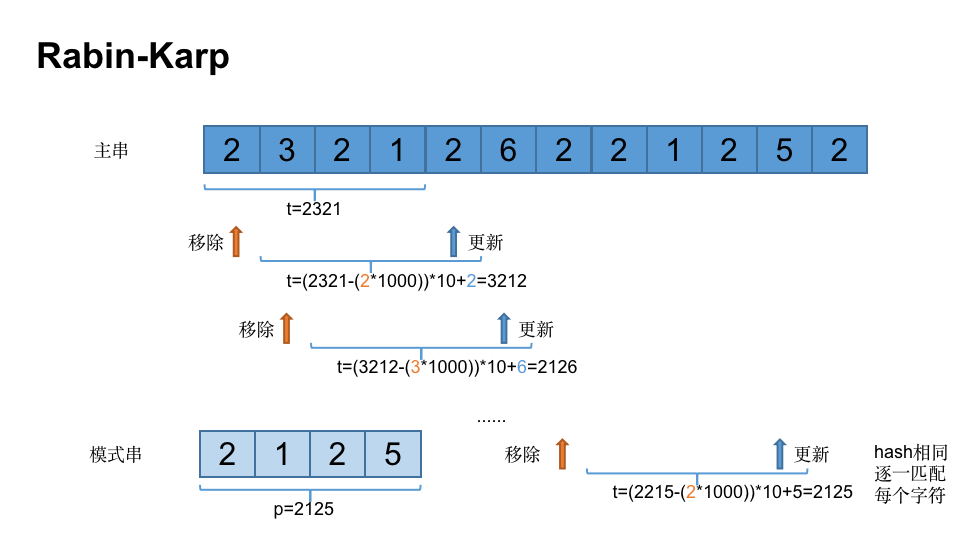
staticvoidsearch(String pattern, String txt, int q) { intm= pattern.length(); intn= txt.length(); int i, j; intp=0; intt=0; inth=1; for (i = 0; i < m - 1; i++) h = (h * d) % q; //计算模式串和主串的hash for (i = 0; i < m; i++) { p = (d * p + pattern.charAt(i)) % q; t = (d * t + txt.charAt(i)) % q; } // 查找匹配 for (i = 0; i <= n - m; i++) { //如果hash相同则比较每个字符 if (p == t) { for (j = 0; j < m; j++)if (txt.charAt(i + j) != pattern.charAt(j))break; //全部匹配成功 if (j == m)System.out.println("匹配位置: " + (i + 1)); } //如果还存在可以匹配的长度,继续下移匹配 if (i < n - m) { //计算hash t = (d * (t - txt.charAt(i) * h) + txt.charAt(i + m)) % q; if (t < 0)t = (t + q); } } } }
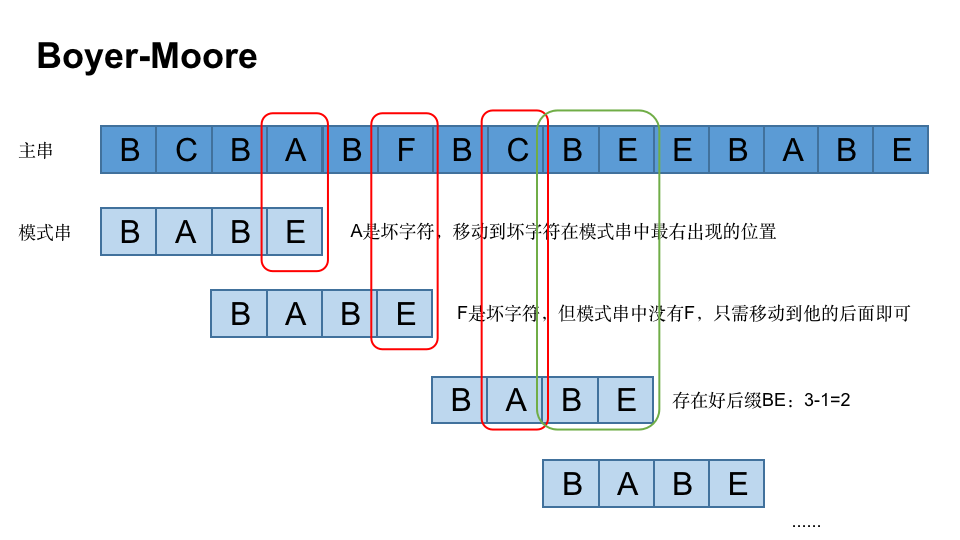
staticvoidbadCharHeuristic(char[] str, int size, int badchar[]) { for (inti=0; i < NO_OF_CHARS; i++) badchar[i] = -1; for (inti=0; i < size; i++) badchar[str[i]] = i; }
for (i = 0; i < ASIZE; ++i) bmBc[i] = m; for (i = 0; i < m - 1; ++i) bmBc[x[i]] = m - i - 1; }
voidsuffixes(char *x, int m, int *suff) { int f, g, i;
suff[m - 1] = m; g = m - 1; for (i = m - 2; i >= 0; --i) { if (i > g && suff[i + m - 1 - f] < i - g) suff[i] = suff[i + m - 1 - f]; else { if (i < g) g = i; f = i; while (g >= 0 && x[g] == x[g + m - 1 - f]) --g; suff[i] = f - g; } } }
voidpreBmGs(char *x, int m, int bmGs[]) { int i, j, suff[XSIZE];
suffixes(x, m, suff);
for (i = 0; i < m; ++i) bmGs[i] = m; j = 0; for (i = m - 1; i >= 0; --i) if (suff[i] == i + 1) for (; j < m - 1 - i; ++j) if (bmGs[j] == m) bmGs[j] = m - 1 - i; for (i = 0; i <= m - 2; ++i) bmGs[m - 1 - suff[i]] = m - 1 - i; }
voidBM(char *x, int m, char *y, int n) { int i, j, bmGs[XSIZE], bmBc[ASIZE];
/* Preprocessing */ preBmGs(x, m, bmGs); preBmBc(x, m, bmBc);
/* Searching */ j = 0; while (j <= n - m) { for (i = m - 1; i >= 0 && x[i] == y[i + j]; --i); if (i < 0) { OUTPUT(j); j += bmGs[0]; } else j += MAX(bmGs[i], bmBc[y[i + j]] - m + 1 + i); } }