以需要提供runner。
在pipeline执行过程中能够实时查看日志,中断和重启。
执行效率高、支持的并发执行数量能够满足当业务快速发展时带来膨胀的构建量。
能够完全打通CI/CD整套流程,从APP创建开始到生产上线运行。
设计
平台的各个模块详细设计
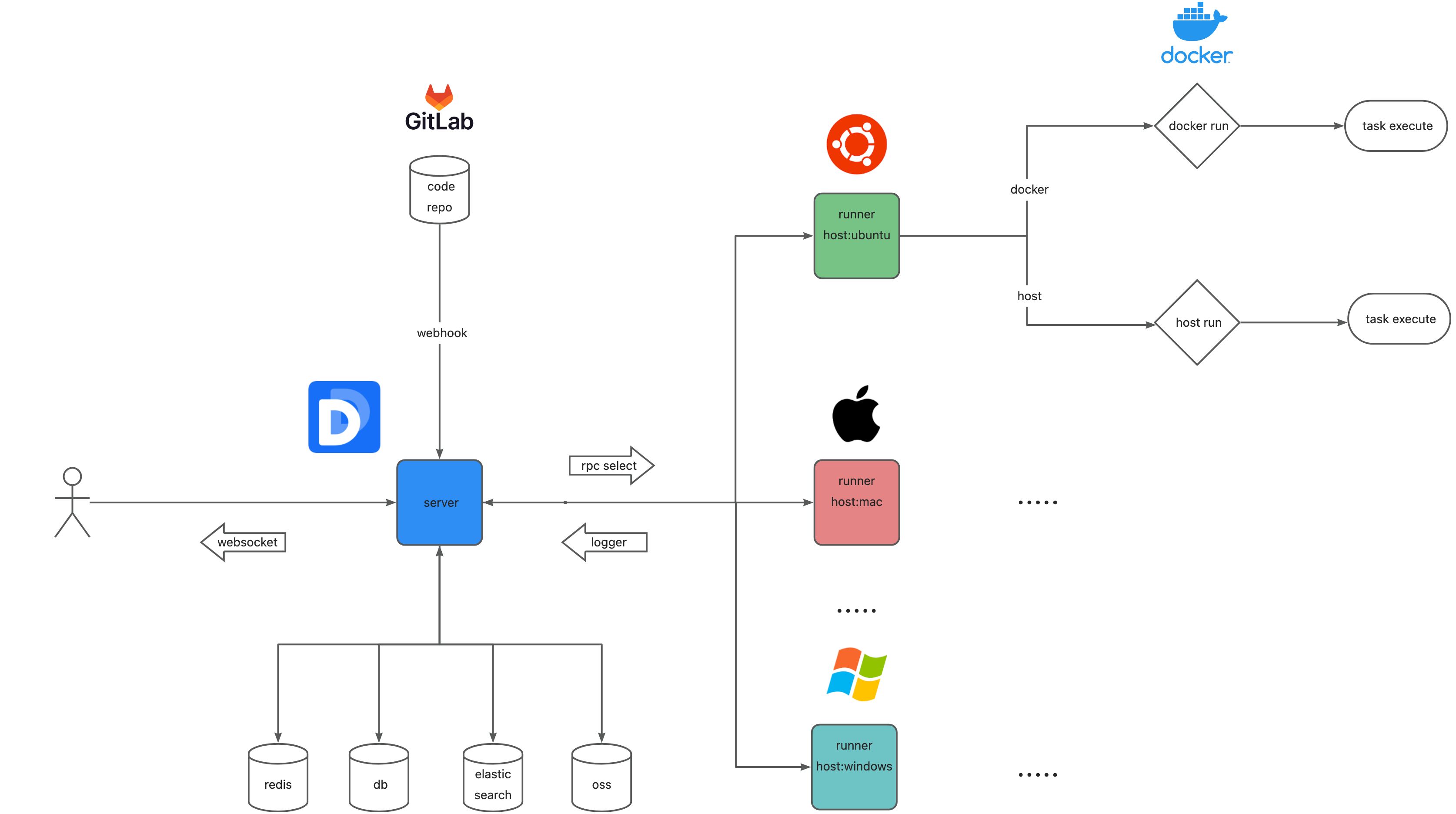
总体设计 架构图
模块划分 项目模块
项目包含应用。
应用模块
应用模块主要负责应用管理,隶属项目,项目是根据现有适配的模板进行渲染创建的。
流水线模块
负责调度workflow的主要模块,为这个平台的核心模块。
通知模块
支持飞书、钉钉等主流通知。
基础模块
用户管理、权限管理、基础配置等各个系统运行必须模块。
基础模块
项目权限管控: 分为两种角色、参与者和负责人、负责人具有修改权限、参与者只能进行查看,无法修改。
应用权限管控:
详细设计
对系统的各个模块进行细化设计,包含模型、领域对象详细设计
应用模板 统一化各类应用模板,在项目管理模块中,创建app时自动根据选择的应用类型和必填参数进行渲染模板,同时配置各个基础项,如gitlab代码仓库、CI/CD平台必填参数等。最后将渲染完成的项目基础代码模板下载给用户。
凭证管理、运行pipeline所必须的相关凭证需要有个模块来集中管理如git、k8sconfig、服务器秘钥等
任务触发
事件监听为监听git仓库的变化事件,如gitlab当发生代码提交事件、tag事件、push事件会触发webhook从而进行接收请求
分支匹配:使用正则表达式进行匹配推送的分支名称
tag匹配:tag 关键字正则表达式匹配
提交关键字匹配:git commit 关键字正则匹配
手动点击运行按钮进行触发流水线
cron方式进行触发
使用uuid作为链接提供给外部进行触发
gitlab适配
通过在gitlab的代码仓库进行注册回调地址,当仓库有人进行推送或者打tag时可以触发
1 curl --request POST --header "PRIVATE-TOKEN: <your_access_token>" "https://gitlab.example.com/api/v4/projects/<project_id>/hooks?url=<webhook_url>&push_events=true&tag_push_events=true"
添加webhook响应
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 { "id" : 2 , "url" : "https://webhook.site/b4ffd28b-cf7e-415a-b2a6-e9cf07851859" , "created_at" : "2023-10-16T02:28:35.527Z" , "push_events" : true , "tag_push_events" : true , "merge_requests_events" : false , "repository_update_events" : false , "enable_ssl_verification" : true , "alert_status" : "executable" , "disabled_until" : null , "url_variables" : [ ] , "project_id" : 1 , "issues_events" : false , "confidential_issues_events" : false , "note_events" : false , "confidential_note_events" : null , "pipeline_events" : false , "wiki_page_events" : false , "deployment_events" : false , "job_events" : false , "releases_events" : false , "push_events_branch_filter" : null , "emoji_events" : false }
推送代码响应
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 { "object_kind" : "push" , "event_name" : "push" , "before" : "27960831c6882b8dd6ee61c8c02052a02feb57aa" , "after" : "0022c24f46ba600bc528bec86bdfc39674fc788c" , "ref" : "refs/heads/main" , "ref_protected" : true , "checkout_sha" : "0022c24f46ba600bc528bec86bdfc39674fc788c" , "message" : null , "user_id" : 2 , "user_name" : "yangbiao" , "user_username" : "yangbiao" , "user_email" : null , "user_avatar" : "https://www.gravatar.com/avatar/59c797dd5f8366022c1271697f3b4e37?s=80&d=identicon" , "project_id" : 1 , "project" : { "id" : 1 , "name" : "makeblock-devops" , "description" : null , "web_url" : "http://23483c271df6/yangbiao/makeblock-devops" , "avatar_url" : null , "git_ssh_url" : "git@23483c271df6:yangbiao/makeblock-devops.git" , "git_http_url" : "http://23483c271df6/yangbiao/makeblock-devops.git" , "namespace" : "yangbiao" , "visibility_level" : 0 , "path_with_namespace" : "yangbiao/makeblock-devops" , "default_branch" : "main" , "ci_config_path" : null , "homepage" : "http://23483c271df6/yangbiao/makeblock-devops" , "url" : "git@23483c271df6:yangbiao/makeblock-devops.git" , "ssh_url" : "git@23483c271df6:yangbiao/makeblock-devops.git" , "http_url" : "http://23483c271df6/yangbiao/makeblock-devops.git" } , "commits" : [ { "id" : "0022c24f46ba600bc528bec86bdfc39674fc788c" , "message" : "Update README.md" , "title" : "Update README.md" , "timestamp" : "2023-10-16T02:29:41+00:00" , "url" : "http://23483c271df6/yangbiao/makeblock-devops/-/commit/0022c24f46ba600bc528bec86bdfc39674fc788c" , "author" : { "name" : "yangbiao" , "email" : "yangbiao@makeblock.com" } , "added" : [ ] , "modified" : [ "README.md" ] , "removed" : [ ] } ] , "total_commits_count" : 1 , "push_options" : { } , "repository" : { "name" : "makeblock-devops" , "url" : "git@23483c271df6:yangbiao/makeblock-devops.git" , "description" : null , "homepage" : "http://23483c271df6/yangbiao/makeblock-devops" , "git_http_url" : "http://23483c271df6/yangbiao/makeblock-devops.git" , "git_ssh_url" : "git@23483c271df6:yangbiao/makeblock-devops.git" , "visibility_level" : 0 } }
tag推送响应
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 { "object_kind" : "tag_push" , "event_name" : "tag_push" , "before" : "0000000000000000000000000000000000000000" , "after" : "86c8b6fd0d2c4dffdd52951c42add6c1a0bd0624" , "ref" : "refs/tags/dev-1.0.0" , "ref_protected" : false , "checkout_sha" : "0022c24f46ba600bc528bec86bdfc39674fc788c" , "message" : "devvvv" , "user_id" : 2 , "user_name" : "yangbiao" , "user_username" : "yangbiao" , "user_email" : null , "user_avatar" : "https://www.gravatar.com/avatar/59c797dd5f8366022c1271697f3b4e37?s=80&d=identicon" , "project_id" : 1 , "project" : { "id" : 1 , "name" : "makeblock-devops" , "description" : null , "web_url" : "http://23483c271df6/yangbiao/makeblock-devops" , "avatar_url" : null , "git_ssh_url" : "git@23483c271df6:yangbiao/makeblock-devops.git" , "git_http_url" : "http://23483c271df6/yangbiao/makeblock-devops.git" , "namespace" : "yangbiao" , "visibility_level" : 0 , "path_with_namespace" : "yangbiao/makeblock-devops" , "default_branch" : "main" , "ci_config_path" : null , "homepage" : "http://23483c271df6/yangbiao/makeblock-devops" , "url" : "git@23483c271df6:yangbiao/makeblock-devops.git" , "ssh_url" : "git@23483c271df6:yangbiao/makeblock-devops.git" , "http_url" : "http://23483c271df6/yangbiao/makeblock-devops.git" } , "commits" : [ { "id" : "0022c24f46ba600bc528bec86bdfc39674fc788c" , "message" : "Update README.md" , "title" : "Update README.md" , "timestamp" : "2023-10-16T02:29:41+00:00" , "url" : "http://23483c271df6/yangbiao/makeblock-devops/-/commit/0022c24f46ba600bc528bec86bdfc39674fc788c" , "author" : { "name" : "yangbiao" , "email" : "yangbiao@makeblock.com" } , "added" : [ ] , "modified" : [ "README.md" ] , "removed" : [ ] } ] , "total_commits_count" : 1 , "push_options" : { } , "repository" : { "name" : "makeblock-devops" , "url" : "git@23483c271df6:yangbiao/makeblock-devops.git" , "description" : null , "homepage" : "http://23483c271df6/yangbiao/makeblock-devops" , "git_http_url" : "http://23483c271df6/yangbiao/makeblock-devops.git" , "git_ssh_url" : "git@23483c271df6:yangbiao/makeblock-devops.git" , "visibility_level" : 0 } }
流程引擎 基于容器进行任务调度,执行完成容器销毁,资源自动回收。运行用户自定义镜像,多平台runner满足不同任务环境需求。
pipeline 核心流程
服务端解析配置文件,根据定义的文件进行配置 触发器,运行触发器进行监控触发的时机。
触发器进行触发pipeline,将配置文件描述的pipeline进行实例化,绑定对应的step,根据step的配置选择runner发送
runner 接收到 需要执行的 step 进行反序列化 进行条件准备完成后运行,将运行日志通过rpc传递给服务端,服务端检查是否有人订阅日志,有则通过websocket进行连接发送。
runner运行step完成后进行本地环境清理,如清除容器实例、workspace清理等。
context如何传递 ?
序列化后对象传递(不同的step的配置不一样,rpc不支持未知类型的传递)
传递定义的 yaml 配置,由 runner 自己进行解析(runner运行的当前step可能会依赖前面的一些产物数据,需要传递给当前runner)
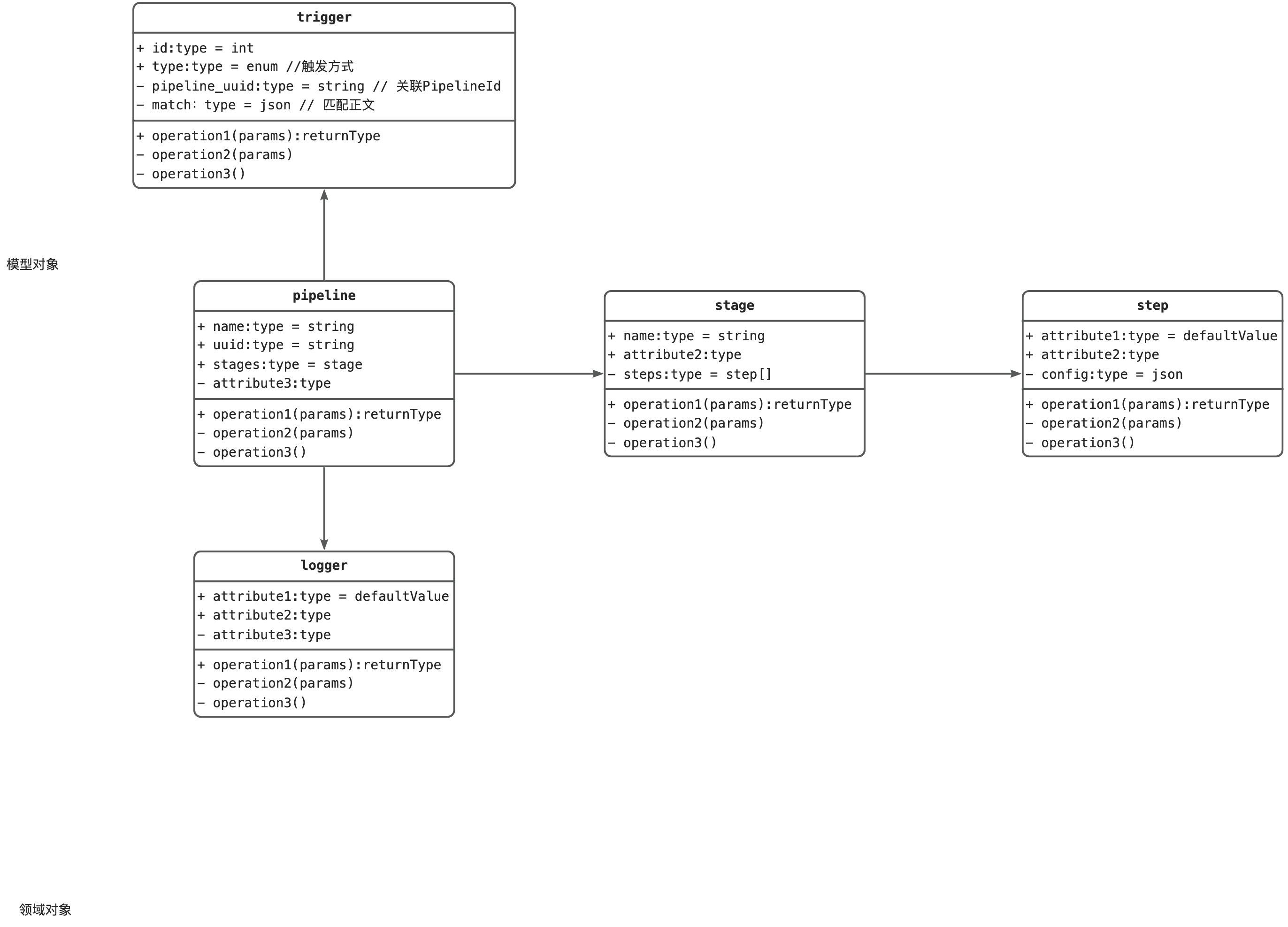
领域模型 DDL:
DDL:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 create table pipeline_infobigint unsigned auto_increment comment '主键' primary key ,varchar (32 ) not null comment 'UUID' ,varchar (32 ) not null comment '所属应用' ,varchar (100 ) not null comment '流水线名称' ,not null comment '流水线正文' ,null comment '最新触发时间' ,varchar (50 ) null comment '代码分支' ,varchar (1000 ) null comment '描述' ,varchar (64 ) null comment '创建人' ,varchar (64 ) null comment '修改人' ,not null comment '创建时间' ,not null comment '修改时间' ,char default '0' not null comment '逻辑删除' ,varchar (100 ) null comment '触发方式' '流水线' ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 create table pipeline_run_historybigint unsigned auto_increment comment '主键' primary key ,varchar (32 ) not null comment 'UUID' ,varchar (32 ) not null comment '流水线uuid' ,null comment '触发时间' ,varchar (100 ) null comment '触发方式' ,null comment '存储日志数据正文' ,null comment '执行时间' ,null comment '结束时间' ,varchar (20 ) null comment '最终执行状态' ,null comment '流水线快照' ,varchar (64 ) null comment '创建人' ,varchar (64 ) null comment '修改人' ,not null comment '创建时间' ,not null comment '修改时间' ,char default '0' not null comment '逻辑删除' '流水线执行记录' ;
Pipeline Context 定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 version: '1.0' name: pipeline-2023-09-17 triggers: trigger: auto push: branches: prefix: - 00 - stages: - name: stage-592913d5 strategy: fast trigger: auto executor: - mikeygitee steps: - step: build@gcc name: build_gcc runner: mac-arm64 run-on: self-host gccVersion: '9.4' commands: - '# 新建build目录,切换到build目录' - 'mkdir build && cd build ' - '# 生成Unix平台的makefiles文件并执行构建' - cmake -G 'Unix Makefiles' ../ && make -j artifacts: - name: BUILD_ARTIFACT path: - ./bin caches: []notify: []strategy: retry: '0' - step: build@docker name: build_docker displayName: 镜像构建 type: cert certificate: '' tag: ${GITEE_PIPELINE_BUILD_NUMBER} dockerfile: ./Dockerfile context: '' artifacts: []isCache: false parameter: {}notify: []strategy: retry: '0' - step: build@ruby name: build_ruby displayName: Ruby 构建 rubyVersion: 3.0 .2 commands: - bundle install - chmod +x -R bin - bin/rails webpacker:install - bin/rails db:migrate RAILS_ENV=test - bin/rails test - RAILS_ENV=production bin/rails assets:precompile artifacts: - name: BUILD_ARTIFACT path: - ./ - name: '' path: - '' caches: - '' notify: []strategy: retry: '0' - step: build@php name: build_php displayName: PHP 构建 phpVersion: '8.0' commands: - '# 设置全局composer依赖仓库地址' - composer config -g secure-http false - composer config -g repo.packagist composer https://mirrors.aliyun.com/composer/ - composer install - php -v artifacts: - name: BUILD_ARTIFACT path: - ./ caches: []notify: []strategy: retry: '0' - step: build@python name: build_python displayName: Python 构建 pythonVersion: '3.9' commands: - pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple - '# 可以使用pip下载依赖' - '# pip install --user -r requirements.txt' - python --version artifacts: - name: BUILD_ARTIFACT path: - ./ caches: []notify: []strategy: retry: '0' - step: build@golang name: build_golang displayName: Golang 构建 golangVersion: '1.12' commands: - '# 默认使用goproxy.cn' - export GOPROXY=https://goproxy.cn - '# 输入你的构建命令' - make build artifacts: - name: BUILD_ARTIFACT path: - ./output caches: - /go/pkg/mod notify: []strategy: retry: '0' - step: build@gradle name: build_gradle displayName: Gradle 构建 jdkVersion: '8' gradleVersion: '4.4' commands: - '# Gradle默认构建命令' - chmod +x ./gradlew - ./gradlew build artifacts: - name: BUILD_ARTIFACT path: - ./target caches: - ~/.gradle/caches notify: []strategy: retry: '0' - step: build@maven name: build_maven displayName: Maven 构建 jdkVersion: '8' mavenVersion: 3.3 .9 commands: - '# 功能:打包' - '# 参数说明:' - '# -Dmaven.test.skip=true:跳过单元测试' - '# -U:每次构建检查依赖更新,可避免缓存中快照版本依赖不更新问题,但会牺牲部分性能' - '# -e -X :打印调试信息,定位疑难构建问题时建议使用此参数构建' - '# -B:以batch模式运行,可避免日志打印时出现ArrayIndexOutOfBoundsException异常' - '# 使用场景:打包项目且不需要执行单元测试时使用' - mvn clean package -Dmaven.test.skip=true -U -e -X -B - '' - '# 功能:自定义settings配置' - '# 使用场景:如需手工指定settings.xml,可使用如下方式' - '# 注意事项:如无需自定义settings配置且需要私有依赖仓库,可在该任务配置《私有仓库》处添加私有依赖' - '# mvn -U clean package -s ./settings.xml' - '' artifacts: - name: BUILD_ARTIFACT path: - ./target settings: []caches: - ~/.m2 notify: []strategy: retry: '0' - step: build@nodejs name: build_nodejs displayName: Nodejs 构建 nodeVersion: 14.16 .0 commands: - '# 设置NPM源,提升安装速度' - npm config set registry https://registry.npmmirror.com - '' - '# 执行编译命令' - npm install && npm run build artifacts: - name: BUILD_ARTIFACT path: - ./dist caches: - ~/.npm - ~/.yarn notify: []strategy: retry: '0' - name: stage-ae79d813 displayName: 未命名 strategy: naturally trigger: auto executor: []steps: - step: ut@maven name: unit_test_maven displayName: Maven 单元测试 jdkVersion: '8' mavenVersion: 3.3 .9 commands: - '# Maven单元测试默认命令' - mvn -B test -Dmaven.test.failure.ignore=true - mvn surefire-report:report-only - mvn site -DgenerateReports=false report: path: ./target/site index: surefire-report.html checkpoints: []settings: []caches: - ~/.m2 notify: []strategy: retry: '0' - name: stage-374ffefd displayName: 未命名 strategy: naturally trigger: auto executor: []steps: - step: deploy@k8s name: deploy_k8s displayName: K8S部署 version: v1.16.4 certificate: '' namespace: default yaml: ./deployment.yaml isReplace: false skiptls: false params: null notify: []strategy: retry: '0'
代码实现
待解决的问题:
如何实现实时日志:发布订阅模式,与前端使用websocket方式,服务端与runner使用grpc。如何实现内置功能:不采用github actions 适配难点大、后期在考虑兼容。run-on的选择是针对整条流水线还是stage还是step,参考jenkins和github action。
一共三种粒度:
流水线级别的粒度:最粗粒度,无法满足在一条流水线中不同环境的step运行,如果需要不同环境只能新建流水线选择对应的机器环境。
stage级别的粒度:中等粒度,介于1、3之间两者的利弊都没有完全解决,不采用该方式。
step级别的粒度:最细粒度,可为每个step显示指定节点运行环境,能够精确把控每个step,会带来产物同步的高效性降低,因为只能通过OSS方式共享。
run-on的环境支持镜像和宿主机,如果在宿主机如何保证安全问题。
默认认为环境是安全的且构建机器不会存储任何秘钥
run-on运行环境选择机制:
不指定的话使用当前负载最低的节点运行Pipeline。
指定的话则根据指定的label来选择对应的机器。
支持三种环境运行step:
裸机运行
容器运行(默认)
自定义镜像运行
每个step需要做的工作:
运行前环境准备
运行用户输入的command
构建后产物存储
缓存构建
实时日志同步给客户端
日志服务 在执行任务过程中需要实时传输日志给前端进行展示,采用websocket方式进行实时传输(实时运行状态),如果是已经完成的
在执行命令时还需要读取 命令执行后返回的流数据进行回显
秘钥类型的数据使用 **** 来代替显示。
基于发布订阅模块进行日志传输。
Step 生命周期
实例化:根据 yaml 定义文件反序列化其到step配置实例。
前置准备:根据 yaml 定义的环境准备对应的执行环境,如主机、容器(默认为容器),注入环境变量和秘钥。
执行 step:根据 指定的step去执行特定操作、command等。
释放资源:释放容器和清理执行step过程中worksapce产生的内容。
存储结果:将执行结果状态、记录进行存储(人工卡点是需要进行介入的)。
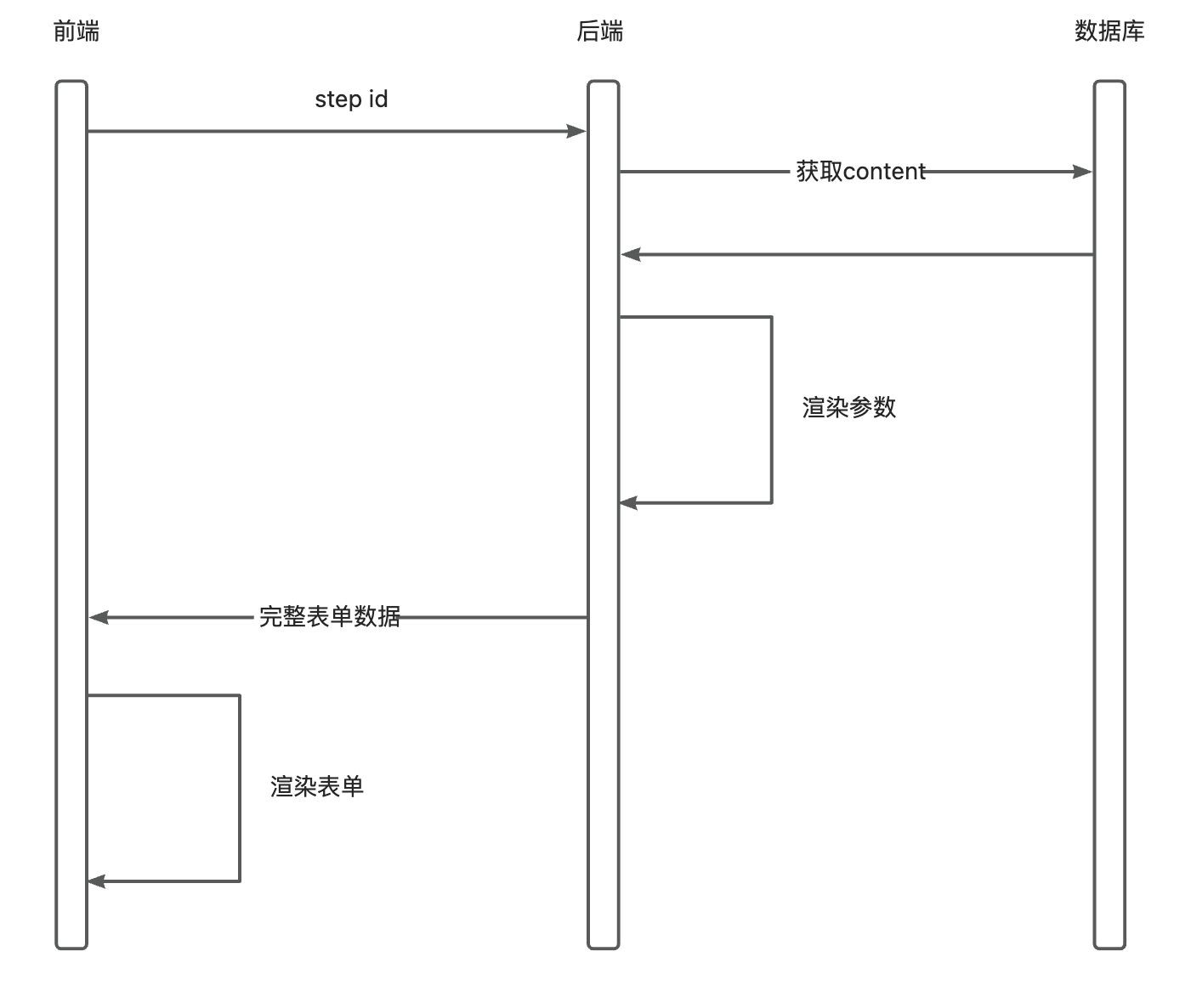
Step 可视化编辑 流程:
从后端获取step列表
选择 step 去后端请求 该 step 的表单配置(使用该step需要那些输入配置供前端进行展示),根据step的配置进行数据渲染(后端)再返回给前端
前端拿到step的配置后进行渲染表单
配置的定义:
该定义位于step的记录中(content字段)主要是记录使用该节点需要用户进行输入那些数据项,在用户进行选择该s
1 2 3 4 5 6 7 8 9 10 items: - name: desc: type: select rules: - require: true values: datasource: type: value
以golang构建为案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 fields: - name: golang-version label: Golang版本 desc: type: select rules: - require: true value: go1.20.4 datasource: type: value values: - label: go1.20.4(稳定版) value: go1.20.4 - label: go1.18.1 value: go1.18.1 - label: go1.16.6(稳定版) value: go1.16.6 - name: build-command label: 构建命令 desc: type: code value: | # 默认使用goproxy.cn export GOPROXY=https://goproxy.cn # 输入你的构建命令 make build rules: - require: false - name: build-artifacts label: 构建产物 desc: type: collapse spce: name: BUILD_ARTIFACT label: '暂存构建物添加' limit: 0 child: - name: name label: 构建物唯一标识 desc: 支持数字、字母、下划线等,最大32个字符,在下游可以通过${BUILD_ARTIFACT}方式引用来获取构建物 type: input rules: - require: true - name: path label: 构建物唯一标识 desc: 不限制字符格式,最大256个字符 type: input-rows rules: - require: true rules: - require: false runOn: random runWay: container notify: - certificate: a31b3cb0-4731-013c-aedc-4e84687c3eef events: - fail content: | pipeline ${name} run fail at ${time.Now()} strategy: retry: '5' timeout: 5 caches: - /go/pkg/mod
在可视化视图编辑时需要将表单数据进行转为yaml数据提交给服务器。
在切换图形视图和代码视图的tab中能将其数据进行转换。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 triggers: cron: 10 18 * * * webhook: true push: branch: include: - master - release - main precise: - dfgsd prefix: - dfgsd tag: commit:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 steps: - step: TASK_GO_BUILD_UPLOAD name: TASK_GO_BUILD_UPLOAD displayName: Golang 构建 golangVersion: '1.12' commands: - '# 默认使用goproxy.cn' - export GOPROXY=https://goproxy.cn - '# 输入你的构建命令' - make build artifacts: - name: BUILD_ARTIFACT path: - ./output caches: - /go/pkg/mod notify: - certificate: a31b3cb0-4731-013c-aedc-4e84687c3eef events: - fail content: - repository - pipeline - stage - task - operator - branch - detail type: dingtalk strategy: retry: '0'
1 2 3 4 artifacts: - name: BUILD_ARTIFACT path: - ./target
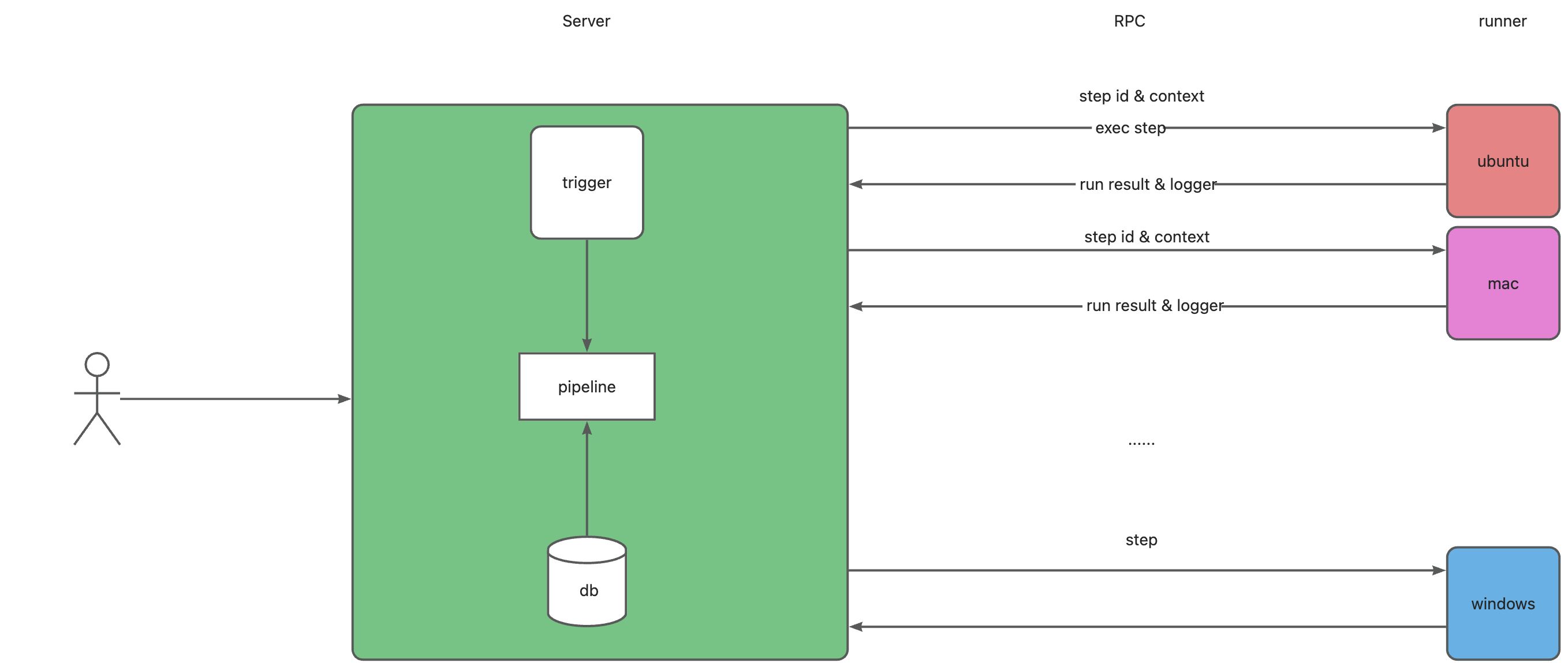
server server端负责进行pipeline基础管理,通过rpc通信派发流水线给runner进行执行,同时将日志从runner转发给前端和存储到日志中心。
runner runners 的设计原理主要包含以下几个方面:
基于客户端-服务器架构:Runner 作为客户端,连接到 devops-platform 服务端。客户端轮询请求服务器获取任务,然后在本地执行,并将结果返回给服务器。
用 Docker 隔离执行环境:Runner 在 Docker 容器内执行任务,实现了执行环境的隔离。默认的虚拟环境保证了每个步骤的一致性。
支持跨平台:Runner 支持 Linux、Windows 和 macOS,可以使工作流跨平台执行。
高度可扩展:Runner 支持横向扩展,可以根据需要增加运行实例的数量。
状态共享:Runner 和服务端通信可以共享状态,如工作流的当前进度。
事件驱动subtotal更新:Runner 将在配置发生变化时从服务端获取更新,确保工作流是最新的。
8.安全加密通信:Runner 和服务端之间的通信是通过安全的 TLS 加密的。
必填参数:
label用于server运行step时可选择节点。
启动可选参数:
服务端 Endpoint。
工作目录 workspace(部分任务需要在主机上运行)。
Docker API :https://docs.docker.com/engine/api/v1.43/
执行任务的详细流程
启动时对环境工具进行检查,必需工具链不存在不给予运行
缓存机制 部分step的运行可能每次需要下载很多依赖,例如 npm 的 node-module ,maven的jar文件等等,如果每次都重新下载的话效率低下,如果能将其进行缓存起来则可以加快构建的速度。
runner 选择算法
按照label选择runner。
同label下多个节点,选择负载最低的runner。
状态上报
定时向服务端上报当前runner的负载情况,健康状态等必要信息
images 基础镜像库,在运行job是依赖于一些基础工具链的,这些工具会被打包进镜像里面,如git、maven、golang等。
运行原理 容器方式运行 将当前step必备的组件通过-v进行挂载到容器中去,缓存的实现也是一样
日志实时读取
格式化日志(带上时间)
日志驱动
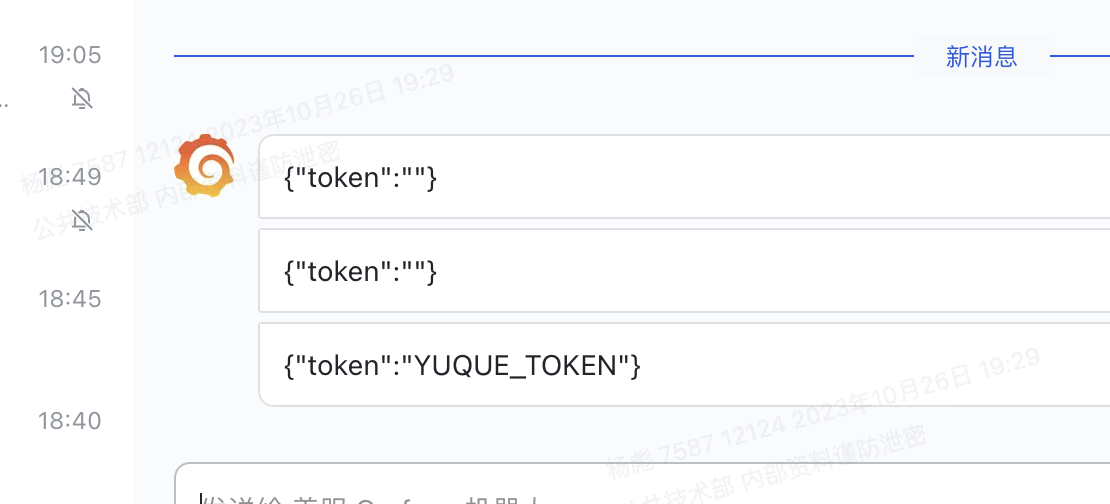
项目构建的时候需要拉取依赖(多个私服仓库依赖),如果是那种私服的仓库如何配置权限 ?
从代码源中获取配置的access token来访问但是这个token的权限级别特别高,存在用户破坏数据的可能性。
通过保存代码源的时候去创建一个仅仅带有只读权限的access token,在拉取代码的时候注入这个token,因为只有只读权限,还是比较安全的。
基于2如果还要更加精细的控制权限,可以拿到当前仓库用户的 access token(没有则创建)可以进一步进行管控。
gitee的实现方式
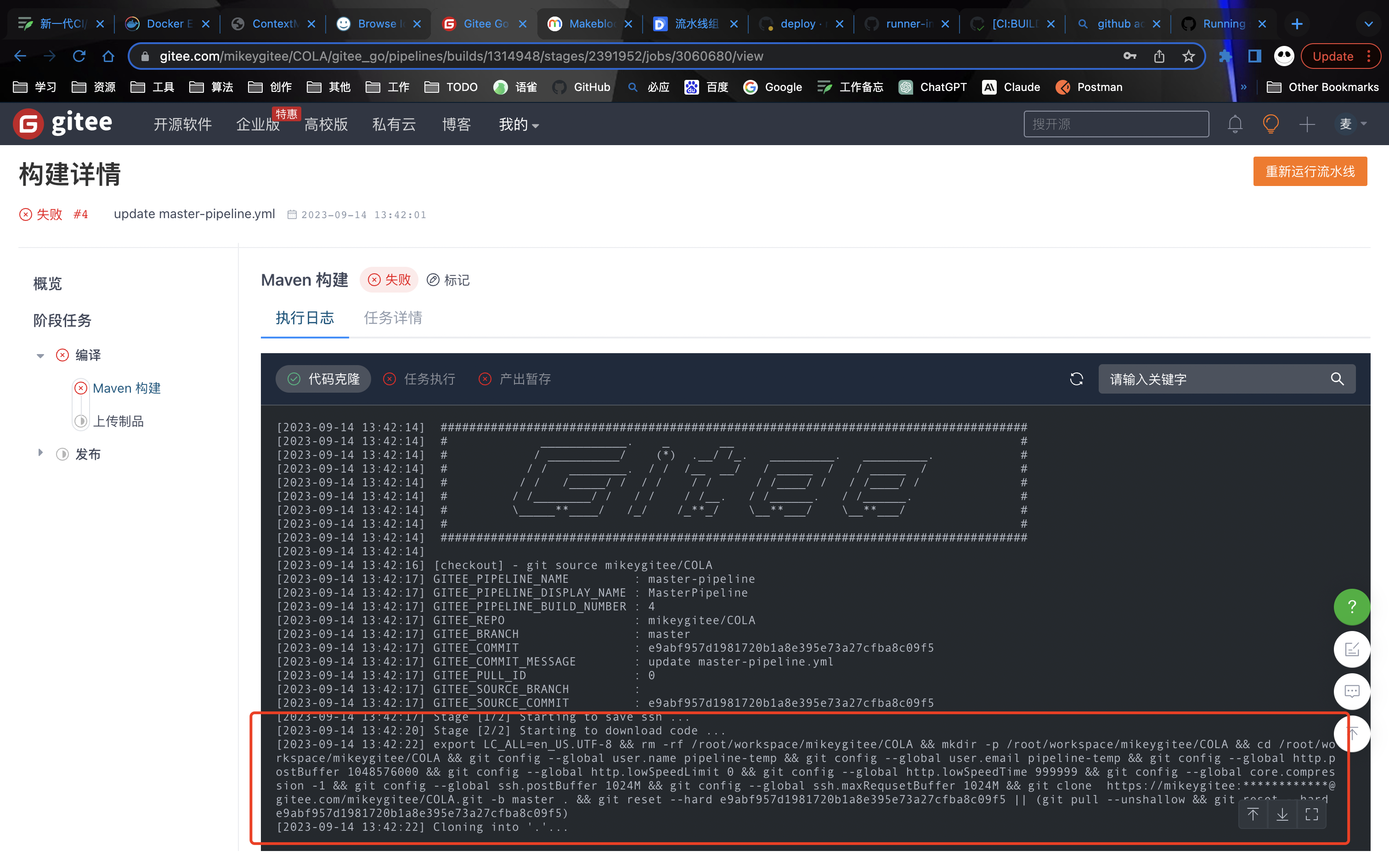
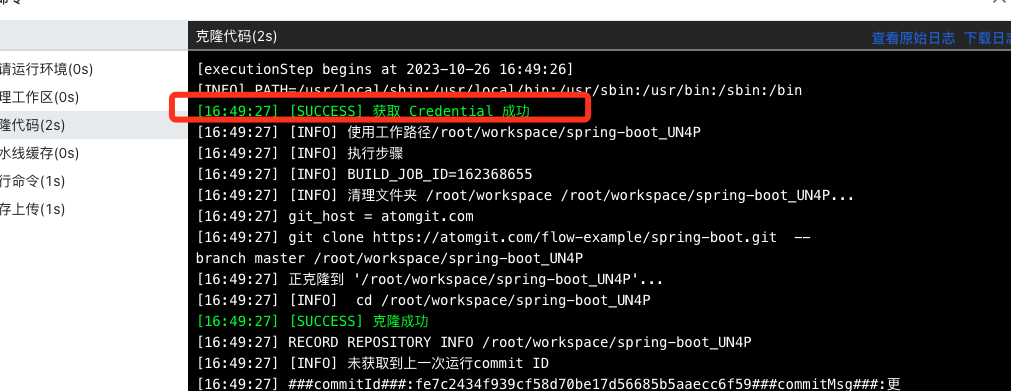
1 2 3 4 49] Stage [2/2] Starting to download code ... export LC_ALL=en_US.UTF-8 && rm -rf /root/workspace/mikeygitee/COLA && mkdir -p /root/workspace/mikeygitee/COLA && cd /root/workspace/mikeygitee/COLA && git config --global user.name pipeline-temp && git config --global user.email pipeline-temp && git config --global http.postBuffer 1048576000 && git config --global http.lowSpeedLimit 0 && git config --global http.lowSpeedTime 999999 && git config --global core.compression -1 && git config --global ssh.postBuffer 1024M && git config --global ssh.maxRequsetBuffer 1024M && git clone https://mikeygitee:************@gitee.com/mikeygitee/COLA.git -b master . && git reset --hard 0dc56d7eef08c9136f196a2bff3273fce83f4116 || (git pull --unshallow && git reset --hard 0dc56d7eef08c9136f196a2bff3273fce83f4116)'.' ...
上面的问题其实本质上就是credential的设计问题
秘钥模块设计
在脚本中能使用秘钥,但是打印出来的是 ‘******’
直接在控制台输出的日志进行过滤,如果存在则替换成 ‘******’,但是正在方式如果通过
github测试获取秘钥
可以拿到数据
实时证明,只是屏蔽掉返回给前端 秘钥 使用 ”****“ 代替
主机方式运行 主机运行方式可以通过对不同的step设置所需的环境变量来配置对应的工具版本
命令执行
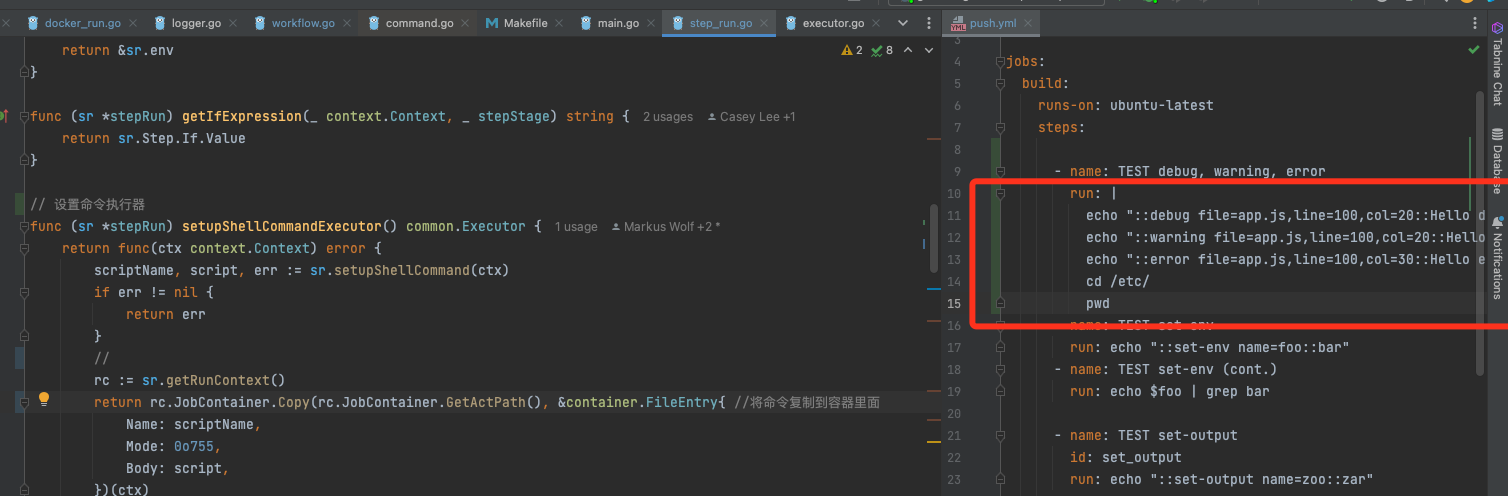
以act为例:
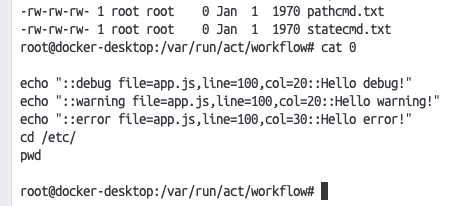
将命令直接复制到容器里面
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 BASH_FUNC_STEP_EXEC() {2 >&1 | tee -a /tmp/buildlog | while IFS= read -r line || [[ -n ${line} ]]; doif [[ ${line} = \+* ]]; then"\033[1;36m[$(date '+%H:%M:%S')] [User Command] $line\033[0m" else if [[ ${line} = \[ERROR\]* ]]; then"\u001b[91m[$(date '+%H:%M:%S')] $line\033[0m" else if [[ ${line} = \[WARNING\]* ]]; then"\u001b[33m[$(date '+%H:%M:%S')] $line\033[0m" else if [[ ${line} = \[SUCCESS\]* ]]; then"\u001b[92m[$(date '+%H:%M:%S')] $line\033[0m" else "[$(date '+%H:%M:%S')] $line" return ${PIPESTATUS[0 ]}
我们要的效果:
Action实现 Checkout Action
在主机模式下如何能做到不污染其他pipeline拉取
Exec Action 通信协议 https://docs.gitea.com/zh-cn/usage/actions/design
https://gitea.com/gitea/actions-proto-def/src/branch/main/proto
https://gitea.com/gitea/actions-proto-go/src/branch/main/runner/v1/messages.pb.go
落地
记录系统开发落地过程中的问题记录
mac下docker启动 Ubuntu
1 2 3 4 docker pull --platform=linux/amd64 ubuntu:20.04"interactive" 的简写,意味着即使没有附加到容器,仍保持STDIN开启。
安装 git、nvm
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 { "object_kind" : "push" , "event_name" : "push" , "before" : "2665aa7038cbf03f04fce0d33655cbe540ebbce9" , "after" : "777bde1a94d576320170b41dc7ff65d430ed4e33" , "ref" : "refs/heads/main" , "ref_protected" : true , "checkout_sha" : "777bde1a94d576320170b41dc7ff65d430ed4e33" , "message" : null , "user_id" : 59 , "user_name" : "yangbiao" , "user_username" : "yangbiao" , "user_email" : "" , "user_avatar" : "https://git.makeblock.com/uploads/-/system/user/avatar/59/avatar.png" , "project_id" : 833 , "project" : { "id" : 833 , "name" : "demo" , "description" : "用于测试创建应用" , "web_url" : "https://git.makeblock.com/makeblock-common/demo" , "avatar_url" : null , "git_ssh_url" : "git@git.makeblock.com:makeblock-common/demo.git" , "git_http_url" : "https://git.makeblock.com/makeblock-common/demo.git" , "namespace" : "Makeblock-common" , "visibility_level" : 0 , "path_with_namespace" : "makeblock-common/demo" , "default_branch" : "main" , "ci_config_path" : "" , "homepage" : "https://git.makeblock.com/makeblock-common/demo" , "url" : "git@git.makeblock.com:makeblock-common/demo.git" , "ssh_url" : "git@git.makeblock.com:makeblock-common/demo.git" , "http_url" : "https://git.makeblock.com/makeblock-common/demo.git" } , "commits" : [ { "id" : "777bde1a94d576320170b41dc7ff65d430ed4e33" , "message" : "feat: deploy\n" , "title" : "feat: deploy" , "timestamp" : "2023-09-01T11:27:36+08:00" , "url" : "https://git.makeblock.com/makeblock-common/demo/-/commit/777bde1a94d576320170b41dc7ff65d430ed4e33" , "author" : { "name" : "yangbiao" , "email" : "yangbiao@makeblock.com" } , "added" : [ ] , "modified" : [ "Makefile" ] , "removed" : [ ] } , { "id" : "cb7a65632d97b53dbba566607281215ab26146f5" , "message" : "feat: 适配生产环境发布\n" , "title" : "feat: 适配生产环境发布" , "timestamp" : "2023-08-31T16:59:28+08:00" , "url" : "https://git.makeblock.com/makeblock-common/demo/-/commit/cb7a65632d97b53dbba566607281215ab26146f5" , "author" : { "name" : "yangbiao" , "email" : "yangbiao@makeblock.com" } , "added" : [ ] , "modified" : [ "Jenkinsfile" ] , "removed" : [ ] } , { "id" : "2665aa7038cbf03f04fce0d33655cbe540ebbce9" , "message" : "feat: 适配生产环境发布\n" , "title" : "feat: 适配生产环境发布" , "timestamp" : "2023-08-31T16:53:22+08:00" , "url" : "https://git.makeblock.com/makeblock-common/demo/-/commit/2665aa7038cbf03f04fce0d33655cbe540ebbce9" , "author" : { "name" : "yangbiao" , "email" : "yangbiao@makeblock.com" } , "added" : [ ] , "modified" : [ "Jenkinsfile" ] , "removed" : [ ] } ] , "total_commits_count" : 3 , "push_options" : { } , "repository" : { "name" : "demo" , "url" : "git@git.makeblock.com:makeblock-common/demo.git" , "description" : "用于测试创建应用" , "homepage" : "https://git.makeblock.com/makeblock-common/demo" , "git_http_url" : "https://git.makeblock.com/makeblock-common/demo.git" , "git_ssh_url" : "git@git.makeblock.com:makeblock-common/demo.git" , "visibility_level" : 0 } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 { "object_kind" : "push" , "event_name" : "push" , "before" : "2665aa7038cbf03f04fce0d33655cbe540ebbce9" , "after" : "777bde1a94d576320170b41dc7ff65d430ed4e33" , "ref" : "refs/heads/main" , "ref_protected" : true , "checkout_sha" : "777bde1a94d576320170b41dc7ff65d430ed4e33" , "message" : null , "user_id" : 59 , "user_name" : "yangbiao" , "user_username" : "yangbiao" , "user_email" : "" , "user_avatar" : "https://git.makeblock.com/uploads/-/system/user/avatar/59/avatar.png" , "project_id" : 833 , "project" : { "id" : 833 , "name" : "demo" , "description" : "用于测试创建应用" , "web_url" : "https://git.makeblock.com/makeblock-common/demo" , "avatar_url" : null , "git_ssh_url" : "git@git.makeblock.com:makeblock-common/demo.git" , "git_http_url" : "https://git.makeblock.com/makeblock-common/demo.git" , "namespace" : "Makeblock-common" , "visibility_level" : 0 , "path_with_namespace" : "makeblock-common/demo" , "default_branch" : "main" , "ci_config_path" : "" , "homepage" : "https://git.makeblock.com/makeblock-common/demo" , "url" : "git@git.makeblock.com:makeblock-common/demo.git" , "ssh_url" : "git@git.makeblock.com:makeblock-common/demo.git" , "http_url" : "https://git.makeblock.com/makeblock-common/demo.git" } , "commits" : [ { "id" : "777bde1a94d576320170b41dc7ff65d430ed4e33" , "message" : "feat: deploy\n" , "title" : "feat: deploy" , "timestamp" : "2023-09-01T11:27:36+08:00" , "url" : "https://git.makeblock.com/makeblock-common/demo/-/commit/777bde1a94d576320170b41dc7ff65d430ed4e33" , "author" : { "name" : "yangbiao" , "email" : "yangbiao@makeblock.com" } , "added" : [ ] , "modified" : [ "Makefile" ] , "removed" : [ ] } , { "id" : "cb7a65632d97b53dbba566607281215ab26146f5" , "message" : "feat: 适配生产环境发布\n" , "title" : "feat: 适配生产环境发布" , "timestamp" : "2023-08-31T16:59:28+08:00" , "url" : "https://git.makeblock.com/makeblock-common/demo/-/commit/cb7a65632d97b53dbba566607281215ab26146f5" , "author" : { "name" : "yangbiao" , "email" : "yangbiao@makeblock.com" } , "added" : [ ] , "modified" : [ "Jenkinsfile" ] , "removed" : [ ] } , { "id" : "2665aa7038cbf03f04fce0d33655cbe540ebbce9" , "message" : "feat: 适配生产环境发布\n" , "title" : "feat: 适配生产环境发布" , "timestamp" : "2023-08-31T16:53:22+08:00" , "url" : "https://git.makeblock.com/makeblock-common/demo/-/commit/2665aa7038cbf03f04fce0d33655cbe540ebbce9" , "author" : { "name" : "yangbiao" , "email" : "yangbiao@makeblock.com" } , "added" : [ ] , "modified" : [ "Jenkinsfile" ] , "removed" : [ ] } ] , "total_commits_count" : 3 , "push_options" : { } , "repository" : { "name" : "demo" , "url" : "git@git.makeblock.com:makeblock-common/demo.git" , "description" : "用于测试创建应用" , "homepage" : "https://git.makeblock.com/makeblock-common/demo" , "git_http_url" : "https://git.makeblock.com/makeblock-common/demo.git" , "git_ssh_url" : "git@git.makeblock.com:makeblock-common/demo.git" , "visibility_level" : 0 } }
可以通过这种方式来实现表头
1 ENTRYPOINT ls buildkit-bollard.txt
step日志:
总共两种状态进行查询日志:1.任务运行中 2.任务已完成
step运行中:
1. 客户端获取当前step的执行日志group状态,发送 **执行记录uuid**+**step定位三件套 **到服务端,服务端返回该step的执行步骤group(日志组),前端进行展示。
2. 客户端获取具体的日志信息,点击具体的group再将其传递给后端进行获取实时的日志信息(第一次打开使用首个group去获取)
step运行已完成:
1. 获取的状态都是已经完成,无需缓存websocket,直接返回全部group的最终执行状态。
2. 客户端获取具体的日志信息,点击具体的group再将其传递给后端进行获取已经记录下的数据。
问题:
在哪里存储 action 呢 ?step 配置里 ?
actions 存储在 step 实现里,Action 作为 step更加细化的动作,step只是负责装配action,当step在runner启动时先将所有actions的状态回传给server
runner响应的信息类型
step执行action状态更新(成功、失败)
action日志(追加)
step执行结果数据(状态&数据)
如何确定代码源分支:
gitee/github是基于gitops将配置文件放到指定的分支的,也就是说一个分支一个Pipeline。
云效的方式是在任务编排的时候提供一个代码源的选择,指定分支。
先来看看需要在线上跑的场景
针对于toc项目一般都是线上环境是单个分支,比如说是release分支。
一下tob项目可能会多个线上版本(本质上不是线上是交付给B端的版本,但是开发环境是需要多个)
最好的方案是:
支持多个开发环境的部署
实现跳过/取消Step的方案
step可能处于的状态,因为前端控制只能是跳过已经在运行中的step,所以可以确定是处于”运行中状态”
跳过当前step直接执行下一个step,如果没有step直接结束当前row
使用context进行分发子context来维护各个执行路径,可以统一控制结束(中断)
在进行跳过和取消时需要注意并发取消的情况
实现人工卡点的方案
要求指定用户点击通过后才能继续往下执行
不能一直驻留内存占用资源和worker
实现方案:
在遇到人工卡点的step时先驻留内存一段时间(具体再定),当超过该时间时,将当前的Pipeline的状态进行持久化。
用户点击通过或者不通过时,先判断当前的pipelin是否驻留在内存中,如果在内存中则直接进行继续调度,如果不在说明Pipeline已经超时被挂起,需要从持久化的Pipeline中重新load到内存中进行执行。
在对人工卡点超时的情况下,进行存储状态到数据库需要保证:
可执行节点已经执行完成了,如果还有可执行节点正在执行中需要等待其执行完在进行持久化,那么如何判断可执行节点是否已经都执行完
1. 对waitGroup进行判断,如果剩下1则表示只剩当前这个”人工卡点“的节点未执行完,但是如果同一个stage存在多个”人工卡点“则不能使用这种方法判断了。
2. 在执行时遇到人工卡点的step、记录人工卡点的坐标和个数,当执行到人工卡点step时进行判断,如果当前只剩下人工卡点待执行且到达超时时间则直接进行存储。超时时间应该以最后一个人工卡点计算。
进阶设计:
可选触发人
触发人and/or的实现
已审批过的人disable掉审批按钮
失败策略的实现 1 2 // 快速失败:在同一stage中的并行任务一但有一个step失败其他也会停止执行
�
快速失败:当一个step执行失败时,通过context通知其他
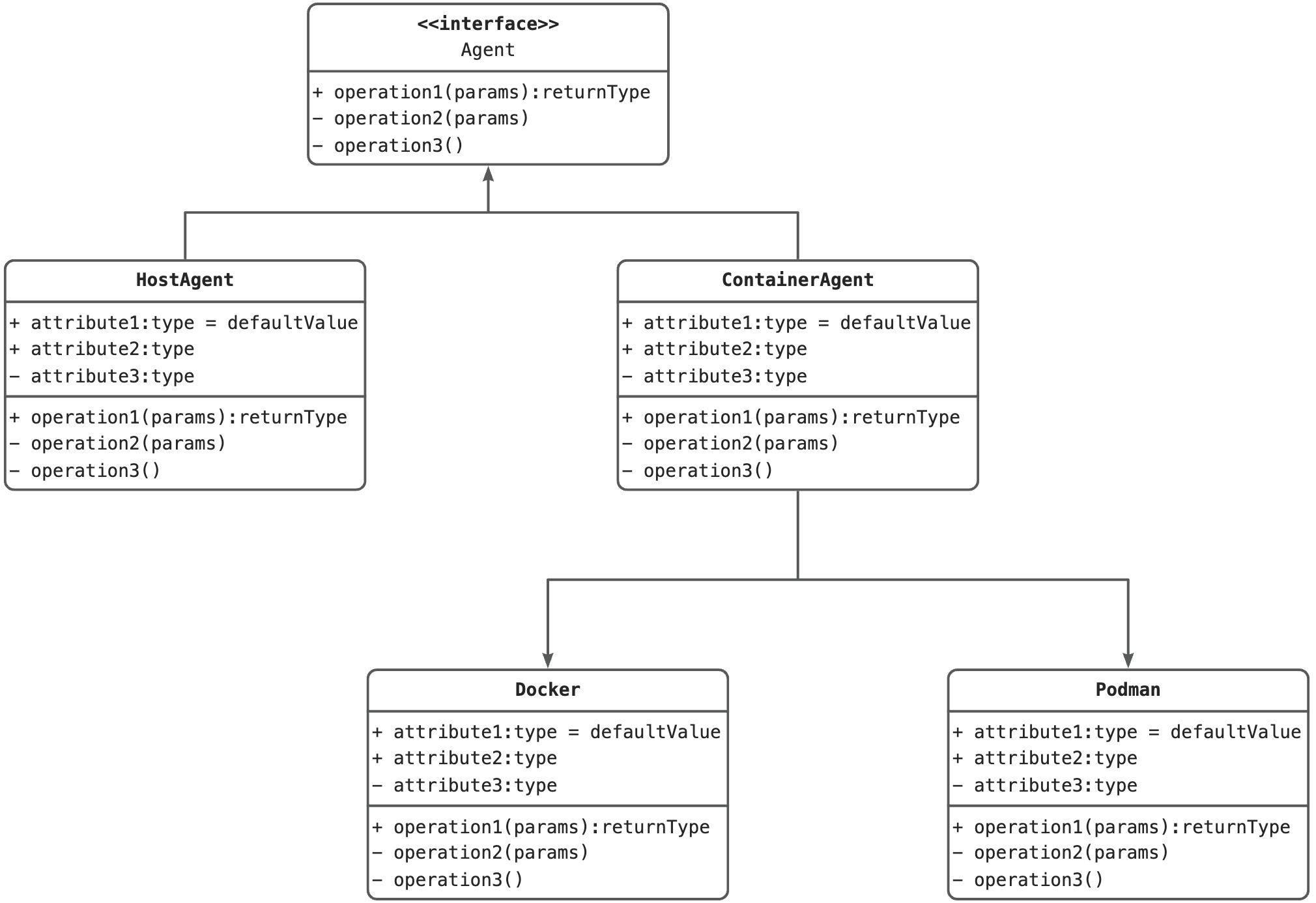
Agent的实现 因为需要支持主机运行和容器运行的工作方式,所以我们需要抽象一个Agent接口,下面由 HostAgent 和 containerAgent 来进行具体的实现
Agent 接口的能力
创建实例(工作空间、镜像容器)
拉取代码
EXEC
OSS上传构建产物
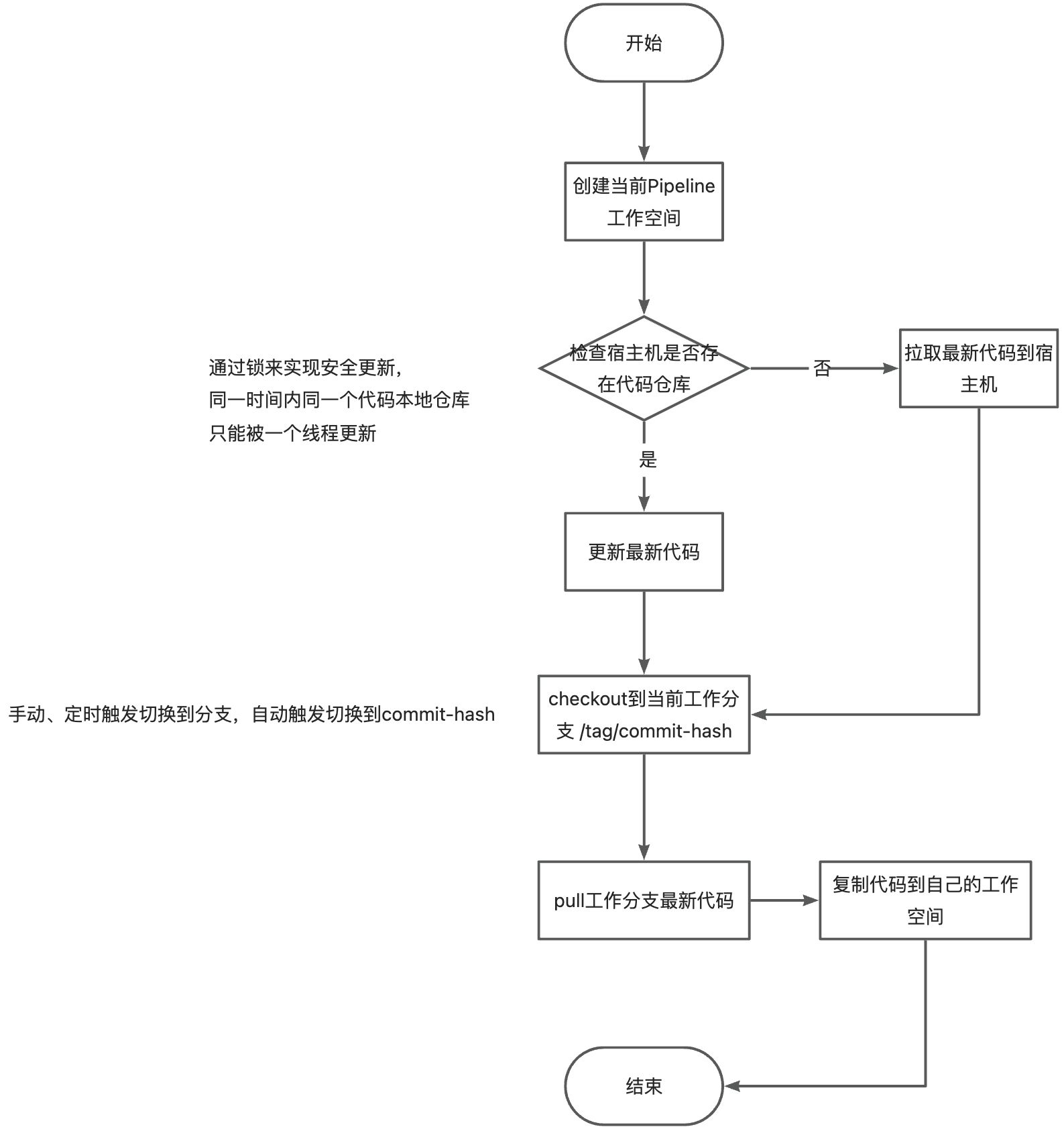
clone代码的实现
由于有的项目代码量比较大,如果每次都重新拉取代码会导致构建速度低下且做的是没有意义的操作,所以直接第一次构建后将代码在宿主机缓存起来,每当触发流水线时执行 pull & checkout commit id,无需每次都全量拉取文件。
如果是容器方式运行则将其挂载进容器中
并发执行问题:多个step同时在公用一个代码文件情况,各自checkout的commit id不一样,有可能在一个step执行过程中另一个就将其切换了。
每次执行pull后不直接使用该代码仓库文件,而是将其复制到自己的工作空间进行处理。
覆盖的流程
第一次拉取代码,
第 > 1 次拉取代码
镜像构建节点的设计 使用buildkit来进行构建镜像:https://github.com/moby/buildkit
创建容器设置容器镜像仓库的访问秘钥
将构建产物下载到容器工作目录下
调用buildkit打包镜像
推送到镜像仓库
是API控制构建还是 CTL ?
1 2 3 4 5 6 7 8 9 10 11 12 13 [17 :47 :39 ] [INFO] USER_REGISTRY=registry.cn-shenzhen.aliyuncs.com17 :47 :39 ] [INFO]镜像构建将使用 buildkit17 :47 :39 ] cp: ‘Dockerfile’ and ‘/root/workspace/spring-boot_If45/Dockerfile’ are the same file17 :47 :39 ] buildctl github.com/moby/buildkit v0.8 .0 73 fe4736135645a342abc7b587bba0994cccf0f917 :47 :39 ] [INFO] buildkit ready.17 :47 :39 ] docker login --username=18276297824 --password=****** registry.cn-shenzhen.aliyuncs.com17 :47 :39 ] WARNING! Using --password via the CLI is insecure. Use --password-stdin.17 :47 :39 ] WARNING! Your password will be stored unencrypted in /root/.docker/config.json.17 :47 :39 ] Configure a credential helper to remove this warning. See17 :47 :39 ] https:17 :47 :39 ] 17 :47 :39 ] Login Succeeded17 :47 :39 ] buildctl build --frontend dockerfile.v0 --local context=/root/workspace/spring-boot_If45 --local dockerfile=/root/workspace/spring-boot_If45 --output type =image,name=registry.cn-shenzhen.aliyuncs.com/mikey/app:2023 -12 -01 -17 -47 -19 ,push=true
docker buildx基本上支持buildctl的所有功能。Docker Buildx是Docker的一种新特性,它实际上是在buildctl基础上进行了扩展,提供了更多与Docker集成的功能。
使用BuildKit构建引擎,这是buildctl的核心特性。
支持在同一命令中构建多个平台的镜像,这是buildctl不具备的功能。
支持使用Dockerfile和Docker Compose文件进行构建,这也是buildctl不具备的功能。
提供了更丰富的输出格式选项,包括Docker镜像,本地文件系统,tar包等。
支持将构建缓存导出到远程存储,这是buildctl的一个重要特性。
Runner工作目录 //工作目录:
//workspace/txUUID/step/stepIdx/代码库(当前step的代码块)
//workspace/txUUID/代码库(当前pipeline的代码块,未受污染)
//workspace/txUUID/构建产物
下载构建物优先判断当前runner工作空间下是否已经存在,如果存在则直接复制到自己工作空间下使用,否则去OSS获取
如何清理pipeline工作空间呢?
�
Runner领域设计
私服代码依赖问题
一些二方包是存放在内部的git仓库中,在进行构建的时候需要有能正确的访问其资源,如:golang的二方包、java的maven仓库,npm仓库等等。需要提前设置这些资源的访问权限。
多任务并行在同一台runner上以主机的方式进行执行时,如果采用直接设置的方式,会相互影响。如:A项目设置了token=a然后去下载依赖,在A为完成时B任务启动设置了token=B然后去下载依赖,导致A出现异常,本质上其实就是环境不隔离产生的问题
解决方法:
针对 golang 应用,其二方包是直接在git仓库中,需要配置好访问代码仓库的权限才能进行 拉取依赖
1 2 3 git config --global url."https://${GIT_USERNAME}:${GIT_PASSWORD}@git.makeblock.com" .insteadOf "https://git.makeblock.com" "git@git.makeblock.com:" .insteadOf "https://git.makeblock.com/"
–local 和 –global 是 Git 命令中用于设置配置的选项,它们之间有以下区别:
–local:使用 –local 选项设置的配置仅对当前 Git 仓库有效。这意味着配置仅适用于当前项目,并且会保存在项目的 .git/config 文件中。其他项目不会受到影响,每个项目都可以有自己独立的配置。
–global:使用 –global 选项设置的配置对当前用户的所有 Git 仓库都有效。这意味着配置会保存在用户的全局配置文件中(通常是 ~/.gitconfig 或 %USERPROFILE%.gitconfig)。所有项目都会共享这些全局配置。
针对 npm 应用,只需要配置好registry地址即可,在发包时需要配置用户名和密码,这个凭证供用户进行选择
1 npm config set registry=http:
针对 Java 应用,其二方包一把发布在 maven 仓库中,但是访问需要配置好 setting.xml 文件(用户名密码访问endpoint等)
在项目中的settings.xml文件,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 <servers>{ MVN_USERNAME} </username>{ MVN_PASSWORD} </password>{ MVN_USERNAME} </username>{ MVN_PASSWORD} </password>true : :
在使用
1 mvn -B -U -s setting.xml install
参考:https://help.aliyun.com/document_detail/202386.html?spm=a2cl9.flow_devops2020_goldlog_detail.0.0.1a3324aeOGZ8TN
TODO
连接线上gitlab打通整套流程
是每个环境的部署一条流水线还是说是类似Jenkins每个应用一条流水线呢
一个应用单条流水线实现多环境的部署
管理简单,只需要维护一条流水线
实现逻辑复杂,需要在单条流水线中提供编辑每个stage、step的触发条件,运行时进行判断,
每次
一个应用多条流水线实现不同环境的部署
流程清晰,可以由不同的角色(如测试)进行控制不同的环境部署上线
单个应用流水线数量会比较多,(开发环境、测试环境、预发布环境、生产环境)
考虑多分支并行开发问题,这种粒度可以实现多分支环境部署
k8s配置文件存放问题
集中管理变更时容易,权限管控到位,但是如何在部署的时候获取呢,如何进行更新镜像版本部署呢
适配现有的环境进行传递如下参数
1 2 3 4 5 6 7 8 9 ENV_APP_NAME = d2v-service(可以通过app对象拿到)1.1 .6 (可以通过上传构建产物在后续节点package.json获取)4 a02ca48d527661cf76dd8f7b7fbaea6641532df(可以通过checkout对象拿到)
需要先使用 kustomize 进行镜像更新,再使用 kubectl 进行部署
如何传递参数给 部署的step 呢
通过构建产物输出
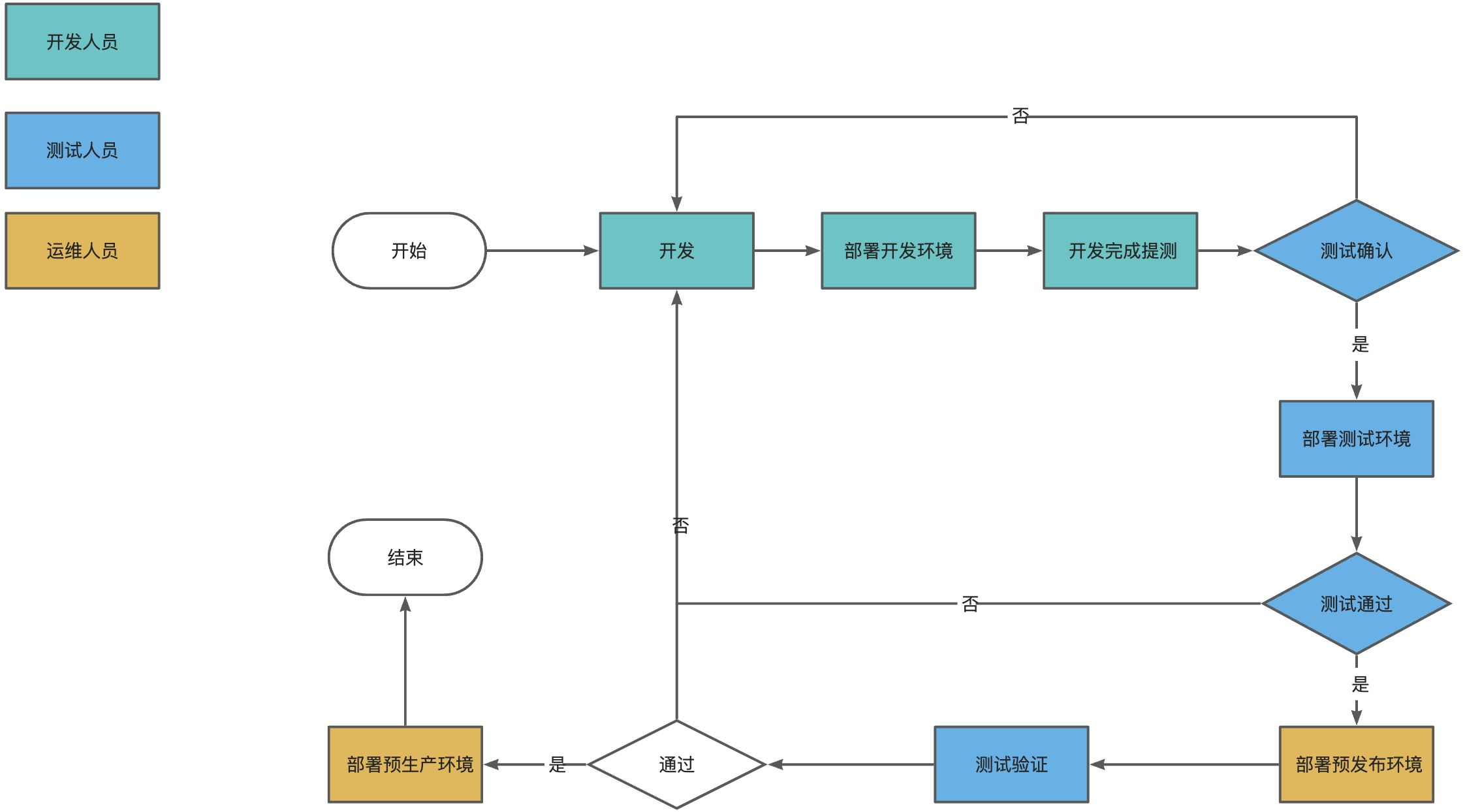
流程的规范化问题
开发环境:开发触发和执行
测试环境:开发触发,提供测试人员执行确认的功能(是否提测交由测试人员决定)
预发布环境:
生产环境:d
开发进行提测(比如类似现在的推送到release分支),测试进行确认通过,执行测试cicd流水线,
当流程稳定后,无需运维的介入,转变为
针对数据
资料
docker api :https://docs.docker.com/engine/api/v1.43/
act : https://github.com/nektos/act
github action runner:https://github.com/actions/runner
actions-runner-controller :https://github.com/actions/actions-runner-controller
https://github.com/actions/checkout