背景 防火墙这个名词相信我们都不陌生,在现实生活中我们在地下车库经常会看到下面这种防火卷帘门,这就是我们房子的防火墙(门),其作用是当发生火灾时隔绝火的蔓延,降低损失。
现实中的防火墙了解了,下面我们来了解了解计算机里的防火墙
计算机防火墙的概述 计算机防火墙用于保护计算机和网络免受来自互联网或局域网内部的未经授权的访问、攻击、病毒和恶意软件的侵害。防火墙通过监控网络流量,识别和过滤掉非法或有害的流量,从而防止未经授权的访问和攻击。它通常使用规则集来指定哪些流量应该允许通过,哪些流量应该被阻止或拒绝,以及如何响应不同类型的攻击和安全事件。
防火墙的主要功能包括:
包过滤:基于IP地址、端口号、协议类型等特定信息,过滤不符合规则的数据包。
状态检测:对进出网络的连接状态进行检测,以防止恶意攻击。
NAT(网络地址转换):将私有IP地址转换为公网IP地址,保护内网不受外部攻击。
VPN(虚拟专用网络)支持:为远程用户提供安全的访问方式。
审计日志:记录网络流量和安全事件,以便后续分析和调查。
为什么需要防火墙
保护网络安全:随着互联网的发展和普及,网络攻击和病毒传播的风险也越来越高。防火墙可以帮助企业和个人用户保护网络安全,避免遭受网络攻击和病毒感染,从而确保业务和个人信息的安全性。
控制网络访问:防火墙可以对网络流量进行监控和控制,根据特定的规则来允许或拒绝不同来源的流量,防止未经授权的访问和攻击。
网络隔离:防火墙可以将网络分割为不同的安全区域,从而限制内部和外部网络之间的数据交换。这有助于防止内部网络的机密数据被未经授权的用户访问和泄露。
提高网络性能:防火墙可以过滤掉无用的流量和恶意流量,从而减少网络拥塞和传输延迟,提高网络性能和稳定性。
防火墙的分类 防火墙可以分为软件防火墙 和硬件防火墙 。软件防火墙运行在操作系统内部,通常作为软件程序安装在计算机上。硬件防火墙是一种独立设备,通常放置在网络边缘或网关位置,用于过滤网络流量和提供更高级别的安全保护。
根据不同的分类标准,防火墙可以分为以下几种类型:
包过滤型防火墙:包过滤型防火墙是最早的防火墙类型,它基于网络层(OSI模型中的第三层)对数据包进行过滤和控制,通过过滤不合法的数据包来阻止未授权的访问和攻击。包过滤型防火墙可以基于源地址、目标地址、端口号、协议类型等特定信息来判断是否允许数据包通过,但它无法检测应用层的攻击和恶意软件。
应用层防火墙:应用层防火墙是基于应用层(OSI模型中的第七层)对数据流进行过滤和控制的防火墙类型。它可以识别和过滤掉应用层的攻击和恶意流量,如SQL注入、跨站点脚本(XSS)等,从而提高网络的安全性。
状态检测型防火墙:状态检测型防火墙是基于连接状态对数据流进行检测和控制的防火墙类型。它可以识别并防止来自已建立连接的恶意流量和攻击,从而提高网络的安全性和性能。
混合型防火墙:混合型防火墙将包过滤型防火墙、应用层防火墙和状态检测型防火墙相结合,综合了它们的优点,可以提供更全面的安全保护和网络性能优化。
下一代防火墙:下一代防火墙(NGFW)是基于深度包检测技术的新一代防火墙,可以识别和过滤掉更复杂的攻击和恶意流量,如嵌入式恶意软件、高级持续性威胁(APTs)等,从而提供更全面和高效的网络安全保护。同时,NGFW还支持网络入侵检测和防御(NIDS)和虚拟专用网络(VPN)等功能。
linux下的防火墙 Linux下的防火墙有很多种,些常见的有:
iptables:iptables是Linux中最常用的防火墙程序之一,它基于内核层面实现,可以对数据包进行过滤、转发和修改,同时支持多种网络协议和表达式,具有灵活性和高效性。
nftables:nftables是iptables的继任者,它提供了更强大的规则语言和数据结构,同时支持多种网络协议和表达式,可以更精确地控制和管理网络流量。
firewalld:firewalld是Red Hat和CentOS中预安装的防火墙程序,它基于iptables和nftables,提供了基于服务、区域和接口的防火墙规则管理,可以更加简单和安全地配置和管理防火墙。
ufw:ufw是Ubuntu中预安装的简单防火墙程序,它基于iptables,提供了易于使用的命令行界面,可以轻松地配置和管理基本的防火墙规则。
Shorewall:Shorewall是一个高级的防火墙管理程序,它基于iptables和nftables,提供了多种规则和策略,可以实现灵活的网络流量控制和安全保护。
防火墙的工作原理 防火墙的主要工作原理是通过策略和规则来过滤和控制网络流量,从而防止未授权的访问和攻击。其具体工作过程如下:
流量过滤:防火墙会监视网络流量,并将数据包与预定义的安全策略进行比较,根据规则对数据包进行过滤和分类,如允许、拒绝或转发。
策略管理:防火墙管理员可以定义和管理防火墙策略,包括源和目标IP地址、端口号、协议类型等,以及允许或拒绝流量的规则。
状态管理:防火墙会维护一个状态表来跟踪已建立的连接状态,并根据规则检测和拦截恶意流量和攻击。
NAT和端口转发:防火墙还可以支持网络地址转换(NAT)和端口转发等功能,以实现内部和外部网络之间的通信。
日志和报告:防火墙还可以生成日志和报告,记录网络流量和事件,以便管理员对网络安全进行跟踪和分析。
Iptables 简单介绍 iptables是Linux操作系统上的一种软件工具,用于管理网络中的数据包流动,通过检查每个数据包并根据定义的规则执行相应的操作来控制网络流量。
基本用法 查看当前iptables规则:可以使用以下命令来查看当前iptables规则:
清除当前iptables规则:可以使用以下命令来清除当前iptables规则:
设置iptables规则:可以使用以下命令来设置iptables规则,其中-A表示添加规则,-p表示协议,--dport表示目标端口,-j表示动作,ACCEPT表示接受,DROP表示丢弃:
1 2 3 iptables -A INPUT -p tcp --dport 80 -j ACCEPT
保存iptables规则:可以使用以下命令将当前iptables规则保存到文件中:
1 iptables-save > /etc/sysconfig/iptables
加载iptables规则:可以使用以下命令将保存的iptables规则加载到系统中:
1 iptables-restore < /etc/sysconfig/iptables
删除iptables规则:可以使用以下命令删除指定的iptables规则,其中-D表示删除规则,INPUT表示链名,1表示规则序号:
修改iptables规则:可以使用以下命令修改指定的iptables规则,其中-R表示替换规则,INPUT表示链名,1表示规则序号,-p表示协议,--dport表示目标端口,-j表示动作,ACCEPT表示接受:
1 iptables -R INPUT 1 -p tcp --dport 80 -j ACCEPT
暂停iptables规则:可以使用以下命令暂停iptables规则,其中-F表示清空所有规则,-X表示删除所有用户自定义链,-Z表示重置所有计数器:
1 2 3 4 r
禁用iptables规则:可以使用以下命令禁用iptables规则,其中-P表示设置默认策略,INPUT表示链名,DROP表示默认动作:
允许回环网络:可以使用以下命令允许回环网络,其中-A表示添加规则,INPUT表示链名,-i表示输入接口,lo表示回环接口,-j表示动作,ACCEPT表示接受:
1 iptables -A INPUT -i lo -j ACCEPT
限制IP地址范围:可以使用以下命令限制IP地址范围,其中-A表示添加规则,INPUT表示链名,-s表示源地址,192.168.0.0/24表示IP地址范围,-j表示动作,DROP表示丢弃:
1 iptables -A INPUT -s 192.168.0.0/24 -j DROP
限制连接数:可以使用以下命令限制连接数,其中-A表示添加规则,INPUT表示链名,-p表示协议,--syn表示只匹配SYN数据包,-m connlimit表示连接数限制模块,--connlimit-above表示连接数超过指定值,3表示连接数上限,-j表示动作,DROP表示丢弃:
1 iptables -A INPUT -p tcp --syn -m connlimit --connlimit-above 3 -j DROP
限制连接速率:可以使用以下命令限制连接速率,其中-A表示添加规则,INPUT表示链名,-p表示协议,--dport表示目标端口,-m limit表示速率限制模块,--limit表示速率上限,10/s表示每秒最多允许10个连接,-j表示动作,ACCEPT表示接受:
1 iptables -A INPUT -p tcp --dport 80 -m limit --limit 10/s -j ACCEPT
使用用户自定义链:可以使用以下命令创建用户自定义链,其中-N表示创建链,LOGDROP表示链名:
然后可以在该链中添加规则,最后将该链添加到INPUT链中:
1 2 3 iptables -A LOGDROP -j LOG --log-prefix "Dropped by LOGDROP: "
这样,当INPUT链中的规则匹配到该链时,将跳转到LOGDROP链中执行相应的规则,从而实现用户自定义的功能。
使用iptables防DDoS攻击:可以使用以下命令限制每个IP地址的连接数和速率,从而防止DDoS攻击:
1 2 3 4 iptables -N DDoS
以上命令将创建一个名为DDoS的用户自定义链,用于限制每个IP地址在60秒内最多只能发起50个新连接。如果超过了这个限制,将被DROP动作丢弃。最后将该链添加到INPUT链中。
保存和恢复规则:可以使用以下命令保存和恢复iptables规则,其中-L表示列出规则,-n表示不解析IP地址和端口号,> rules表示将规则保存到文件中,< rules表示从文件中恢复规则:
保存规则:
恢复规则:
1 iptables-restore < rules
清除规则:可以使用以下命令清除iptables规则,其中-F表示清空所有规则,-X表示删除所有用户自定义链,-Z表示将所有计数器归零:
1 2 3 iptables -F
永久保存规则:可以使用以下命令将当前规则保存到永久规则中,以便重启后仍然有效,其中iptables-save命令用于保存规则,iptables-restore命令用于恢复规则:
1 2 iptables-save > /etc/sysconfig/iptables
配置端口转发:可以使用以下命令配置端口转发,其中-t nat表示使用NAT表,-A PREROUTING表示添加PREROUTING链规则,-i eth0表示进入网络接口,--dport 80表示目标端口,-j DNAT表示目标地址转换,--to-destination 192.168.0.2:80表示目标IP地址和端口:
1 iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 80 -j DNAT --to-destination 192.168.0.2:80
配置源地址转换:可以使用以下命令配置源地址转换,其中-t nat表示使用NAT表,-A POSTROUTING表示添加POSTROUTING链规则,-s 192.168.0.0/24表示源地址,-o eth0表示出去网络接口,-j MASQUERADE表示地址伪装:
1 iptables -t nat -A POSTROUTING -s 192.168.0.0/24 -o eth0 -j MASQUERADE
配置多网卡负载均衡:可以使用以下命令配置多网卡负载均衡,其中-t mangle表示使用MANGLE表,-A PREROUTING表示添加PREROUTING链规则,-i eth0表示进入网络接口,-j MARK表示标记数据包,--set-mark 1表示标记为1,-A PREROUTING表示添加PREROUTING链规则,-i eth1表示进入网络接口,-j MARK表示标记数据包,--set-mark 2表示标记为2,-t nat表示使用NAT表,-A POSTROUTING表示添加POSTROUTING链规则,-o eth0表示出去网络接口,-j SNAT表示源地址转换,--to-source 192.168.0.2表示目标IP地址:
1 2 3 4 iptables -t mangle -A PREROUTING -i eth0 -j MARK --set-mark 1
配置DDoS防护:可以使用以下命令配置DDoS防护,其中-A INPUT表示添加INPUT链规则,-p tcp表示传输层协议为TCP,-m connlimit --connlimit-above 20表示连接数超过20个,--connlimit-mask 32表示对所有源地址生效,-j DROP表示丢弃数据包:
1 iptables -A INPUT -p tcp -m connlimit --connlimit-above 20 --connlimit-mask 32 -j DROP
配置SSH远程访问:可以使用以下命令配置SSH远程访问,其中-A INPUT表示添加INPUT链规则,-p tcp表示传输层协议为TCP,--dport 22表示目标端口为22,-j ACCEPT表示允许数据包通过:
1 iptables -A INPUT -p tcp --dport 22 -j ACCEPT
配置HTTP访问控制:可以使用以下命令配置HTTP访问控制,其中-A INPUT表示添加INPUT链规则,-p tcp表示传输层协议为TCP,--dport 80表示目标端口为80,-m state --state NEW表示只允许新连接,-m limit --limit 100/minute --limit-burst 100表示限制每分钟连接数为100个,-j ACCEPT表示允许数据包通过:
1 iptables -A INPUT -p tcp --dport 80 -m state --state NEW -m limit --limit 100/minute --limit-burst 100 -j ACCEPT
配置反向代理:可以使用以下命令配置反向代理,其中-t nat表示使用NAT表,-A PREROUTING表示添加PREROUTING链规则,-p tcp表示传输层协议为TCP,--dport 80表示目标端口为80,-j REDIRECT --to-port 8080表示将数据包重定向到端口8080:
1 iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-port 8080
工作原理 工作原理如下:
首先,iptables检查接收到的每个数据包,以查看其目标地址和端口号是否与已定义的规则匹配。
如果数据包匹配了规则,则iptables将根据规则定义的操作执行相应的动作,例如允许或阻止数据包。
如果数据包未匹配任何规则,则iptables将采取默认操作。默认操作通常是允许或拒绝数据包。
在iptables中,规则由规则链组成,每个规则链都是一系列规则的集合。规则链可以是系统预定义的,也可以是用户定义的。
当数据包到达系统时,它将通过规则链顺序进行匹配,直到找到匹配的规则。如果没有匹配的规则,则使用默认规则。
iptables还支持网络地址转换(NAT)和端口地址转换(PAT)。NAT和PAT可以在不更改数据包内容的情况下修改数据包的源地址和目标地址。
Netfilter框架 一个通用的、抽象的框架,提供一整套的hook函数的管理机制,使得诸如数据包过滤、网络地址转换(NAT)和基于协议类型的连接跟踪成为了可能。Netfilter 是一个由Linux 内核提供的框架,可以进行多种网络相关的自定义操作。
Netfilter 负责在内核中执行各种挂接的规则,运行在内核模式中;而 iptables 是在用户模式下运行的进程,负责协助和维护内核中 Netfilter 的各种规则表 。二者相互配合来实现整个 Linux 网络协议栈中灵活的数据包处理机制。
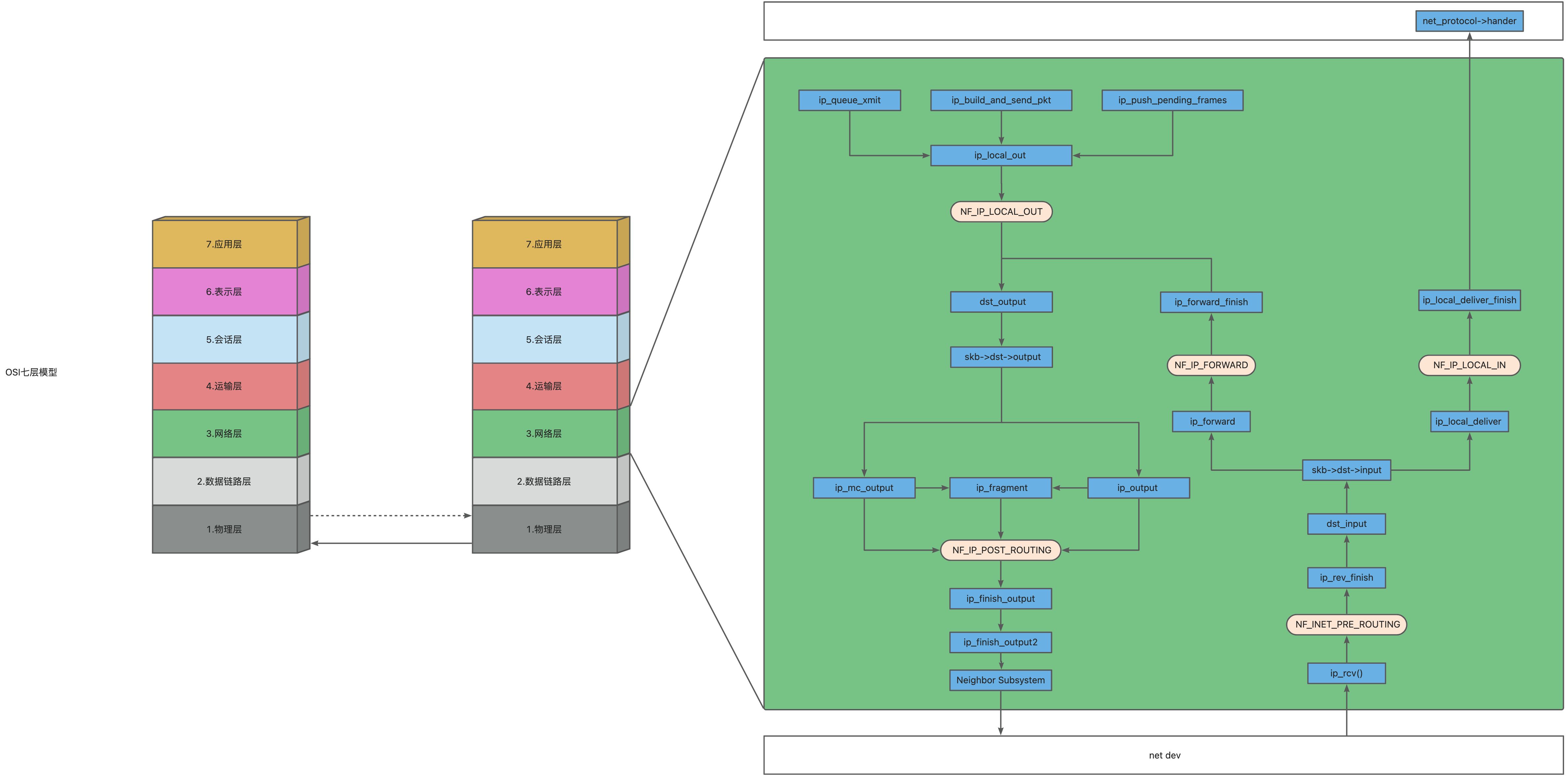
调用链路 iptables 的钩子分为五个阶段:PREROUTING、INPUT、FORWARD、OUTPUT 和 POSTROUTING
1 2 3 4 5 6 7 static const char *const hooknames[] = {"PREROUTING" ,"INPUT" ,"FORWARD" ,"OUTPUT" ,"POSTROUTING" ,
PREROUTING 链:在数据包到达本机之前,内核会先进入 PREROUTING 链,可以对数据包的目的地地址进行修改或重定向。在这个阶段可以做 DNAT(目标地址转换),例如将外网访问本机的 IP 地址转换为内网机器的 IP 地址,实现端口映射等功能。
INPUT 链:在数据包到达本机之后,内核会进入 INPUT 链,可以对数据包进行进一步的处理和过滤。在这个阶段可以进行数据包的过滤、连接追踪、一些协议处理等。
FORWARD 链:当数据包不是本机的目的地地址时,内核会进入 FORWARD 链,可以对数据包进行转发。在这个阶段可以对数据包进行路由、过滤等处理。
OUTPUT 链:在数据包从本机出去之前,内核会进入 OUTPUT 链,可以对数据包进行修改或重定向。在这个阶段可以做 SNAT(源地址转换),例如将本机的 IP 地址转换为另一个 IP 地址,实现 IP 地址伪装等功能。
POSTROUTING 链:在数据包从本机出去之后,内核会进入 POSTROUTING 链,可以对数据包的源地址进行修改或重定向。在这个阶段可以做 SNAT(源地址转换)、MASQUERADE(伪装网关地址)、一些连接追踪等。
从ip_rcv()函数开始分析iptables处理数据包的过程:
ip_rcv()函数:接收数据包,然后交给网络层进行处理。
ip_local_deliver_finish()函数:处理数据包的协议头,根据目标IP地址找到对应的网络设备,并将数据包发送到数据链路层进行发送。
nf_hook_slow()函数:iptables将hook函数注册到内核的网络层中,当数据包经过相应的处理阶段时,hook函数将被调用。
nf_iterate()函数:当数据包经过hook函数时,内核将调用nf_iterate()函数来依次执行所有注册到该hook的iptables规则。
do_builtin_nf_hook()函数:nf_iterate()函数会根据iptables规则中的匹配条件和动作来执行相应的操作,其中一部分规则是内置的iptables规则,这些规则由do_builtin_nf_hook()函数来执行。
ip_local_out()函数:当数据包需要从本地计算机发送到网络上时,iptables将通过OUTPUT链来处理数据包。在OUTPUT链中,数据包会经过ip_local_out()函数进行处理,该函数会将数据包发送到数据链路层进行发送。
ip_forward()函数:当数据包需要转发到其他计算机时,iptables将通过FORWARD链来处理数据包。在FORWARD链中,数据包会经过ip_forward()函数进行处理,该函数会进行路由选择,并将数据包转发到目标网络设备的数据链路层进行发送。
ip_output()函数:在数据包经过iptables的处理后,会进入内核的网络层进行进一步的处理,ip_output()函数会负责将数据包发送到数据链路层进行发送。
ip_rcv
ip_rcv接收数据函数
1 2 3 4 5 6 7 8 9 10 int ip_rcv (struct sk_buff *skb, struct net_device *dev, struct packet_type *pt,struct net_device *orig_dev) {struct net *net =if (skb == NULL )return NET_RX_DROP;return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING,net, NULL , skb, dev, NULL ,ip_rcv_finish);
1.1 处理IP 数据包
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 static struct sk_buff *ip_rcv_core (struct sk_buff *skb, struct net *net) {const struct iphdr *iph ;int drop_reason;if (skb->pkt_type == PACKET_OTHERHOST) {goto drop;if (!skb) {goto out;if (!pskb_may_pull(skb, sizeof (struct iphdr)))goto inhdr_error;if (iph->ihl < 5 || iph->version != 4 )goto inhdr_error;max_t (unsigned short , 1 , skb_shinfo(skb)->gso_segs));if (!pskb_may_pull(skb, iph->ihl*4 ))goto inhdr_error;if (unlikely(ip_fast_csum((u8 *)iph, iph->ihl)))goto csum_error;if (skb->len < len) {goto drop;else if (len < (iph->ihl*4 ))goto inhdr_error;if (pskb_trim_rcsum(skb, len)) {goto drop;4 ;memset (IPCB(skb), 0 , sizeof (struct inet_skb_parm));if (!skb_sk_is_prefetched(skb))return skb;if (drop_reason == SKB_DROP_REASON_NOT_SPECIFIED)return NULL ;
1.2 触发 NF_INET_PRE_ROUTING 钩子通过后 执行 ip_rcv_finish
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 static int ip_rcv_finish (struct net *net, struct sock *sk, struct sk_buff *skb) struct net_device *dev =int ret;if (!skb)return NET_RX_SUCCESS;NULL );if (ret != NET_RX_DROP)return ret;
1.3 调用 ip_rcv_finish_core 处理数据报同时解析路由
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 static int ip_rcv_finish_core (struct net *net, struct sock *sk,struct sk_buff *skb, struct net_device *dev,const struct sk_buff *hint) const struct iphdr *iph =int err, drop_reason;struct rtable *rt ;if (ip_can_use_hint(skb, iph, hint)) {if (unlikely(err))goto drop_error;if (READ_ONCE(net->ipv4.sysctl_ip_early_demux) &&switch (iph->protocol) {case IPPROTO_TCP:if (READ_ONCE(net->ipv4.sysctl_tcp_early_demux)) {break ;case IPPROTO_UDP:if (READ_ONCE(net->ipv4.sysctl_udp_early_demux)) {if (unlikely(err))goto drop_error;break ;if (!skb_valid_dst(skb)) {if (unlikely(err))goto drop_error;else {struct in_device *in_dev = __in_dev_get_rcu(dev);if (in_dev && IN_DEV_ORCONF(in_dev, NOPOLICY))#ifdef CONFIG_IP_ROUTE_CLASSID if (unlikely(skb_dst(skb)->tclassid)) {struct ip_rt_acct *st =0xFF ].o_packets++;0xFF ].o_bytes += skb->len;16 )&0xFF ].i_packets++;16 )&0xFF ].i_bytes += skb->len;#endif if (iph->ihl > 5 && ip_rcv_options(skb, dev))goto drop;if (rt->rt_type == RTN_MULTICAST) {else if (rt->rt_type == RTN_BROADCAST) {else if (skb->pkt_type == PACKET_BROADCAST ||struct in_device *in_dev = __in_dev_get_rcu(dev);if (in_dev &&goto drop;return NET_RX_SUCCESS;return NET_RX_DROP;if (err == -EXDEV) {goto drop;
通过查询路由表,查找目标 IP 地址的下一跳地址,并返回对应的输入接口。�
1 2 3 4 5 6 7 8 9 10 11 12 int ip_route_input_noref (struct sk_buff *skb, __be32 daddr, __be32 saddr,u8 tos, struct net_device *dev) struct fib_result res ;int err;return err;
调用链路
1 2 3 4 5 6 ip_route_input_noref
ip_local_deliver 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int ip_local_deliver (struct sk_buff *skb) {struct net *net =if (ip_is_fragment(ip_hdr(skb))) {if (ip_defrag(net, skb, IP_DEFRAG_LOCAL_DELIVER))return 0 ;return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN,net, NULL , skb, skb->dev, NULL ,ip_local_deliver_finish);
进行加锁读取ip_protocol_deliver_rcu
1 2 3 4 5 6 7 8 9 10 11 static int ip_local_deliver_finish (struct net *net, struct sock *sk, struct sk_buff *skb) return 0 ;
主要是负责将收到的 IP 数据包提交给对应的传输层协议处理,以便进行进一步的分发和处理。该函数会首先调用 raw_local_deliver 函数进行本地处理,然后根据 IP 协议号找到对应的协议处理函数,并使用 INDIRECT_CALL_2 宏调用对应的处理函数处理数据包。处理完成后,函数会更新 IP 统计信息。如果没有找到对应的协议处理函数,则会将数据包丢弃,并发送 ICMP 错误消息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 void ip_protocol_deliver_rcu (struct net *net, struct sk_buff *skb, int protocol) const struct net_protocol *ipprot ;int raw, ret;if (ipprot) {if (!ipprot->no_policy) {if (!xfrm4_policy_check(NULL , XFRM_POLICY_IN, skb)) {return ;if (ret < 0 ) {goto resubmit;else {if (!raw) {if (xfrm4_policy_check(NULL , XFRM_POLICY_IN, skb)) {0 );else {
ip_forward 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 int ip_forward (struct sk_buff *skb) return NF_HOOK(NFPROTO_IPV4, NF_INET_FORWARD,NULL , skb, skb->dev, rt->dst.dev,0 );goto drop;0 );return NET_RX_DROP;
ip_forward_finish调用dst_output转发出去
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 static int ip_forward_finish (struct net *net, struct sock *sk, struct sk_buff *skb) struct ip_options *opt =#ifdef CONFIG_NET_SWITCHDEV if (skb->offload_l3_fwd_mark) {return 0 ;#endif if (unlikely(opt->optlen))return dst_output(net, sk, skb);
ip_local_out 在上层发送数据的时候都会经过ip_local_out,同时在__ip_local_out会触发NF_INET_LOCAL_OUT钩子函数进行检测
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 int __ip_local_out(struct net *net, struct sock *sk, struct sk_buff *skb){struct iphdr *iph =if (unlikely(!skb))return 0 ;return nf_hook(NFPROTO_IPV4, NF_INET_LOCAL_OUT,net, sk, skb, NULL , skb_dst(skb)->dev,dst_output);int ip_local_out (struct net *net, struct sock *sk, struct sk_buff *skb) int err;if (likely(err == 1 ))return err;
firewalld todo
相关资料
https://www.cisco.com/c/en/us/products/security/firewalls/what-is-a-firewall.html