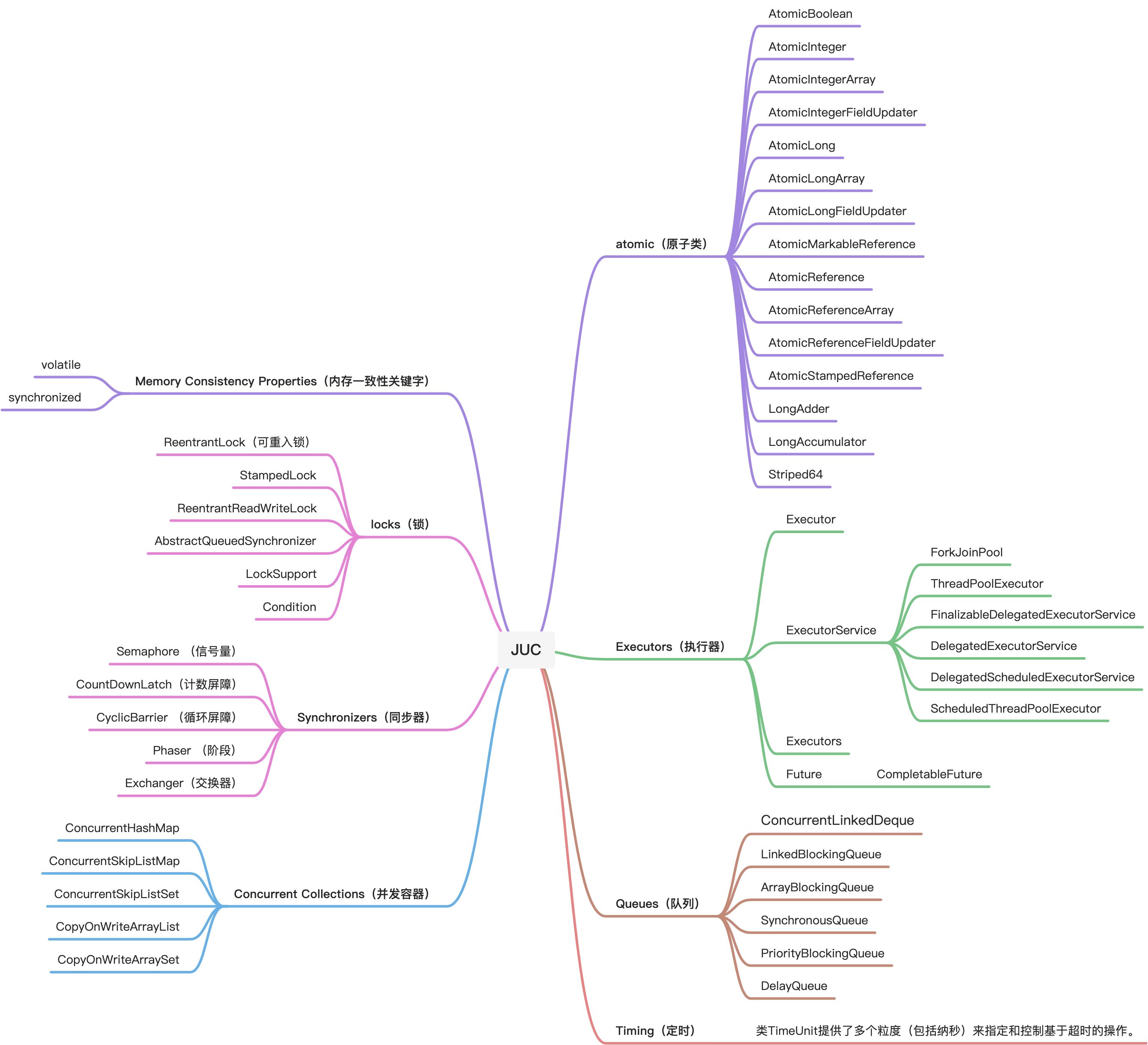
简介 java.util.concurrent(JUC)
本篇文章仅仅是对JUC包下的工具做一些简单的阐述,其每一项都可以更加的具体深入理解。
该包下是在并发编程中常用的实用程序类。这个包包括一些小型的标准化可扩展框架,以及一些提供有用功能的类。
Atomic(原子类)
该包下主要提供一些数据类型的原子类,如AtomicBoolean、AtomicInteger、AtomicIntegerArray、AtomicIntegerFieldUpdater、AtomicLong、AtomicLongArray、AtomicLongFieldUpdater、AtomicMarkableReference、AtomicReference、AtomicReferenceArray、AtomicReferenceFieldUpdater、AtomicStampedReference。这些原子类全部依托与底层的Unsafe类实现CAS的操作保证其原子性。
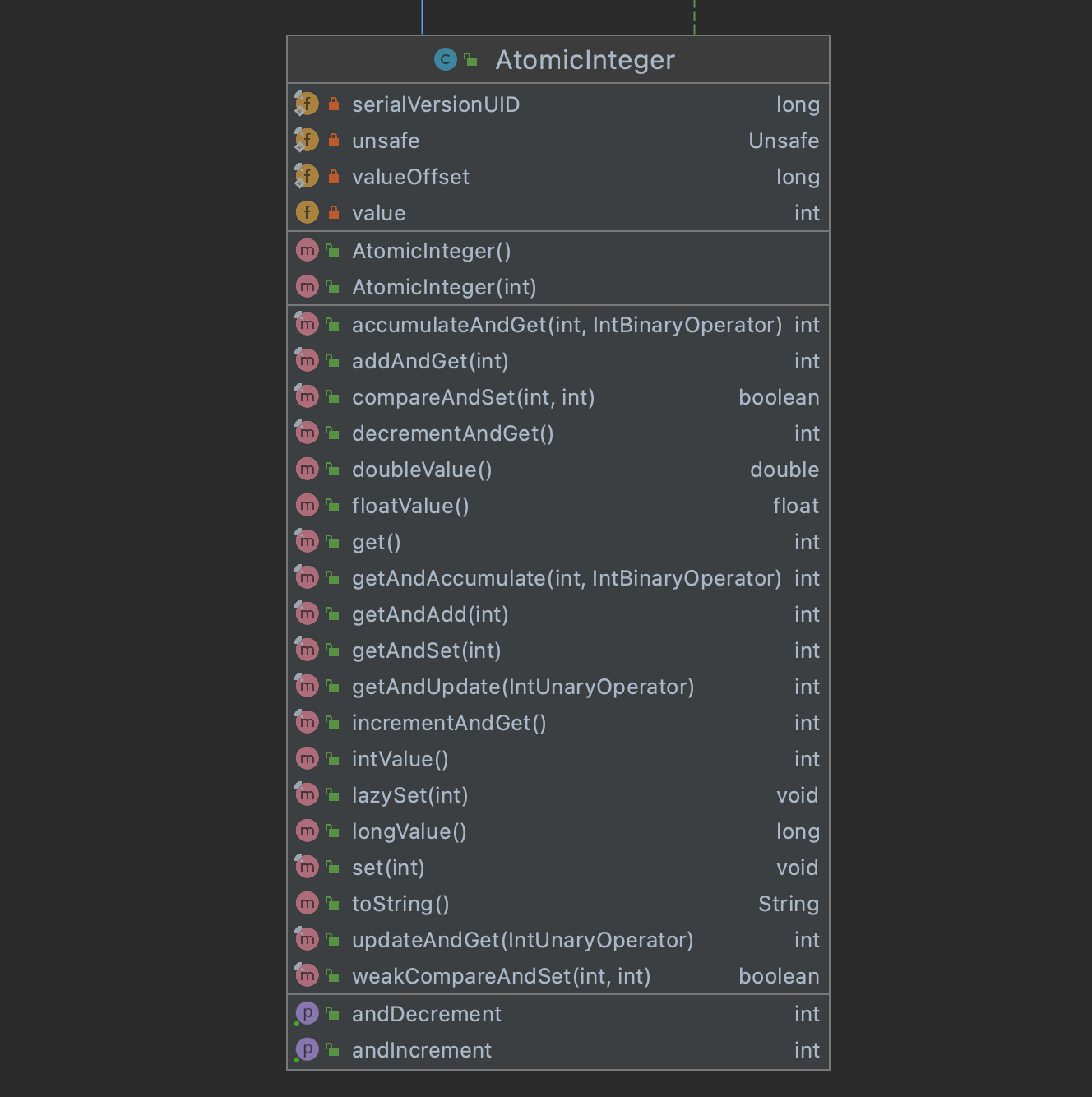
AtomicInteger
AtomicInteger的主要方法如下图所示
JUC包下的相关原子类都是基于Unsafe类来进行CAS实现,Unsafe通过JDNI调用本地接口来操作内存实现我们加/解锁、
Unsafe类 see: https://mikeygithub.github.io/2022/05/25/yuque/eff1dm/
使用案例
1.基于AtomicInteger实现线程交替打印AB
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public static void main (String[] args) throws Exception {AtomicInteger atomicInteger = new AtomicInteger (0 );new Thread (while (atomicInteger.get() <= 1000 )while ( atomicInteger.get() % 2 == 0 ) {"Thread A " ).start();new Thread (while (atomicInteger.get() <= 1000 )while ( atomicInteger.get() % 2 != 0 ) {"Thread B " ).start();3000 );
2.基于AtomicInteger实现多线程打印ABCD
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public static void main (String[] args) throws Exception {int count = 1 ;AtomicInteger aa = new AtomicInteger (0 );AtomicInteger bb = new AtomicInteger (0 );AtomicInteger cc = new AtomicInteger (0 );AtomicInteger dd = new AtomicInteger (0 );new Thread (while (aa.get() < count )while ( dd.get() == aa.get()) {"A" );"Thread A " ).start();new Thread (while (bb.get() < count )while ( bb.get() < aa.get()) {"B" );"Thread B " ).start();new Thread (while (cc.get() < count )while ( cc.get() < bb.get()) {"C" );"Thread C " ).start();new Thread (while (dd.get() < count )while ( dd.get() < cc.get()) {"D" );"Thread D " ).start();3000 );
LongAdder 基于性能考虑。AtomicLong的incrementAndGet()方法在高并发场景下,多个线程竞争修改共享资源value,会造成循环耗时过长(一直自旋CAS),进而导致性能问题,这个时候LongAdder应运而生。
1 public class LongAdder extends Striped64 implements Serializable
可以看到LongAdder继承的是Striped64,其核心操作和属性也是在Striped64中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 transient volatile Cell[] cells;transient volatile long base;transient volatile int cellsBusy;@sun .misc.Contendedstatic final class Cell {volatile long value;long x) {final boolean cas (long cmp, long val) {return UNSAFE.compareAndSwapLong(this , valueOffset, cmp, val);private static final sun.misc.Unsafe UNSAFE;private static final long valueOffset;static {try {"value" ));catch (Exception e) {throw new Error (e);final boolean casBase (long cmp, long val) {return UNSAFE.compareAndSwapLong(this , BASE, cmp, val);static final int getProbe () {return UNSAFE.getInt(Thread.currentThread(), PROBE);final boolean casCellsBusy () {return UNSAFE.compareAndSwapInt(this , CELLSBUSY, 0 , 1 );final void longAccumulate (long x, LongBinaryOperator fn, boolean wasUncontended) {int h;if ((h = getProbe()) == 0 ) {true ;boolean collide = false ;for (; ; ) {int n;long v;if ((as = cells) != null && (n = as.length) > 0 ) {if ((a = as[(n - 1 ) & h]) == null ) {if (cellsBusy == 0 ) { Cell r = new Cell (x); if (cellsBusy == 0 && casCellsBusy()) {boolean created = false ;try { int m, j;if ((rs = cells) != null &&0 &&1 ) & h] == null ) {true ;finally {0 ;if (created)break ;continue ; false ;else if (!wasUncontended) true ; else if (a.cas(v = a.value, ((fn == null ) ? v + x :break ;else if (n >= NCPU || cells != as) collide = false ; else if (!collide) collide = true ;else if (cellsBusy == 0 && casCellsBusy()) {try {if (cells == as) { new Cell [n << 1 ];for (int i = 0 ; i < n; ++i)finally {0 ;false ;continue ; else if (cellsBusy == 0 && cells == as && casCellsBusy()) {boolean init = false ;try { if (cells == as) {new Cell [2 ];1 ] = new Cell (x);true ;finally {0 ;if (init) break ;else if (casBase(v = base, ((fn == null ) ? v + x :break ;
1 2 3 4 5 public static ThreadLocalRandom current () {if (UNSAFE.getInt(Thread.currentThread(), PROBE) == 0 )localInit();return instance;
下面我们来看看LongAdder的相关方法,可以看到其increment和decrement都调用了add方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public void add (long x) {long b, v; int m; if ((as = cells) != null || !casBase(b = base, b + x)) {boolean uncontended = true ;if (as == null || (m = as.length - 1 ) < 0 ||null ||null , uncontended);public void increment () {1L );public void decrement () {1L );
结论:
内部维护了多个Cell变量,每个Cell里面有一个初始值为0的long型变量,这样同时争取一个变量的线程就变少了,而是分散成对多个变量的竞争,减少了失败次数。如果竞争某个Cell变量失败,它不会一直在这个Cell变量上自旋CAS重试,而是尝试在其他的Cell变量上进行CAS尝试,这个改变增加了当前线程重试CAS成功的可能性。最后,在获取LongAdder当前值时,是把所有Cell变量的value值累加后再加上base返回的,即:它的 sum 是 base + 各个 Cell 中 value 的总和
LongAdder的原理就是降低对value更新的并发数,也就是将对单一value的变更压力分散到多个value值上,降低单个value的竞争。
LongAccumulator
它是把LongAdder的(v + x)操作换成一个LongBinaryOperator,即用户可以自定义累加操作的逻辑,其他地方都是一样的
1 2 3 public LongAccumulator (LongBinaryOperator accumulatorFunction, long identity) { this .function = accumulatorFunction; base = this .identity = identity;
Striped64 分散热点,将value值分散到一个数组中,不同线程会命中到数组的不同槽中,各个线程只对自己槽中的那个值进行CAS操作,这样热点就被分散了,冲突的概率就小很多。如果要获取真正的long值,只要将各个槽中的变量值累加返回。
Executors(执行器)
此包中定义的Executor、ExecutorService、ScheduledExecutorService、ThreadFactory和可调用类的工厂和实用程序方法。此类支持以下类型的方法:
创建并返回使用常用配置设置设置设置的ExecutorService的方法。
创建并返回使用常用配置设置设置设置的ScheduledExecutorService。
创建并返回“包装的”ExecutorService,该服务通过使特定于实现的方法不可访问来禁用重新配置。
创建并返回将新创建的线程设置为已知状态的线程工厂。
这些方法从其他类似闭包的表单中创建并返回可调用的,因此可以在需要可调用的执行方法中使用。
Executor
该类为执行器的统一抽象接口,只规范了一个execute方法
1 2 3 4 5 6 7 8 9 10 11 12 13 public interface Executor {void execute (Runnable command) ;
ExecutorService
executorService是统一任务或者线程执行服务规范定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public interface ExecutorService extends Executor {void shutdown () ;shutdownNow () ;boolean isShutdown () ;boolean isTerminated () ;boolean awaitTermination (long timeout, TimeUnit unit) throws InterruptedException;submit (Callable<T> task) ;submit (Runnable task, T result) ;invokeAll (Collection<? extends Callable<T>> tasks) throws InterruptedException;invokeAll (Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException;invokeAny (Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException;invokeAny (Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException;
ScheduledThreadPoolExecutor
一种线程池执行器,可以另外安排命令在给定延迟后运行,或定期执行。当需要多个工作线程时,或者当需要ThreadPoolExecutor(该类扩展)的额外灵活性或功能时,该类比Timer更可取。
使用案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class ScheduledThreadPoolExecutorExample {static SimpleDateFormat sdf = new SimpleDateFormat ("yyyy-MM-dd HH:mm:ss" );public static String getDate () {return sdf.format(new Date ());@SneakyThrows public static void main (String[] args) throws Exception{ScheduledThreadPoolExecutor executor = new ScheduledThreadPoolExecutor (2 ,new ThreadPoolExecutor .AbortPolicy());"线程 %s 当前时间 %s" ,Thread.currentThread().getName(),getDate())),3 , TimeUnit.SECONDS);"线程%s 当前时间%s" ,Thread.currentThread().getName(),getDate())),3 ,3 , TimeUnit.SECONDS);30000 );
ForkJoinPool ForkJoinPool旨在用于 **CPU 密集型 **工作负载。ForkJoinPool 中的默认线程数等于系统上的 CPU 数。如果任何线程由于在某个其他 ForkJoinTask 上调用 join() 而进入等待状态,则会启动一个新的补偿线程以利用系统的所有 CPU。ForkJoinPool 有一个公共池,可以通过调用ForkJoinPool.commonPool()静态方法获得。此设计的目的是在系统中仅使用一个 ForkJoinPool,线程数等于系统上的处理器数。如果所有 ForkJoinTask 都在进行计算密集型任务,则它可以利用系统的全部计算能力。
但在现实生活场景中,任务是 CPU 和 IO 密集型任务的混合。IO 密集型任务对于 ForkJoinPool 来说是一个糟糕的选择。您应该使用 Executor 服务来执行 IO 密集型任务。在 ExecutorService 中,您可以根据系统的 IO 容量而不是系统的 CPU 容量来设置线程数。
如果要从 ForkJoinTask 调用 IO 密集型操作,则应创建一个实现ForkJoinPool.ManagedBlocker接口的类,并在block()方法中执行 IO 密集型操作。您需要使用静态方法ForkJoinPool.managedBlock()调用您的ForkJoinPool.ManagedBlocker实现。此方法在调用 block() 方法之前创建补偿线程。block() 方法应该进行 IO 操作并将结果存储在某个实例变量中。调用ForkJoinPool.managedBlock()后你应该调用你的业务方法来获取 IO 操作的结果。通过这种方式,你可以将 CPU 密集型操作与 IO 密集型操作混合使用。
ForkJoinPool不同于其他类型的ExecutorService,主要是因为它采用了**工作窃取 **:池中的所有线程都试图查找并执行提交给池和/或其他活动任务创建的任务(如果不存在,则最终阻止等待工作)。当大多数任务产生其他子任务时(就像大多数ForkJoinTasks一样),以及当许多小任务从外部客户端提交到池时,这可以实现高效处理。尤其是在构造函数中将asyncMode设置为true时,ForkJoinPools可能也适合用于从未加入的事件样式任务。
静态commonPool()适用于大多数应用程序。公共池由未显式提交到指定池的任何ForkJoinTask使用。使用公共池通常会减少资源使用(其线程在不使用期间缓慢回收,并在后续使用时恢复)。
对于需要单独或自定义池的应用程序,可以使用给定的目标并行级别构造ForkJoinPool;默认情况下,等于可用处理器的数量。池尝试通过动态添加、挂起或恢复内部工作线程来维护足够的活动(或可用)线程,即使某些任务在等待加入其他任务时暂停。但是,面对阻塞的I/O或其他非托管同步,无法保证进行此类调整。嵌套的ForkJoinPool。ManagedBlocker接口支持扩展所适应的同步类型。
除了执行和生命周期控制方法外,此类还提供状态检查方法(例如getStealCount),用于帮助开发、调优和监视fork/join应用程序。此外,方法toString以一种方便的形式返回池状态的指示,以便进行非正式监视。
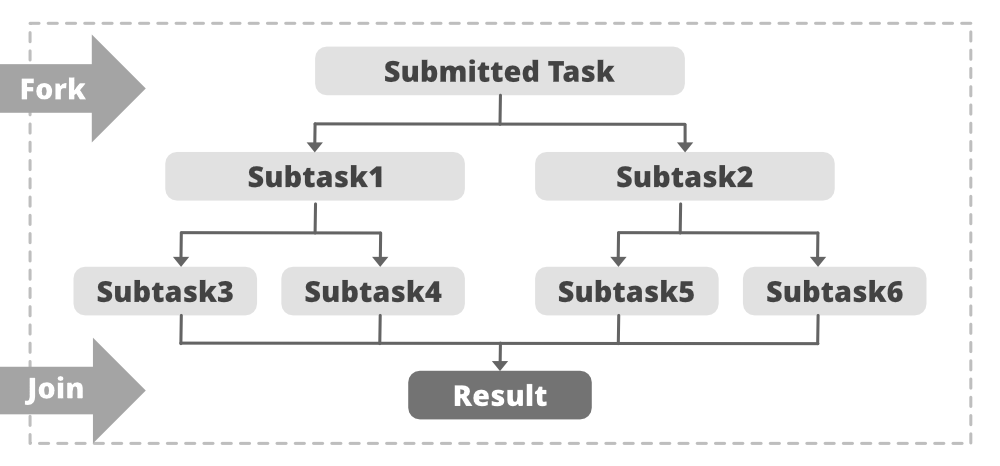
**Fork **:Fork步骤将任务拆分为更小的子任务,这些任务同时执行。
**Join **:在执行子任务之后,任务可以将所有结果加入到一个结果中。
如下图所示:
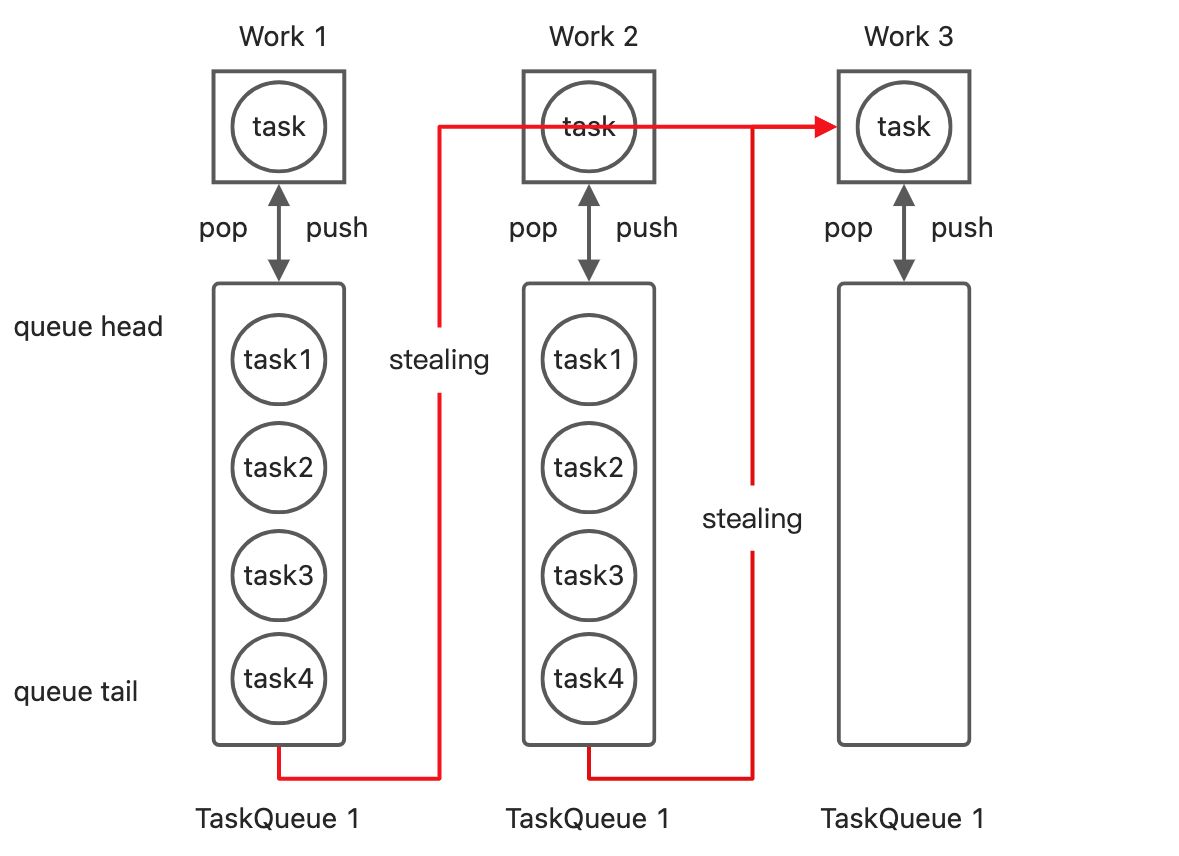
工作窃取(work-stealing) 工作窃取是指当某个线程的任务队列中没有可执行任务的时候,从其他线程的任务队列中窃取任务来执行,以充分利用工作线程的计算能力,减少线程由于获取不到任务而造成的空闲浪费。
参考: http://research.sun.com/scalable/pubs/index.html
在ForkJoinpool中,工作任务的队列都采用双端队列Deque容器。我们知道,在通常使用队列的过程中,我们都在队尾插入,而在队头消费以实现FIFO。而为了实现工作窃取。一般我们会改成工作线程在工作队列上LIFO,而窃取其他线程的任务的时候,从队列头部取获取。示意图如下:
工作线程worker1、worker2以及worker3都从taskQueue的尾部popping获取task,而任务也从尾部Pushing,当worker3队列中没有任务的时候,就会从其他线程的队列中取stealing,这样就使得worker3不会由于没有任务而空闲。
使用案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class NewTask extends RecursiveAction {private long Load = 0 ;public NewTask (long Load) { this .Load = Load; }protected void compute () {new ArrayList <NewTask>();for (RecursiveAction subtask : subtasks) {private List<NewTask> createSubtasks () {new ArrayList <NewTask>();NewTask subtask1 = new NewTask (this .Load / 2 );NewTask subtask2 = new NewTask (this .Load / 2 );NewTask subtask3 = new NewTask (this .Load / 2 );return subtasks;public static void main (final String[] arguments) throws InterruptedException {int proc = Runtime.getRuntime().availableProcessors();"Number of available core in the processor is: " + proc);ForkJoinPool Pool = ForkJoinPool.commonPool();"Number of active thread before invoking: " + Pool.getActiveThreadCount());NewTask t = new NewTask (400 );"Number of active thread after invoking: " + Pool.getActiveThreadCount());"Common Pool Size is: " + Pool.getPoolSize());
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @Slf4j public class ForkJoinPoolExample {static class Fibonacci extends RecursiveTask <Integer> {final int n;int n) {this .n = n;public Integer compute () {if (n <= 1 ) return n;Fibonacci f1 = new Fibonacci (n - 1 );Fibonacci f2 = new Fibonacci (n - 2 );return f2.compute() + f1.join();@SneakyThrows public static void main (String[] args) throws Exception {ForkJoinPool Pool = ForkJoinPool.commonPool();Fibonacci t = new Fibonacci (10 );Integer ret = t.get();"ret : " + ret);5000 );
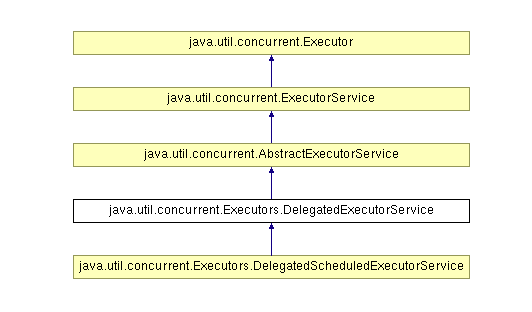
DelegatedExecutorService
仅公开ExecutorService实现 **的ExecutorService方法的包装类 **。Delegate(委托、委派)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 static class DelegatedExecutorService extends AbstractExecutorService {private final ExecutorService e;public void execute (Runnable command) { e.execute(command); }public void shutdown () { e.shutdown(); }public List<Runnable> shutdownNow () { return e.shutdownNow(); }public boolean isShutdown () { return e.isShutdown(); }public boolean isTerminated () { return e.isTerminated(); }public boolean awaitTermination (long timeout, TimeUnit unit) throws InterruptedException {return e.awaitTermination(timeout, unit);public Future<?> submit(Runnable task) {return e.submit(task);public <T> Future<T> submit (Callable<T> task) {return e.submit(task);public <T> Future<T> submit (Runnable task, T result) {return e.submit(task, result);public <T> List<Future<T>> invokeAll (Collection<? extends Callable<T>> tasks) throws InterruptedException {return e.invokeAll(tasks);public <T> List<Future<T>> invokeAll (Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException {return e.invokeAll(tasks, timeout, unit);public <T> T invokeAny (Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException {return e.invokeAny(tasks);public <T> T invokeAny (Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException {return e.invokeAny(tasks, timeout, unit);
使用案例
通过调用unconfigurableExecutorService方法可直接获取DelegatedExecutorService的实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class DelegatedExecutorServiceExample {static ExecutorService executorService = Executors.unconfigurableExecutorService(new ThreadPoolExecutor (3 , 5 , 1 , TimeUnit.SECONDS, new LinkedBlockingDeque <>()));public static void main (String[] args) throws InterruptedException {for (int i = 0 ; i < 20 ; i++) {" " +DateUtils.getDate()));2000 );
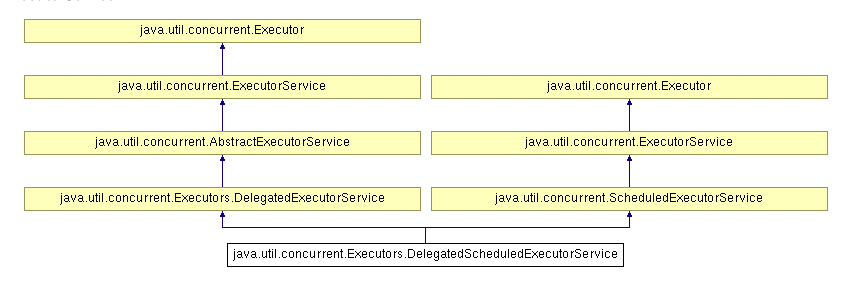
DelegatedScheduledExecutorService
DelegatedScheduledExecutorService是Executors的一个内部类,仅供**ScheduledExecutorService **实现的ScheduledExecutorService方法的包装类。用于任务调度的线程池服务。
该类的源码较少,直接是对DelegatedExecutorService进行继承,实现ScheduledExecutorService接口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 static class DelegatedScheduledExecutorService extends DelegatedExecutorService implements ScheduledExecutorService {private final ScheduledExecutorService e;super (executor);public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit) {return e.schedule(command, delay, unit);public <V> ScheduledFuture<V> schedule (Callable<V> callable, long delay, TimeUnit unit) {return e.schedule(callable, delay, unit);public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit) {return e.scheduleAtFixedRate(command, initialDelay, period, unit);public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit) {return e.scheduleWithFixedDelay(command, initialDelay, delay, unit);
使用案例
通过newSingleThreadScheduledExecutor方法可直接获取单线程的线程池时间调度执行器
1 2 3 public static ScheduledExecutorService newSingleThreadScheduledExecutor () {return new DelegatedScheduledExecutorService (new ScheduledThreadPoolExecutor (1 ));
1 2 3 4 5 6 7 8 9 10 public class DelegatedScheduledExecutorServiceExample {static ScheduledExecutorService scheduledExecutorService = Executors.newSingleThreadScheduledExecutor();public static void main (String[] args) throws Exception {for (int i = 0 ; i < 5 ; i++) {" " +DateUtils.getDate()),2 ,TimeUnit.SECONDS);5000 );
FinalizableDelegatedExecutorService
FinalizableDelegatedExecutorService的结构非常简单,继承DelegatedExecutorService类,重写了finalize在回收当前类的时候对线程池进行关闭操作
1 2 3 4 5 6 7 8 9 static class FinalizableDelegatedExecutorService extends DelegatedExecutorService {super (executor);protected void finalize () {super .shutdown();
使用案例
FinalizableDelegatedExecutorService的获取可以通过Executors.newSingleThreadExecutor方法获取
1 2 3 public static ExecutorService newSingleThreadExecutor () {return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor (1 , 1 , 0L , TimeUnit.MILLISECONDS,new LinkedBlockingQueue <Runnable>()));
1 2 3 4 5 6 7 8 9 10 11 12 public class FinalizableDelegatedExecutorServiceExample {static ExecutorService executorService = Executors.newSingleThreadExecutor();public static void main (String[] args) throws Exception{for (int i = 0 ; i < 5 ; i++) {" " + DateUtils.getDate()));3000 );
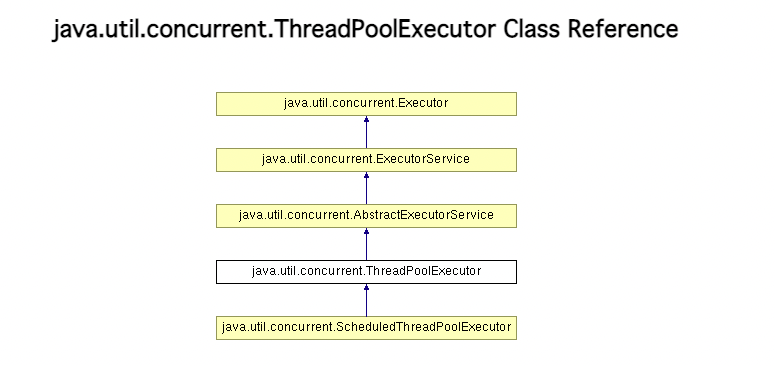
ThreadPoolExecutor
ThreadPoolExecutor类是线程池的根基类,上面提到的ScheduledExecutorService、五种ExecutorService都是基于ThreadPoolExecutor进行实现的。
详细分析参考:https://mikeygithub.github.io/2022/05/30/yuque/ymxl5b/ 在本篇中不再做详细概述。
使用案例
直接通过构造函数使用
1 2 3 4 5 6 7 8 new ThreadPoolExecutor (core, max, 0L , TimeUnit.MILLISECONDS, new LinkedBlockingQueue <Runnable>());
RejectedExecutionHandler
当我们任务过多超出阻塞队列的长度时,会根据我们配置的拒绝策略来决定新任务的去向,RejectedExecutionHandler定义了拒绝策略的统一标准,JDK提供有四个实现类CallerRunsPolicy、CallerRunsPolicy、DiscardPolicy、DiscardOldestPolicy
AbortPolicy
AbortPolicy,缺省策略,处理程序在拒绝时抛出runtime RejectedExecutionException。
CallerRunsPolicy
CallerRunPolicy,调用自身执行的线程运行任务。这提供了一种简单的反馈控制机制,可以降低提交新任务的速度。
DiscardPolicy
DiscardPolicy,将简单地删除无法执行的任务。
DiscardOldestPolicy
DiscardOldestPolicy,如果未关闭执行器,将丢弃工作队列头部的任务,然后重试执行(可能再次失败,导致重复执行)
�
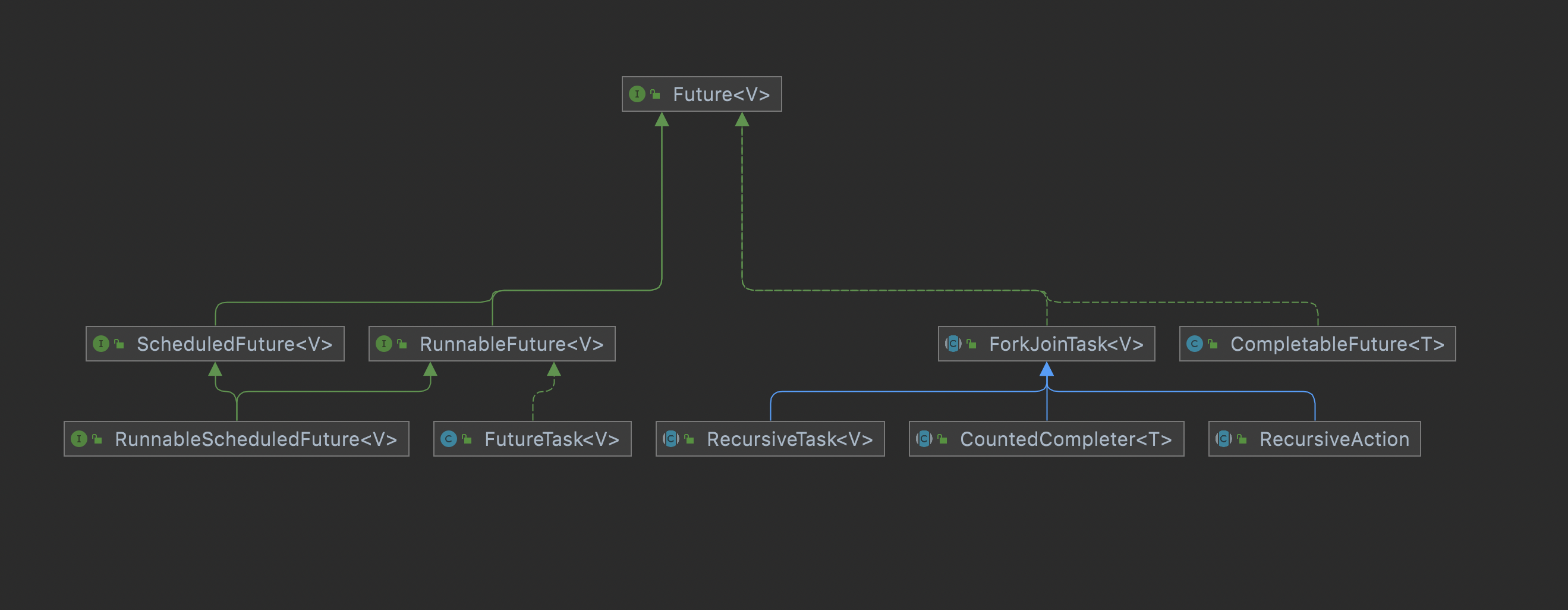
Future
线程执行的异步任务结果,Future作为任务执行结果的顶层接口。
Future表示异步计算的结果。提供了检查计算是否完成、等待其完成以及检索计算结果的方法。只有在计算完成后,才能使用方法get检索结果,如有必要,请阻塞,直到它准备就绪。通过cancel方法执行取消。还提供了其他方法来确定任务是正常完成还是取消。一旦计算完成,就不能取消计算。如果为了可取消性而想使用Future,但没有提供可用的结果,则可以声明Future表单的类型并作为基础任务的结果返回null。
1 2 3 4 5 6 7 8 9 10 11 12 13 public interface Future <V> {boolean cancel (boolean mayInterruptIfRunning) ;boolean isCancelled () ;boolean isDone () ;get () throws InterruptedException, ExecutionException;get (long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException;
FutureTask:最基础的Future接口实现 ForkJoinTask:提供可拆分和汇总结果的任务类型,作用于ForkJoin线程池 RecursiveTask:ForkJoinTask的子抽象类用于带返回值的任务结果执行 RecursiveAction:ForkJoinTask的子抽象类用于不带返回值的任务结果执行 CompletableFuture: 可以显式完成(设置其值和状态)的Future,可以用作CompletionStage,支持在完成时触发的依赖函数和操作。当两个或多个线程尝试完成、异常完成或取消可完成的未来时,只有一个线程成功。CountedCompleter:ForkJoinTask的 子抽象类,一个ForkJoinTask在触发时执行完成操作,并且没有剩余的待处理操作。与其他形式的 ForkJoinTask 相比,CountedCompleter 通常在存在子任务停顿和阻塞的情况下更加健壮,但编程起来不太直观。CountedCompleter 的使用类似于其他基于完成的组件(例如CompletionHandler),除了可能需要多个待处理的完成来触发完成操作onCompletion(CountedCompleter),而不仅仅是一个。除非另外初始化,否则挂起的计数从零开始,但可以使用方法setPendingCount(int)、addToPendingCount(int)和 (原子地)更改compareAndSetPendingCount(int, int)。在调用tryComplete(),如果挂起的动作计数不为零,则递减;否则,执行完成动作,如果这个完成者本身有一个完成者,则使用它的完成者继续该过程。与相关同步组件的情况一样,例如Phaser和 Semaphore,这些方法只影响内部计数;他们没有建立任何进一步的内部簿记。特别是,未维护待处理任务的身份
Queues (阻塞队列)
JUC包下提供了六种同步队列,分别为 ConcurrentLinkedDeque、LinkedBlockingQueue、ArrayBlockingQueue、SynchronousQueue、PriorityBlockingQueue、DelayQueue
ConcurrentLinkedDeque
ConcurrentLinkedDeque是基于链表的无界限线程安全双端队列。
此队列对元素进行 FIFO(先进先出)排序。队列的头部是在队列中时间最长的元素。队列的尾部是在队列中时间最短的元素。新元素被插入到队列的尾部,队列检索操作获取队列头部的元素。ConcurrentLinkedQueue当许多线程将共享对公共集合的访问时,A是一个合适的选择。此队列不允许null元素。
该实现采用了一种高效的“无等待”算法,该算法基于Maged M. Michael 和 Michael L. Scott在Simple、Fast、Practical Non-Blocking 和 Blocking Concurrent Queue Algorithms中描述的算法。 注意,与大多数集合不同,该size方法不是恒定时间操作。由于这些队列的异步特性,确定当前元素的数量需要遍历元素。
LinkedBlockingQueue
基于链表的可选有界 BlockingQueue 阻塞队列
此队列对元素进行 FIFO(先进先出)排序。队列的头部是在队列中时间最长的元素。队列的尾部是在队列中时间最短的元素。新元素被插入到队列的尾部,队列检索操作获取队列头部的元素。链接队列通常比基于数组的队列具有更高的吞吐量,但在大多数并发应用程序中性能更不可预测。
可选的容量绑定构造函数参数用作防止过度队列扩展的一种方式。容量(如果未指定)等于**Integer.MAX_VALUE **。链接节点在每次插入时动态创建,除非这会使队列超出容量。
ArrayBlockingQueue
基于数组的阻塞队列
由数组支持的有界阻塞队列。此队列对元素FIFO进行排序(先进先出)。队列的头是在队列上停留时间最长的元素。队列的尾部是在队列上停留时间最短的元素。新元素插入到队列的尾部,队列检索操作获取队列头部的元素。
这是一个经典的“有界缓冲区”,其中固定大小的数组保存生产者插入的元素和消费者提取的元素。一旦创建,容量就无法更改。尝试将元素放入完整队列将导致操作阻塞;尝试从空队列中获取元素也会被类似地阻止。
此类支持一个可选的公平策略,用于排序等待的生产者线程和消费者线程。默认情况下,不保证此顺序。然而,公平性设置为true的队列以FIFO顺序授予线程访问权限。公平性通常会降低吞吐量,但会减少可变性并避免饥饿。
SynchronousQueue
一个 BlockingQueue 阻塞队列,其中每个都 put 必须等待 take ,反之亦然。
同步队列没有任何内部容量,甚至没有一个容量。您不能peek在同步队列中,因为一个元素仅在您尝试获取它时才存在;除非另一个线程试图删除它,否则您不能添加元素(使用任何方法);你不能迭代,因为没有什么可以迭代的。队列的头部是第一个排队线程试图添加到队列中的元素;如果没有排队的线程,则没有添加任何元素并且头部是null. 对于其他Collection方法(例如contains), aSynchronousQueue充当空集合。此队列不允许null元素。
同步队列类似于 CSP 和 Ada 中使用的集合通道。它们非常适合切换设计,其中一个线程中运行的对象必须与另一个线程中运行的对象同步,以便将一些信息、事件或任务交给它。
此类支持对等待的生产者和消费者线程进行排序的可选公平策略。默认情况下,不保证此排序。但是,使用公平设置构造的队列以trueFIFO 顺序授予线程访问权限。公平性通常会降低吞吐量,但会降低可变性并避免饥饿。
PriorityBlockingQueue
优先阻塞队列(堆),一个无界的 BlockingQueue 阻塞队列,它使用与类PriorityQueue 相同的排序规则并提供阻塞检索操作。
虽然此队列在逻辑上是无界的,但尝试添加可能会由于资源耗尽(导致OutOfMemoryError)而失败。此类不允许null元素。依赖于自然排序的优先级队列也不允许插入不可比较的对象(这样做会导致ClassCastException)。
此类实现了Collection和Iterator接口的所有可选方法。
方法iterator()中提供的 Iterator不能保证以任何特定顺序遍历 PriorityBlockingQueue 的元素。如果您需要有序遍历,请考虑使用Arrays.sort (pq.toArray()).
此类是Java Collections Framework的成员。
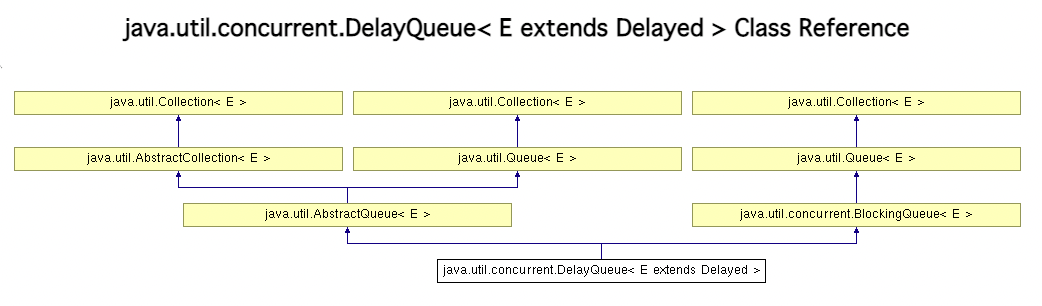
DelayQueue
元素的无界 BlockingQueue 阻塞队列 Delayed,其中一个元素只有在其延迟到期时才能被取出。
队列 的头部Delayed是过去延迟过期最远的元素——如果没有延迟过期,则没有头部并且poll将返回null。此队列不允许null元素。
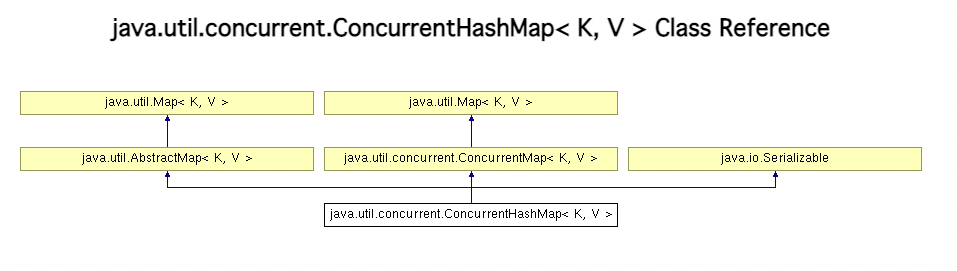
Concurrent Collections (并发容器) ConcurrentHashMap
并发的HashMap,采用segments对区间内的桶进行加锁,降低锁的范围,增加锁的细粒度,从而提高效率。
检索操作(包括get)一般不会阻塞,因此可能与更新操作(包括put 、 remove)重叠。检索反映了最近完成的更新操作在其开始时保持的结果。putAll对于和等聚合操作clear,并发检索可能仅反映插入或删除某些条目。类似地,迭代器和枚举返回反映哈希表在创建迭代器/枚举时或之后的某个时间点的状态的元素。他们不会抛出ConcurrentModificationException。但是,迭代器被设计为一次只能由一个线程使用。
更新操作之间允许的并发性由可选的concurrencyLevel构造函数参数(默认为 16)指导,该参数用作内部大小调整的提示。该表是内部分区的,以尝试允许指定数量的并发无争用更新。因为哈希表中的放置本质上是随机的,所以实际的并发性会有所不同。理想情况下,您应该选择一个值来容纳尽可能多的线程同时修改表。使用显着高于您需要的值会浪费空间和时间,而显着降低的值会导致线程争用。但是一个数量级内的高估和低估通常不会产生太大的影响。当已知只有一个线程会修改而所有其他线程只会读取时,值 1 是合适的。
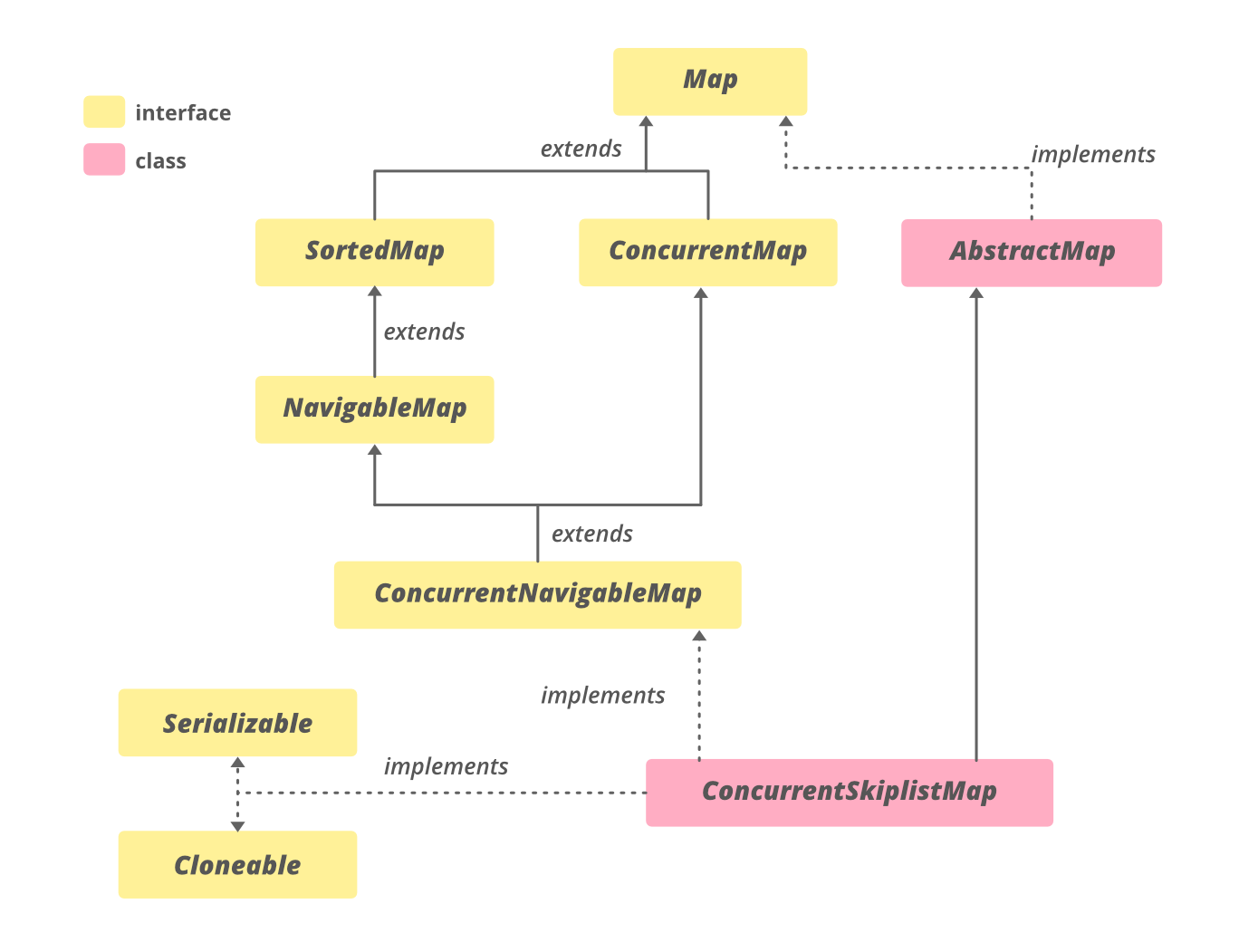
ConcurrentSkipListMap
并发的跳表 Map,基于ConcurrentNavigableMap()接口实现。ConcurrentSkipListMap其核心思想是基于跳表CAS更新达到线程安全的效果。
跳表参考:https://mikeygithub.github.io/2022/02/20/yuque/pea42q/
ConcurrentSkipListMap内部关键的类如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 class Index <K,V> {final Node<K,V> node;final Index<K,V> down;volatile Index<K,V> right;this .node = node;this .down = down;this .right = right;final boolean casRight (Index<K,V> cmp, Index<K,V> val) {return UNSAFE.compareAndSwapObject(this , rightOffset, cmp, val);final boolean indexesDeletedNode () {return node.value == null ;final boolean link (Index<K,V> succ, Index<K,V> newSucc) {return n.value != null && casRight(succ, newSucc);final boolean unlink (Index<K,V> succ) {return node.value != null && casRight(succ, succ.right);private static final sun.misc.Unsafe UNSAFE;private static final long rightOffset;static {try {"right" ));catch (Exception e) {throw new Error (e);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 class Node <K,V> {final K key;volatile Object value;volatile Node<K,V> next;this .key = key;this .value = value;this .next = next;this .key = null ;this .value = this ;this .next = next;boolean casValue (Object cmp, Object val) {return UNSAFE.compareAndSwapObject(this , valueOffset, cmp, val);boolean casNext (Node<K,V> cmp, Node<K,V> val) {return UNSAFE.compareAndSwapObject(this , nextOffset, cmp, val);boolean isMarker () {return value == this ;boolean isBaseHeader () {return value == BASE_HEADER;boolean appendMarker (Node<K,V> f) {return casNext(f, new Node <K,V>(f));void helpDelete (Node<K,V> b, Node<K,V> f) {if (f == next && this == b.next) {if (f == null || f.value != f) new Node <K,V>(f));else this , f.next);getValidValue () {Object v = value;if (v == this || v == BASE_HEADER)return null ;@SuppressWarnings("unchecked") V vv = (V)v;return vv;createSnapshot () {Object v = value;if (v == null || v == this || v == BASE_HEADER)return null ;@SuppressWarnings("unchecked") V vv = (V)v;return new AbstractMap .SimpleImmutableEntry<K,V>(key, vv);private static final sun.misc.Unsafe UNSAFE;private static final long valueOffset;private static final long nextOffset;static {try {"value" ));"next" ));catch (Exception e) {throw new Error (e);
使用案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class ConcurrentSkipListMapExample {public static void main (String[] args) {new ConcurrentSkipListMap <String, String>();"3" , "Three" );"1" , "One" );"5" , "Five" );"4" , "Four" );"初始化Map : " + cslm);"2的上限: " + cslm.ceilingEntry("2" ));NavigableSet navigableSet = cslm.descendingKeySet();"descendingKeySet: " );Iterator itr = navigableSet.iterator();while (itr.hasNext()) {String s = (String) itr.next();"第一个Entry: " + cslm.firstEntry());"最后一个Entry: " + cslm.lastEntry());"弹出第一个Entry: " + cslm.pollFirstEntry());"当前第一个Entry: " + cslm.firstEntry());"弹出最后一个Entry: " + cslm.pollLastEntry());"当前第一个Entry: " + cslm.lastEntry());
参考资料:ConcurrentSkipListMap
ConcurrentSkipListSet
ConcurrentSkipListSet通过ConcurrentSkipListMap的key来进行存储,value存放Object。
CopyOnWriteArrayList
ArrayList的一种线程安全变体,其中所有可变操作(添加、设置等)都是通过创建基础数组的新副本来实现的。顾名思义其容器是在写的时候对数组写入加锁做一次拷贝,而不是对读进行加锁,所以读可以正常进行。
通常成本太高,但在遍历操作的数量远远超过突变的情况下,可能比其他方法更有效,并且在你无法或不想同步遍历,但需要排除并发线程之间的干扰时非常有用。“快照”样式的迭代器方法使用对创建迭代器时数组状态的引用。该数组在迭代器的生存期内从不更改,因此不可能发生干扰,并且迭代器保证不会抛出ConcurrentModificationException。自创建迭代器以来,迭代器不会反映对列表的添加、删除或更改。不支持迭代器本身的元素更改操作(remove、set和add)。这些方法引发UnsupportedOperationException。
该容器允许所有元素,包括null。
内存一致性影响:与其他并发集合一样,在将对象放入CopyOnWriteArrayList之前,线程中的操作发生在另一个线程的CopyOnWriteArrayList中访问或删除该元素之后的操作之前。
1 final transient ReentrantLock lock = new ReentrantLock ();
我们来简单分析一下它内部的实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public E set (int index, E element) {final ReentrantLock lock = this .lock;try {E oldValue = get(elements, index);if (oldValue != element) {int len = elements.length;else {return oldValue;finally {
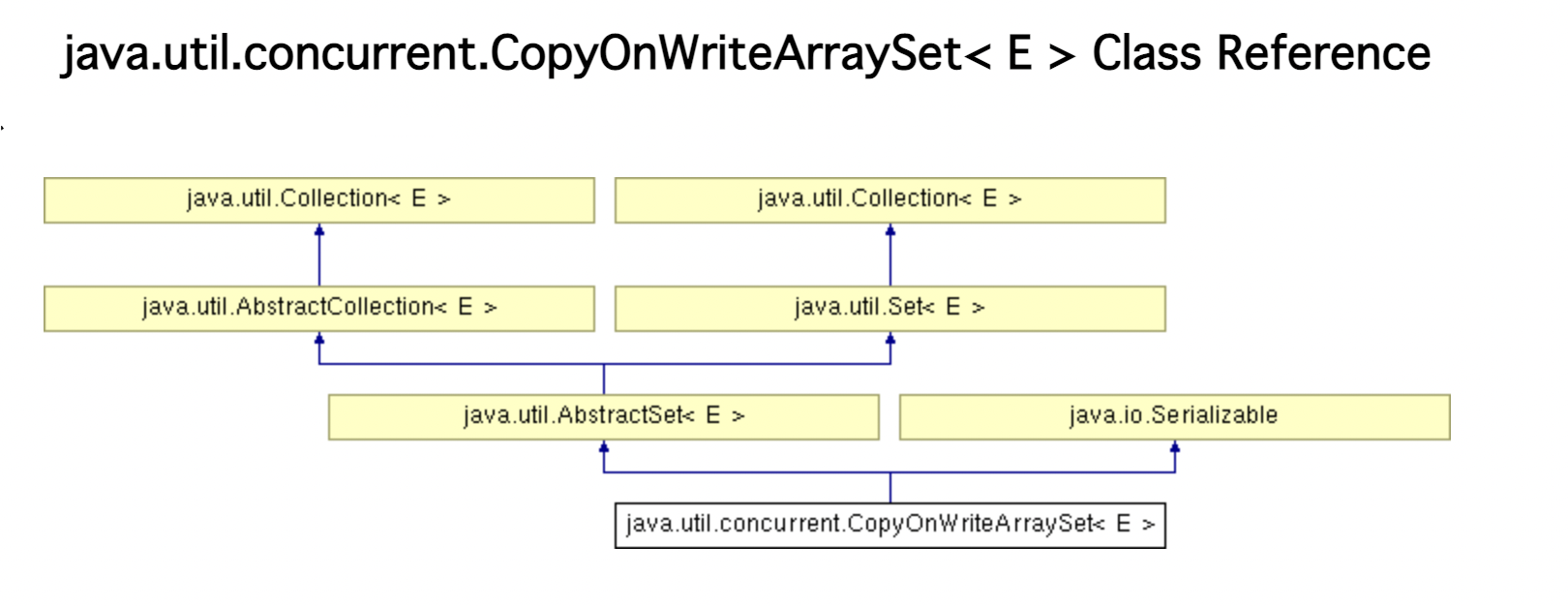
CopyOnWriteArraySet
基于CopyOnWriteArrayList实现
Synchronizers (同步器) 五个类帮助常见的专用同步习惯用法。
Semaphore是经典的并发工具。
CountDownLatch是一个非常简单但非常常见的实用程序,用于阻塞直到给定数量的信号、事件或条件成立。
CyclicBarrier是可重置的多路同步点,在某些并行编程风格中很有用。
Phaser提供了一种更灵活的屏障形式,可用于控制多个线程之间的分阶段计算。
Exchanger允许两个线程在一个集合点交换对象,并且在多个管道设计中很有用。
Semaphore(信号量)
计数信号量(基于AQS)。Semaphore的内部共存在Sync 、NonfairSync 、FairSync 三个类,NonfairSync与FairSync类继承自Sync类,Sync类继承自AbstractQueuedSynchronizer抽象类,也就Semaphore是依托于NonfairSync、FairSync来实现的。从概念上讲,信号量维护一组许可。如有必要,每个采集模块都会阻塞,直到获得许可证,然后再获取。每次发布都会添加一个许可证,可能会释放一个阻塞收单机构。但是,未使用实际许可对象;信号量只保留可用数字的计数,并相应地进行操作。
在获取项目之前,每个线程必须从信号量中获取许可,以保证项目可供使用。当线程完成该项目时,它会返回池中,并向信号量返回一个许可,允许另一个线程获取该项目。请注意,在调用acquire时不会持有同步锁,因为这会阻止项目返回到池中。信号量封装了限制对池的访问所需的同步,与维护池本身一致性所需的任何同步分开。
初始化为 1 的信号量,并且使用时最多只有一个可用的许可,可以用作互斥锁。这通常被称为二进制信号量,因为它只有两种状态:一个可用许可,或零个可用许可。当以这种方式使用时,二进制信号量具有属性(与许多Lock实现不同),“锁”可以由所有者以外的线程释放(因为信号量没有所有权的概念)。这在一些专门的上下文中很有用,例如死锁恢复。
此类的构造函数可选择接受公平参数。当设置为 false 时,此类不保证线程获取许可的顺序。特别是,允许插入,即调用acquire的线程可以在一直等待的线程之前获得许可。 当 fairness 设置为 true 时,信号量保证调用任何获取方法的线程按照处理它们调用这些方法的顺序(先进先出;FIFO)分配许可。请注意,FIFO 排序必然适用于这些方法中的特定内部执行点。因此,一个线程可以调用acquire在另一个之前,但在另一个之后到达排序点,同样在从方法返回时。
通常,用于控制资源访问的信号量应该被初始化为公平的,以确保没有线程因访问资源而被饿死。当使用信号量进行其他类型的同步控制时,非公平排序的吞吐量优势通常超过公平性考虑。
此类还提供方便的方法来一次获取 和释放 多个许可。当这些方法在不公平的情况下使用时,请注意无限期推迟的风险增加。
使用案例
信号量通常用于限制可以访问某些(物理或逻辑)资源的线程数。例如,下面是一个类,它使用信号量控制对项目池的访问
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 public class SemaphoreExample {private static final int MAX_AVAILABLE = 100 ;private final Semaphore available = new Semaphore (MAX_AVAILABLE, true );public Object getItem () throws InterruptedException {return getNextAvailableItem();public void putItem (Object x) {if (markAsUnused(x)) available.release();protected Object[] items = new Object [MAX_AVAILABLE];protected boolean [] used = new boolean [MAX_AVAILABLE];protected synchronized Object getNextAvailableItem () {for (int i = 0 ; i < MAX_AVAILABLE; ++i) {if (!used[i]) {true ;return items[i];return null ; protected synchronized boolean markAsUnused (Object item) {for (int i = 0 ; i < MAX_AVAILABLE; ++i) {if (item == items[i]) {if (used[i]) {false ;return true ;else return false ;return false ;
CountDownLatch (计数屏障)
一种同步辅助,允许一个或多个线程等待,直到在其他线程中执行的一组操作完成。
CountDownLatch用给定的count初始化。由于调用了countDown方法,等待方法一直阻塞,直到当前计数达到零,之后所有等待的线程都被释放,任何后续的await调用立即返回。这是一次性现象——计数无法重置 。如果您需要重置计数的版本,请考虑使用CyclicBarrier。
CountDownLatch是一种多功能同步工具,可用于多种用途。以 1 为计数的CountDownLatch初始化用作简单的开/关锁存器或门:所有调用await的线程在门处等待,直到它被调用countDown的线程打开。CountDownLatch初始化为N可用于使一个线程等待,直到N个线程完成某个动作,或者某个动作已完成 N 次。
的一个有用属性CountDownLatch是它不需要调用countDown的线程在继续之前等待计数达到零,它只是阻止任何线程继续等待,直到所有线程都可以通过。
使用案例
给定CountDownLatch初始值当我们完成一个线程的任务调用一次
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 public class CountDownLatchExample {static class Worker implements Runnable {private final CountDownLatch startSignal;private final CountDownLatch doneSignal;this .startSignal = startSignal;this .doneSignal = doneSignal;public void run () {try {catch (InterruptedException ex) {} void doWork () {try {2000 );catch (InterruptedException e) {public static final int N = 10 ;public static void drive1 () throws InterruptedException {CountDownLatch startSignal = new CountDownLatch (1 );CountDownLatch doneSignal = new CountDownLatch (N);for (int i = 0 ; i < N; ++i) {new Thread (new Worker (startSignal, doneSignal)).start();
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 public class CountDownLatchExample {public static final int N = 10 ;static class WorkerRunnable implements Runnable {private final CountDownLatch doneSignal;private final int i;int i) {this .doneSignal = doneSignal;this .i = i;public void run () {void doWork () {try {2000 );catch (InterruptedException e) {public static void drive2 () throws InterruptedException {CountDownLatch doneSignal = new CountDownLatch (N);Executor e = Executors.newSingleThreadExecutor();for (int i = 0 ; i < N; ++i) new WorkerRunnable (doneSignal, i));
CyclicBarrier (循环屏障)
一种多线程屏障辅助工具(可重复使用)它允许一组线程相互等待以达到共同的障碍点。
CyclicBarriers 在涉及固定大小的线程组的程序中很有用,这些线程组必须偶尔相互等待。屏障被称为循环的,因为它可以在等待线程被释放后重新使用。
CyclicBarrier支持一个可选的Runnable命令,该命令每个屏障点运行一次,在队伍中的最后一个线程到达之后,但在任何线程被释放之前。此屏障操作对于在任何一方继续之前更新共享状态很有用。
使用案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 public class CyclicBarriersExample {static class Work implements Runnable {private CyclicBarrier cyclicBarrier;public Work (CyclicBarrier cyclicBarrier) {this .cyclicBarrier = cyclicBarrier;public void doWork () {try {int time = (int ) (Math.random() * 10 )/2 * 1000 ;" " + DateUtils.getDate()+"sleep: " +time +" getNumberWaiting: " + cyclicBarrier.getNumberWaiting());catch (InterruptedException e) {@SneakyThrows @Override public void run () {public static void main (String[] args) throws InterruptedException {CyclicBarrier cyclicBarrier = new CyclicBarrier (10 , () -> System.out.println("所有任务已经执行完成:" + Thread.currentThread().getName() + " " + DateUtils.getDate()));for (int i = 0 ; i < 10 ; i++) {new Thread (new Work (cyclicBarrier)).start();5000 );for (int i = 0 ; i < 10 ; i++) {new Thread (new Work (cyclicBarrier)).start();
CyclicBarrier 与 CountDownLatch 区别
CountDownLatch 是一次性的,CyclicBarrier 是可循环利用的
CountDownLatch 参与的线程的职责是不一样的,有的在倒计时,有的在等待倒计时结束。CyclicBarrier 参与的线程职责是一样的。
Phaser(阶段)
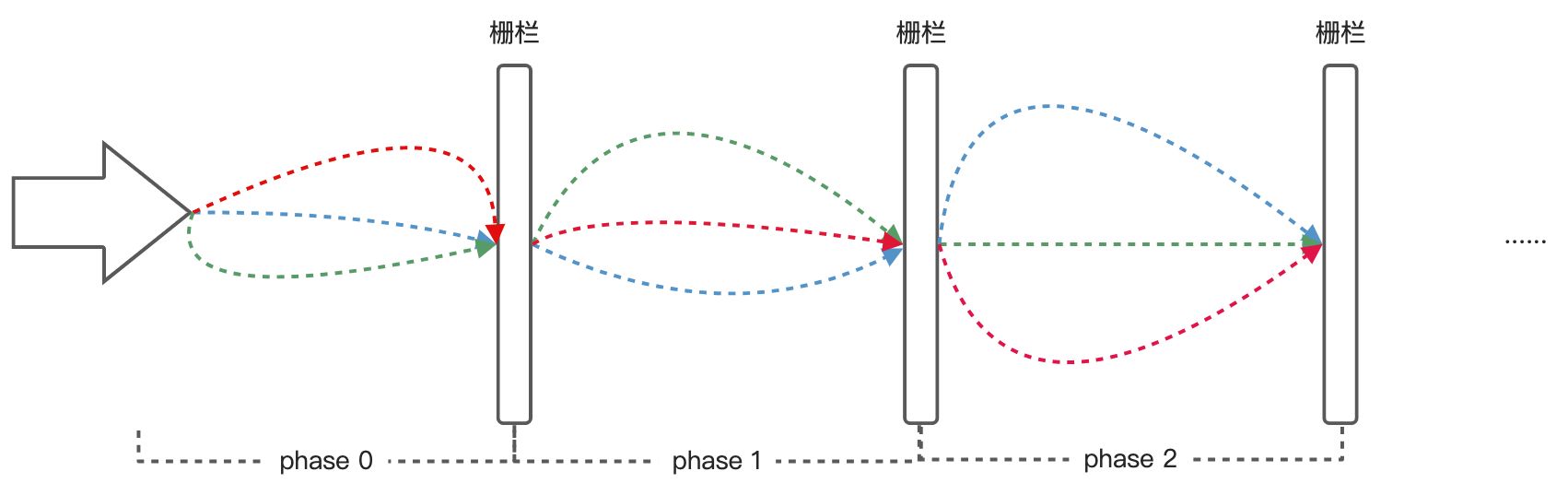
一个可重用的同步屏障,在功能上类似于CyclicBarrier和CountDownLatch,但支持更灵活的使用,无需设置固定的parties,可在使用过程中动态的。
Phaser与其他屏障的情况不同,在相位器上注册同步的参与方数量可能会随着时间的推移而变化。可以随时注册任务(使用方法register()、bulkRegister(int)或建立初始参与方数的构造函数的形式),也可以在任何到达时取消注册任务(使用arriveAndDeregister())。与最基本的同步构造一样,注册和注销只影响内部计数;它们不建立任何进一步的内部簿记,因此任务无法查询它们是否已注册。(可以通过将此类子类化来引入这种簿记)
相关参数解释:
phase:当前的周期索引(或者 阶段索引),初始值为0,当所有线程执行完本阶段的任务后,phase就会加一,进入下一阶段;可以结合onAdvance()方法,在不同的阶段,执行不同的屏障方法。
parties:注册的线程数,即Phaser要监控的线程数量,或者说是 建立的屏障的数量。屏障的数量不是固定的,每个阶段的屏障的数量都可以是不一样。
相关方法解释:
register(): 调用该方法会使得 parties 加 1
arriveAndAwaitAdvance(): 阻塞等待其他所有线程执行当前阶段完成才能继续往后执行。
arriveAndDeregister():线程通过栅栏,非阻塞,但是它执行了 deregister 操作,使得 parties 加 1。
arrive():这个方法标记当前线程已经到达栅栏,但是该方法不会阻塞,注意,它不会阻塞。
�
使用案例
Phaser通过register增加阶段,在调用arriveAndAwaitAdvance方法会阻塞等待其他所有线程执行当前阶段完成才能继续往后执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 class MyThread implements Runnable {public MyThread (Phaser phaser, String title) {this .phaser = phaser;this .title = title;new Thread (this ).start();@Override public void run () {"Thread: " + title + " Phase Zero Started" );try {1000 );catch (InterruptedException e) {"Thread: " + title + " Phase One Started" );try {100 );catch (InterruptedException e) {"Thread: " + title + " Phase Two Started" );public class PhaserExample {public static void main (String[] args) {Phaser phaser = new Phaser ();int currentPhase;"Starting" );new MyThread (phaser, "A" );new MyThread (phaser, "B" );new MyThread (phaser, "C" );"Phase " + currentPhase + " Complete" );"Phase Zero Ended" );"Phase " + currentPhase + " Complete" );"Phase One Ended" );"Phase " + currentPhase + " Complete" );"Phase Two Ended" );if (phaser.isTerminated()) {"Phaser is terminated" );
Exchanger(交换者)
线程之间交换数据的一种手段。两个线程可以交换对象的同步点。每个线程在进入交换方法时提供一些对象,并在返回时接收另一个线程提供的对象。
Exchanger(交换者)是一个用于线程间协作的工具类。Exchanger用于进行线程间的数据交换。它提供一个同步点,在这个同步点两个线程可以交换彼此的数据。这两个线程通过exchange方法交换数据, 如果第一个线程先执行exchange方法,它会一直等待第二个线程也执行exchange,当两个线程都到达同步点时,这两个线程就可以交换数据,将本线程生产出来的数据传递给对方。因此使用Exchanger的重点是成对的线程使用exchange()方法,当有一对线程达到了同步点,就会进行交换数据。因此该工具类的线程对象是成对的。
使用案例
exchange方法会进入阻塞状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public class ExchangerExample {static Exchanger<Map<String, String>> exchanger = new Exchanger <>();static class Task implements Runnable {private Map<String,String> map;public Task (Map<String, String> map) {this .map = map;@SneakyThrows @Override public void run () {"当前线程:" +Thread.currentThread().getName()+" 原始数据:" +map);"当前线程:" +Thread.currentThread().getName()+" 交换数据:" +exchange);public static void main (String[] args) {new HashMap <>();"1" ,"a" );"1" ,"b" );new HashMap <>();"3" ,"5" );"4" ,"6" );new Thread (new Task (mapA)).start();new Thread (new Task (mapB)).start();
locks (锁) ReentrantLock
ReentrantLock重入锁,其内部主要通过Sync(AQS的具体实现)、NonfairSync(Sync子类)非公平锁、FairSync(Sync子类)公平锁来实现,构造方法默认是非公平锁。
公平锁:会根据先来后到的顺序获取锁
非公平锁:不会根据先来后到的顺序获取锁
使用案例
ReentrantLockExample
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class ReentrantLockExample {private static ReentrantLock lock = new ReentrantLock (true );public static void main (String[] args) {for (int i = 0 ; i < 5 ; i++) {new Thread (() -> {try {"线程名: " +Thread.currentThread().getName() + " 时间: " + DateUtils.getDate() + " 获取了锁" );1000 );catch (Exception e){finally {"线程名: " +Thread.currentThread().getName() + " 时间: " + DateUtils.getDate() + " 释放了锁" );
StampedLock
StampedLock是JDK1.8出的一种基于功能的锁,具有三种控制读/写访问的模式分别为写锁 writeLock、悲观读锁 readLock、乐观读 Optimistic reading。StampedLock锁的状态由版本和模式组成。锁获取方法返回表示和控制关于锁状态的访问的戳;这些方法的“try”版本可能会返回特殊值零,以表示无法获取访问权限。锁释放和转换方法需要Stamp作为参数,如果它们与锁的状态不匹配,则会失败。
使用案例
StampedLock可直接通过构造函数进行创建
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 public class StampedLockExample {private double x, y;private final StampedLock sl = new StampedLock ();void move (double deltaX, double deltaY) { long stamp = sl.writeLock();try {finally {double distanceFromOrigin () { long stamp = sl.tryOptimisticRead();double currentX = x, currentY = y;if (!sl.validate(stamp)) {try {finally {return Math.sqrt(currentX * currentX + currentY * currentY);void moveIfAtOrigin (double newX, double newY) { long stamp = sl.readLock();try {while (x == 0.0 && y == 0.0 ) {long ws = sl.tryConvertToWriteLock(stamp);if (ws != 0L ) {break ;else {finally {
ReentrantReadWriteLock
可从入的读写锁,基于AQS实现,内部持有read、writer两把锁分别控制读写。
1 2 3 4 5 6 7 8 public class ReentrantReadWriteLock implements ReadWriteLock , java.io.Serializable {private final ReentrantReadWriteLock.ReadLock readerLock;private final ReentrantReadWriteLock.WriteLock writerLock;final Sync sync;
使用案例
RWDictionary
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class CachedData {volatile boolean cacheValid;final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock ();void processCachedData () {if (!cacheValid) {try {if (!cacheValid) {"already init" ;true ;finally {try {finally {
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class RWDictionary {private final Map<String, Data> m = new TreeMap <String, Data>();private final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock ();private final Lock r = rwl.readLock();private final Lock w = rwl.writeLock();public Data get (String key) {try {return m.get(key);finally {public String[] allKeys() {try {return m.keySet().toArray();finally {public Data put (String key, Data value) {try {return m.put(key, value);finally {public void clear () {try {finally {
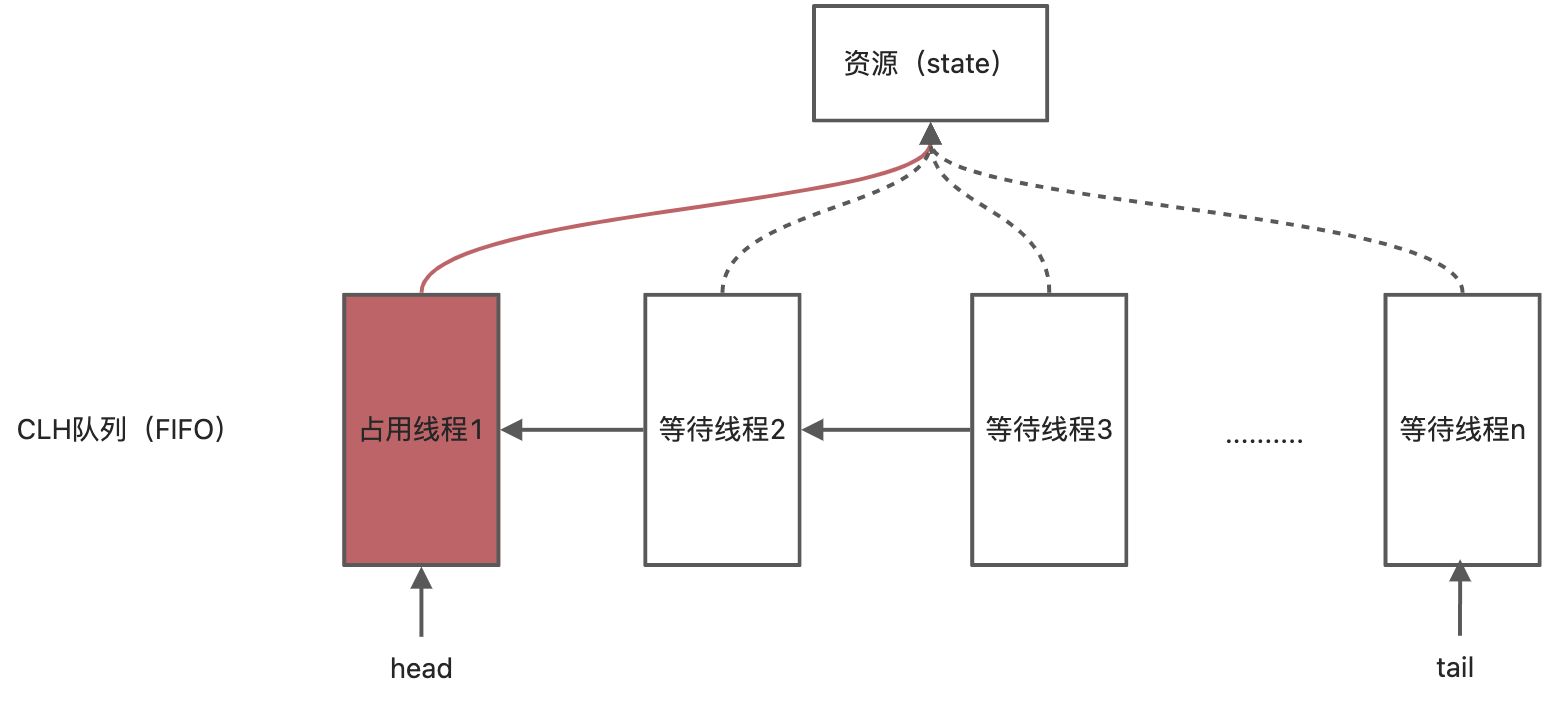
AbstractQueuedSynchronizer
大名鼎鼎的AQS,抽象队列同步器
AQS的原理是依赖于内部的一个volatile修饰的资源变量,CLH队列存储尝试获取锁的线程
1 private volatile int state;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 static final class Node {static final AbstractQueuedSynchronizer.Node SHARED = new AbstractQueuedSynchronizer .Node();static final AbstractQueuedSynchronizer.Node EXCLUSIVE = null ;static final int CANCELLED = 1 ;static final int SIGNAL = -1 ;static final int CONDITION = -2 ;static final int PROPAGATE = -3 ;volatile int waitStatus;volatile AbstractQueuedSynchronizer.Node prev;volatile AbstractQueuedSynchronizer.Node next;volatile Thread thread;final boolean isShared () {return nextWaiter == SHARED;final AbstractQueuedSynchronizer.Node predecessor () throws NullPointerException {Node p = prev;if (p == null )throw new NullPointerException ();else return p;this .nextWaiter = mode;this .thread = thread;int waitStatus) { this .waitStatus = waitStatus;this .thread = thread;
AQS 采用了标准的模版方法 设计模式,对外提供的是以下的方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public final void acquire (int arg) ;public final boolean release (int arg) ;public final void acquireInterruptibly (int arg) throws InterruptedException;public final boolean tryAcquireNanos (int arg, long nanosTimeout) ;public final void acquireShared (int arg) ;public final boolean releaseShared (int arg) ;public final void acquireSharedInterruptibly (int arg) throws InterruptedException;public final boolean tryAcquireSharedNanos (int arg, long nanosTimeout) throws InterruptedException;
以上方法都由final修饰,无法进行重写,提供可重写的方法如下
1 2 3 4 5 6 7 8 protected boolean tryAcquire (int arg) ;protected boolean tryRelease (int arg) ;protected int tryAcquireShared (int arg) ;protected boolean tryReleaseShared (int arg) ;protected boolean isHeldExclusively () ;
获取原理 在获得同步锁时,同步器维护一个同步队列,获取状态失败的线程都会被加入到队列中并在队列中进行自旋;移出队列(或停止自旋)的条件是前驱节点为头节点且成功获取了同步状态。在释放同步状态时,同步器调用** tryRelease(int arg) **方法释放同步状态,然后唤醒头节点的后继节点。
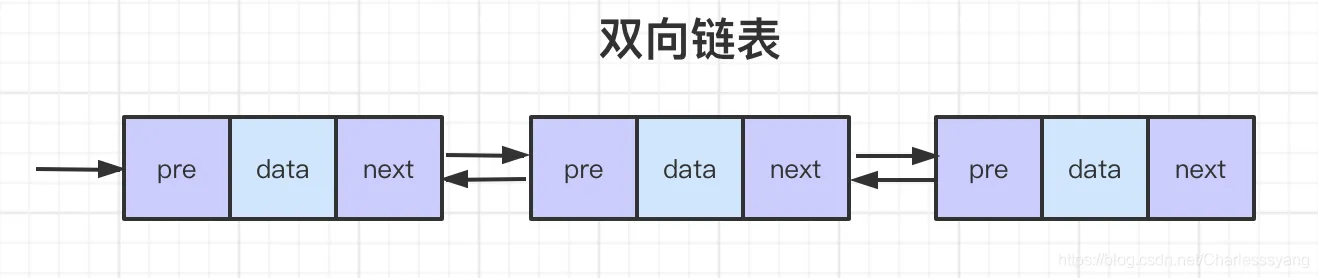
为什么AQS中采用了双向链表的数据结构来存储线程?
检查 :在AQS的注释中有写到,如果next的指向是null则通过prev检查达到双重检查的效果
Link to the successor node that the current node/thread unparks upon release. Assigned during enqueuing, adjusted when bypassing cancelled predecessors, and nulled out (for sake of GC) when dequeued. The enq operation does not assign next field of a predecessor until after attachment, so seeing a null next field does not necessarily mean that node is at end of queue. However, if a next field appears to be null, we can scan prev’s from the tail to double-check
中断 :中断操作需要在 AQS 同步队列中删除线程 Node,这也就转化为在链表中删除节点的问题。如果想从CLH 单向链表中间删除一个 Node,因为只维护了前一个节点的指针,想要知道后一个节点的指针的话,不通过从tail开始使用快慢指针遍历是无法办到的。因此直接维护prev、next指针,以降低删除操作的复杂性。
唤醒 :LCH是一个单项链表,维护前一个节点指针,后继线程轮询前一个节点的状态,从而判断是否可以获取锁。而当多线程竞争时,CLH的轮询是非常耗费性能的,无论是对CPU还是总线来说,都是一种巨大的压力。AQS对CLH进行了改进,后继获取锁的线程在经过有限次的轮询后,依旧获取不到锁将陷入阻塞。优点:减少轮询无效操作;缺点:后继线程Node在阻塞后无法感知前一个线程Node的状态,锁被释放时将无法主动醒来。于是AQS使用了双指针,在CLH的prev基础上增加了next。AQS维护了next指针,以便活跃线程释放锁后主动唤醒后续阻塞线程去竞争锁。
使用案例
Mutex
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 public class Mutex implements Lock , java.io.Serializable {private static class Sync extends AbstractQueuedSynchronizer {protected boolean isHeldExclusively () {return getState() == 1 ;public boolean tryAcquire (int acquires) {assert acquires == 1 ; if (compareAndSetState(0 , 1 )) {return true ;return false ;protected boolean tryRelease (int releases) {assert releases == 1 ; if (getState() == 0 ) throw new IllegalMonitorStateException ();null );0 );return true ;newCondition () {return new ConditionObject ();private void readObject (ObjectInputStream s) throws IOException, ClassNotFoundException {0 ); private final Sync sync = new Sync ();public void lock () {1 );public boolean tryLock () {return sync.tryAcquire(1 );public void unlock () {1 );public Condition newCondition () {return sync.newCondition();public boolean isLocked () {return sync.isHeldExclusively();public boolean hasQueuedThreads () {return sync.hasQueuedThreads();public void lockInterruptibly () throws InterruptedException {1 );public boolean tryLock (long timeout, TimeUnit unit) throws InterruptedException {return sync.tryAcquireNanos(1 , unit.toNanos(timeout));
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public class BooleanLatch {private static class Sync extends AbstractQueuedSynchronizer {boolean isSignalled () {return getState() != 0 ;protected int tryAcquireShared (int ignore) {return isSignalled() ? 1 : -1 ;protected boolean tryReleaseShared (int ignore) {1 );return true ;private final Sync sync = new Sync ();public boolean isSignalled () {return sync.isSignalled();public void signal () {1 );public void await () throws InterruptedException {1 );
LockSupport
这个类与使用它的每个线程相关联,一个许可(在Semaphore 类的意义上)。park如果许可可用,调用将立即返回,并在此过程中使用它;否则可能会阻塞。unpark如果许可证尚不可用,则调用使许可证可用。(但与信号量不同,许可证不会累积。最多有一个。)
方法park并unpark提供有效的阻塞和解除阻塞线程的方法,这些线程不会遇到导致不推荐使用的方法Thread.suspend并且Thread.resume无法用于此类目的的问题:一个线程调用park和另一个尝试调用unpark它的线程之间的竞争将由于许可而保持活力。此外,park如果调用者的线程被中断,将返回,并且支持超时版本。该park方法也可能在任何其他时间“无缘无故”地返回,因此通常必须在循环中调用,该循环在返回时重新检查条件。从这个意义上说park,作为“忙等待”的优化,它不会浪费太多时间,但必须与 an 配对unpark才能有效。
这些方法旨在用作创建更高级别同步实用程序的工具,它们本身对大多数并发控制应用程序没有用处。
使用案例
LockSupport内部提供的都是静态方法,我们通过类名即可调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 public class LockSupportExample {class FIFOMutex {private final AtomicBoolean locked = new AtomicBoolean (false );private final Queue<Thread> waiters = new ConcurrentLinkedQueue <>();public void lock () {boolean wasInterrupted = false ;Thread current = Thread.currentThread();while (waiters.peek() != current || !locked.compareAndSet(false , true )) {this );if (Thread.interrupted()) wasInterrupted = true ;if (wasInterrupted)current.interrupt();public void unlock () {false );
Condition
Condition将Object监视器方法(wait、notify和notifyAll)分解为不同的对象,通过将它们与任意Lock实现的使用结合起来,使每个对象具有多个等待集的效果。
Lock替换了synchronized方法和语句Condition的使用,替换了对象监视器方法的使用。
Condition(也称为条件队列或条件变量)为一个线程提供了一种暂停执行(“等待”)的方法,直到另一个线程通知某个状态条件现在可能为真。因为对这种共享状态信息的访问发生在不同的线程中,所以它必须受到保护,所以某种形式的锁与条件相关联。等待条件提供的关键属性是它以原子方式释放关联的锁并挂起当前线程,就像Object.wait.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public interface Condition {void await () throws InterruptedException;void awaitUninterruptibly () ;long awaitNanos (long nanosTimeout) throws InterruptedException;boolean await (long time, TimeUnit unit) throws InterruptedException;boolean awaitUntil (Date deadline) throws InterruptedException;void signal () ;void signalAll () ;
Condition实例本质上绑定到锁 。要获取Condition特定Lock实例的实例,请使用其newCondition()方法。
例如,假设我们有一个支持put和take方法的有界缓冲区。如果take在空缓冲区上尝试 a ,则线程将阻塞,直到项目可用为止;如果put在一个完整的缓冲区上尝试 a,则线程将阻塞,直到有空间可用。我们希望将等待put线程和take线程保持在单独的等待集中,以便我们可以使用在缓冲区中可用的项目或空间时仅通知单个线程的优化。这可以使用两个Condition实例来实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public class ConditionExample {class BoundedBuffer {final Lock lock = new ReentrantLock ();final Condition notFull = lock.newCondition();final Condition notEmpty = lock.newCondition();final Object[] items = new Object [100 ];int putptr, takeptr, count;public void put (Object x) throws InterruptedException {try {while (count == items.length) notFull.await();if (++putptr == items.length) putptr = 0 ;finally {public Object take () throws InterruptedException {try {while (count == 0 ) notEmpty.await();Object x = items[takeptr];if (++takeptr == items.length) takeptr = 0 ;return x;finally {
锁升级 锁的四种状态:无锁、偏向锁、轻量级锁、重量级锁(级别从高到低)
**无锁: **不存在竞争关系,或者存在竞争关系,但采用非锁的方式即CAS的方式解决
**偏向锁: **对某一个对象第一次上锁时,就是偏向锁,该对象的MarkWord中会存储该线程的ID,可以理解为对象锁认识该线程,可以获取到锁,当多个线程竞争该锁,就会进行锁升级,升为轻量级锁
**轻量级锁: **当锁升级为轻量级锁时,线程会在自己的虚拟机栈中开辟一块称为Lock Record的空间,lock record中会存储对象头中Mark Word的副本以及owner指针,线程会通过CAS尝试获得锁,一但获得锁,就会将Mark Word复制到lock record中,并将owner指针指向该对象,另一方面,该对象的Mark word中的指针会指向获得锁的线程的lock record,就完成了获得获取与绑定。其他的线程想要获取锁,会自旋等待。自旋相当于CPU在空转,会浪费CPU的资源,所以产生了自适应自旋,也就是说自旋的时间不再固定,而是由上一次在同一个锁上自旋的时间和锁的状态共同决定。如果上一次自旋获得过锁,JVM就会认为有机会通过自旋获得锁,就会允许更长时间的自旋来获得锁。
**重量级锁: **如果线程长时间的自旋或等待的线程特别多,就会进行下一步的锁升级,也就是升级与重量级锁,通过操作系统来操作线程。JDK1.6规定的是,线程自旋10次会升级为重量级锁,或等待线程的数量超过CPU合数的1/2,升级为重量级锁
偏向锁 为什么要引入偏向锁?
因为经过hotspot的作者的大量研究发现,大多数时候是不存在锁竞争的,常常是一个线程多次获得同一个锁,因此如果每次都要竞争锁会增大很多没有必要付出的代价,为了降低获取锁的代价,才引入了偏向锁。
偏向锁的升级
当线程1访问同步代码块并获取锁对象时。会在Java对象头和 栈帧中记录偏向锁的threadID,因为偏向锁不会主动释放锁,因此以后线程1再次获取锁的时候,需要比较当前线程的threadID和Java对象头中的threadID是否一致,如果一致,则还是线程1获取锁对象,则无需调用CAS来加锁、解锁;如果不一致(其他线程如线程2要竞争锁对象,而偏向锁不会主动释放,因此存储的还是线程1的threadID),那么需要查看Java对象头中记录的线程1是否存活,如果没有存活,那么锁对象被重置为无锁状态,其他线程可以竞争设置其为偏向锁;如果存活,那么立刻查找该线程的栈帧信息,如果还是需要继续持有这个锁对象,那么暂停线程1,撤销偏向锁,升级为轻量级锁;如果线程1不再使用该锁对象,那么将锁对象状态设置为无锁状态,重新偏向新的线程。
轻量级锁 为什么要引入轻量级锁?
轻量级锁考虑的是竞争锁对象的线程不多,而且线程持有锁的时间也不长的情景。因为阻塞线程需要CPU从用户态切换到内核态,代价较大,如果刚刚阻塞不久这个锁就被释放了,那这个代价就有点得不偿失了,因此这个时候就干脆不阻塞这个线程,让它自旋等待锁释放。
轻量级锁什么时候升级为重量级锁?
线程1获取轻量级锁时会先把锁对象的对象头MarkWord复制一份到线程1的栈帧中创建用于存储锁记录的空间(称为DisplacedMarkWord),然后使用CAS把对象头中的内容替换为线程1存储的锁记录(DisplacedMarkWord)的地址;
如果线程1复制对象头的同时(在线程1CAS之前),线程2也准备获取锁,复制的对象头到线程2的锁记录空间中,但是在线程2CAS的时候,发现线程1已经把对象头换了,线程2CAS失败,那么线程2就尝试使用自旋锁来等待线程1释放锁。
但是如果自旋的时间太长也不行,因为自旋是需要消耗CPU的,因此自旋的次数是有限制的,如果自旋次数达到了限制线程1还没有释放锁,或者线程1还在执行,线程2还在自旋等待,这时候又有一个线程3来竞争这个锁对象,那么这时候轻量级锁就会膨胀为重量级锁。重量级锁把除了拥有锁的线程都阻塞,防止CPU空转。
注意:为了避免无用的自旋,轻量级锁一旦膨胀为重量级锁就不会再降级为轻量级锁了;偏向 锁升级为轻量级锁也不能再降级为偏向锁。一句话就是, 锁升级的过程是不可逆的 。但是偏向锁可以重置为无锁的状态。
重量级锁
锁状态
优点
缺点
适用场景
偏向锁
加锁解锁无需额外的消耗,和非同步方法时间相差纳秒级别
如果竞争的线程多,那么会带来额外的锁撤销的消耗
基本没有线程竞争锁的同步场景
轻量级锁
竞争的线程不会阻塞,使用自旋,提高程序响应速度
如果一直不能获取锁,长时间的自旋会造成CPU的消耗
适用于少量线程竞争锁对象,且线程持有锁的时间不长,追求响应速度的场景
重量级锁
线程竞争不使用CPU自旋,不会导致CPU空转导致消耗CPU资源
线程阻塞,响应时间长
很多线程竞争锁,且锁的持有时间长,追求吞吐量的场景
Memory Consistency Properties (内存一致性关键字) volatile
volatile是JDK提供的关键字,其主要修饰属性(字段)
被volatile修饰的属性具有以下性质不保证原子性
1.不保证原子性
禁止指令重排序:
1 2 3 4 1 XBYTE[2 ]=0x55 ;2 XBYTE[2 ]=0x56 ;3 XBYTE[2 ]=0x57 ;4 XBYTE[2 ]=0x58 ;
对外部硬件而言,上述四条语句分别表示不同的操作,会产生四种不同的动作,但是编译器却会对上述四条语句进行优化,认为只有XBYTE[2]=0x58(即忽略前三条语句,只产生一条机器代码)。如果键入volatile,则编译器会逐一地进行编译并产生相应的机器代码(产生四条代码)。
�
使用案例
volatile只能修饰属性字段
1 private volatile int score;
synchronized
synchronized是JDK提供的关键字,属于JVM层面的锁,其作业范围可以是锁类、代码库、方法。
当它锁定一个方法或者一个代码块的时候,同一时刻最多只有一个线程执行这段代码。当两个并发线程访问同一个对象object中的这个加锁同步代码块时,一个时间内只能有一个线程得到执行。另一个线程必须等待当前线程执行完这个代码块以后才能执行该代码块。然而,当一个线程访问object的一个加锁代码块时,另一个线程仍可以访问该object中的非加锁代码块。
使用案例
可修饰类、代码库、方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class Sync {private Integer num;public synchronized void lockMethod () {synchronized (this ) {synchronized (num){synchronized (Sync.class){
Synchronized是一个重量级锁 Synchronized 是通过对象内部的一个叫做监视器锁(monitor)来实现的,监视器锁本质又是依赖于底层的操作系统的 Mutex Lock(互斥锁)来实现的。而操作系统实现线程之间的切换需要从用户态转换到内核态,这个成本非常高,状态之间的转换需要相对比较长的时间,这就是为什么 Synchronized 效率低的原因。因此这种依赖于操作系统 Mutex Lock 所实现的锁我们称之为 “重量级锁”。
Synchronized底层实现原理 同步方法通过ACC_SYNCHRONIZED 关键字隐式的对方法进行加锁。当线程要执行的方法被标注上ACC_SYNCHRONIZED时,需要先获得锁才能执行该方法。
同步代码块通过monitorenter和monitorexit执行来进行加锁。当线程执行到monitorenter的时候要先获得锁,才能执行后面的方法。当线程执行到monitorexit的时候则要释放锁。每个对象自身维护着一个被加锁次数的计数器,当计数器不为0时,只有获得锁的线程才能再次获得锁。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 biaoyang@biaodeMacBook-Pro synchronize % javap -verbose Sync.class"Sync.java" return return type "Sync.java"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ObjectMonitor () {NULL ;0 ; 0 ,0 ;NULL ;NULL ;NULL ; 0 ;NULL ;NULL ;NULL ;NULL ;NULL ; 0 ;0 ;0 ;
当monitor对象被线程持有时,Monitor对象中的count就会进行+1,当线程释放monitor对象时,count又会进行-1操作。用count来表示monitor对象是否被持有
monitorenter: monitorenter指令表示获取锁对象的monitor对象,这是monitor对象中的count并会加+1,如果monitor已经被其他线程所获取,该线程会被阻塞住,直到count=0,再重新尝试获取monitor对象
monitorexit: monitorexit与monitorenter是相对的指令,表示进入和退出。执行monitorexit指令表示该线程释放锁对象的monitor对象,这时monitor对象的count便会-1变成0,其他被阻塞的线程可以重新尝试获取锁对象的monitor对象
从synchronized放置的位置不同可以得出,synchronized用来修饰方法时,是通过ACC_SYNCHRONIZED标识符来保持线程同步的。而用来修饰代码块时,是通过monitorenter和monitorexit指令来完成
Synchronized锁存储位置
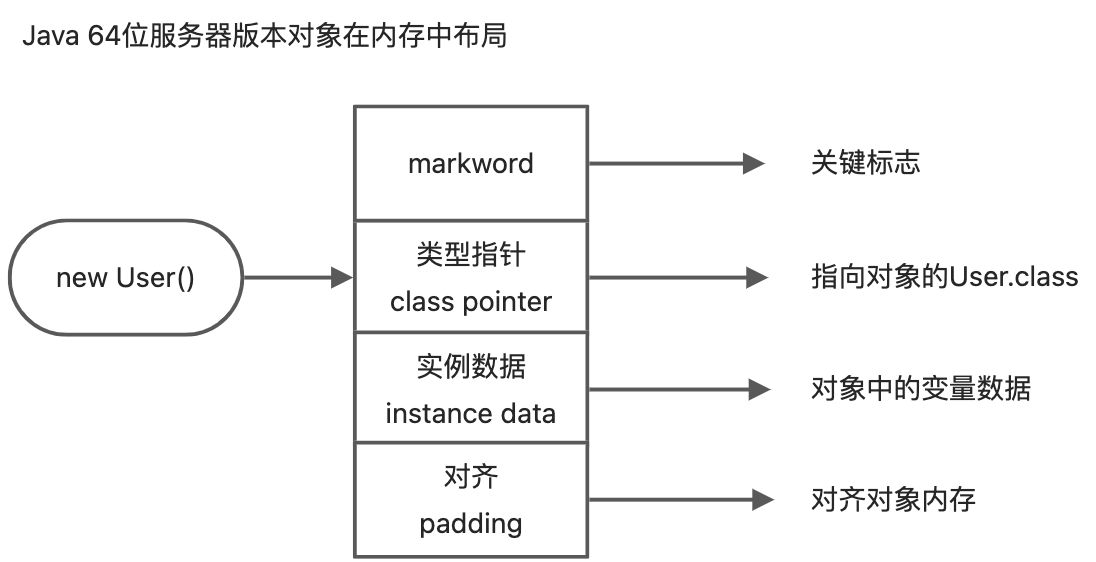
Synchronized用的锁是存在java的对象头里面的。一个对象在new出来之后再内存中主要分为4个部分:
Mark Word:存储了对象的hashCode、GC信息、锁信息三部分。这部分占8字节。
Class Pointer:存储了指向类对象信息的指针。在64位JVM上有一个压缩指针选项-ClassPointer指针:-XX:+UseCompressedClassPointers 为4字节 不开启为8字节。默认是开启的。
实例数据(instance data):记录了对象里面的变量数据。引用类型:-XX:+UseCompressedOops 为4字节 不开启为8字节 Oops Ordinary Object Pointers
Padding:作为对齐使用,对象在64位服务版本中,规定对象内存必须要能被8字节整除,如果不能整除,那么就靠对齐来补。举个例子:new出了一个对象,内存只占用18字节,但是规定要能被8整除,所以padding=6
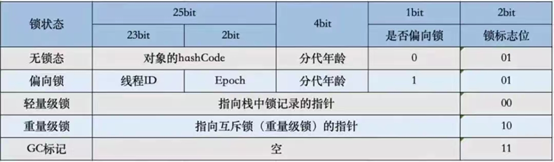
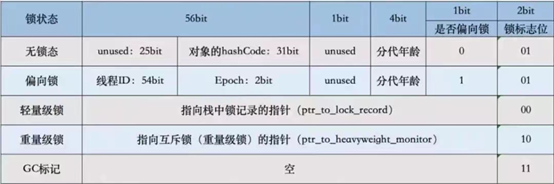
Mark Word存储结构如下:
32位虚拟机下:
64位虚拟机下:
Synchronized锁的升级过程 Java SE 1.6 为了减少获得锁和释放锁带来的性能消耗,引入了 “偏向锁” 和 “轻量级锁”:锁一共有 4 种状态,级别从低到高依次是:**无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态 **。锁可以升级但不能降级。
偏向锁:大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低而引入了偏向锁。当一个线程访问同步块并获取锁时,会在对象头和栈帧中记录存储锁偏向的线程ID,以后该线程在进入同步块时先判断对象头的Mark Word里是否存储着指向当前线程的偏向锁,如果存在就直接获取锁。
轻量级锁:当其他线程尝试竞争偏向锁时,锁升级为轻量级锁。线程在执行同步块之前,JVM会先在当前线程的栈帧中创建用于存储锁记录的空间,并将对象头中的MarkWord替换为指向锁记录的指针。如果成功,当前线程获得锁,如果失败,标识其他线程竞争锁,当前线程便尝试使用自旋来获取锁。
重量级锁:锁在原地循环等待的时候,是会消耗CPU资源的。所以自旋必须要有一定的条件控制,否则如果一个线程执行同步代码块的时间很长,那么等待锁的线程会不断的循环反而会消耗CPU资源。默认情况下锁自旋的次数是10 次,可以使用-XX:PreBlockSpin参数来设置自旋锁等待的次数。10次后如果还没获取锁,则升级为重量级锁。
资料
https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/package-summary.html#package.description http://mishadoff.com/blog/java-magic-part-4-sun-dot-misc-dot-unsafe/ https://people.apache.org/~tellison/classlib_doc/html/classjava_1_1util_1_1concurrent_1_1Executors.html https://zhuanlan.zhihu.com/p/370381079