读书笔记篇-Java并发编程实战

第1章 介绍
1.1 并发的(非常)简短历史
在发展的初期,计算机还没有操作系统;它们自始至终执行一个程序,这个程序直接访问机器的所有资源。这样-个程序运行 在无保护的金属器件上,不仅写起来困难,而且每次只运行一个程序,不能很好地利用昂贵且稀缺的计算机资源。
操作系统的发展使得多个程序能够同时运行,程序在各自的进程(processes)中运行:相互分离,各自独立执行,由操作系统来分配资源,比如内存、文件句柄、安全证书。
如果需要的话,进程会通过-些原始的机制相互通信: Socket. 信号处理(signal handlers)、共享内存(shared memory)、信号量(semaphores) 和文件。
1.2 线程的优点
恰当的使用线程,可以降低开发和维护的开销,线程通过异步的工作流程转化为普遍存在的顺序流程,使程序模拟人类和交互变得容易。
因为程序调度的基本单位是线程,一个单线程应用程序一次只能运行在一个处理器上。在双核处理器系统中,一个单线程程序,放弃了其中一半的空闲CPU资源。如果让每个CPU都得到有效的利用,其效率更加高。
1.3 线程的风险
- 安全危险
- 活跃度的危险
- 性能危险
1.4 线程无处不在
通过从框架线程中调用应用程序的组件,框架把并发引入了应用程序。组件总是需要访问程序的状态。因此要求在所有的代码路径访问状态时,必须是线程安全的。
第2章 线程安全
无论何时,只要有多于一个的线程访问给定的状态变量,而且其中某个线程会写入该变量,此时必须使用同步来协调线程对该变量的访问。
2.1 什么是线程安全性
当多个线程访问一个类时,如果不用考虑这些线程在运行时环境下的调度和交替执行,并且不需要额外的同步及在调用方代码不必作其他的协调,这个类的行为仍然是正确的,那么称这个类是线程安全的。
有状态对象(Stateful Bean) :就是有实例变量的对象,可以保存数据,是非线程安全的。每个用户有自己特有的一个实例,在用户的生存期内,bean保持了用户的信息,即“有状态”;一旦用户灭亡(调用结束或实例结束),bean的生命期也告结束。即每个用户最初都会得到一个初始的bean。
无状态对象永远是线程安全的。多数Servlet都可以实现为无状态的,这一事实 极大地降低了确保Servlet线程安
全的负担,只有当Servlet要为不同的请求记录一些信 息时,才会将线程安全的需求提到日程上来。
2.2 原子性
原子性,顾名思义就是不可再分的单位。在这里指的是原子操作,其指的是在对数据操作的过程中不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch (切换到另一个线程)
竞争条件
当计算的正确性依赖于运行时中相关的时许或者多线程的交替时,会产生竞争条件。
最常见的竞争条件是“检查再运行”(check then act),使用一个潜在的过期值作为决定下一步操作的依据。
检查再运行的的常用用法就是惰性初始化,惰性初始化的目的是延迟对象的初始化,直到程序真正使用它,同时确保它只初始化**一次**。
复合操作
将“检查再运行”和“读-写-改”操作的全部执行过程看作是复合操作
假设有操作A和B,如果从执行A的线程的角度看,当其他线程执行B时,要么B全部执行完成,要么一点都没有执行,这样A和B互为原子操作。一个原子操作是指:该操作对于所有的操作,包括它自己,都满足前面描述的状态。
2.3 锁
为了保护状态的一致性,要在单一的原子操作中更新相互关联的状态变量。
内部锁
Java提供了强制原子性的内置锁机制:synchronized块。有两种作用:1.是锁饮用的对象 2.锁代码块。
每个Java对象都可以隐式地扮演一个用于同步的锁的角色:这些内置的锁被称作内部锁(intrinsic locks)或监视器锁(monitor locks)。执行线程进入synchronized块之前会自动获得锁;而无论通过正常控制路径退出,还是从块中抛出异常,线程都在放弃对synchronized块的控制时自动释放锁。获得内部锁的唯一途径是: 进入这个内部锁保护的同步块或方法。
内部锁在Java中扮演了互斥锁(mutual exclusion lock,也称作mutex)的角色,意味着至多只有一个线程可以拥有锁,当线程A尝试请求一个被线程B占有的锁时,线程A必须等待或者阻塞,直到B释放它。如果B永远不释放锁,A将永远等下去。
重进入(Reentrancy)
当一个线程请求其他线程已经占有的锁时,请求线程将被阻塞。然而内部锁是可重进入的,因此线程在试图获得它自已占有的锁时,请求会成功。重进入意味着所的请求是基于“每线程(per-thread) ”,而不是基于“每调用(per invocation) ”的。重进入的实现是通过为每个锁关联-个请求计数(acquisition count)和-个占有它的线程。当计数为0时,认为锁是未被占有的。线程请求-个未被占有的锁时,JVM将记录锁的占有者,并且将请求计数置为1。如果同一线程再次请求这个锁,计数将递增:每次占用线程退出同步块,计数器值将递减。直到计数器达到0时,锁被释放。
2.4 用锁来保护状态
对于每个可被多个线程访问的可变状态变量,如果所有访问它的线程在执行时都占有同一个锁,这种情况下,我们称这个变量是由这个锁保护的。
对象的内部锁与它的状态之间没有内在的关系。尽管大多数类普遍使用这样一种非常有效的锁机制:
用对象的内部锁来保护所有的域,然而这并不是必需的。即使获得了与对象关联的锁也不能阻止其他线程访问这个对象一-获得 对象的锁后,唯-可以做的事情是阻止其他线程再获得相同的锁。作为一种便利, 每个对象都有一个内部锁,所以你不需要显式地创建锁对象。你可以构造自己的锁协议或同步策略,使你可以安全地访问共享状态,并且贯穿程序都始终如一地使用它们。
每个共享的可变变量都需要由唯一一个确定 的锁保护。而维护者应该清楚这个锁。
锁保护的变量,意味着每次访问变量都需要获得改锁,确保在同一时刻只有一个线程可以访问这个变量。
2.5 活跃度与性能
上图表示多个请求到达同步的Factoring Servlet时所发生的事情:这些请求排队等候并依次被处理。我们把这种Web应用的运行方式描述为**弱并发(poor concurrency) **的。
一种表现:限制并发调用数量的,并非可用的处理器资源,而恰恰是应用程序自身的结构。幸运的是,通过缩小synchronized块的范围来维护线程安全性,我们很容易提升Servlet的并发性。你应该谨慎地控制synchronized块不要过小:你不可以将-个原子操作分解到多个synchronized块中。不过你应该尽量从synchroni zed块中分离耗时的且不影响共享状态的操作。这样即使在耗时操作的执行过程中,也不会阻止其他线程访问共享状态。
有些耗时的计算或操作,比如网络或控制台I/O,难以快速完成。执行这些操作期间不要占有锁。
第3章 共享对象
3.1 可见性
Java内存模型(JMM)
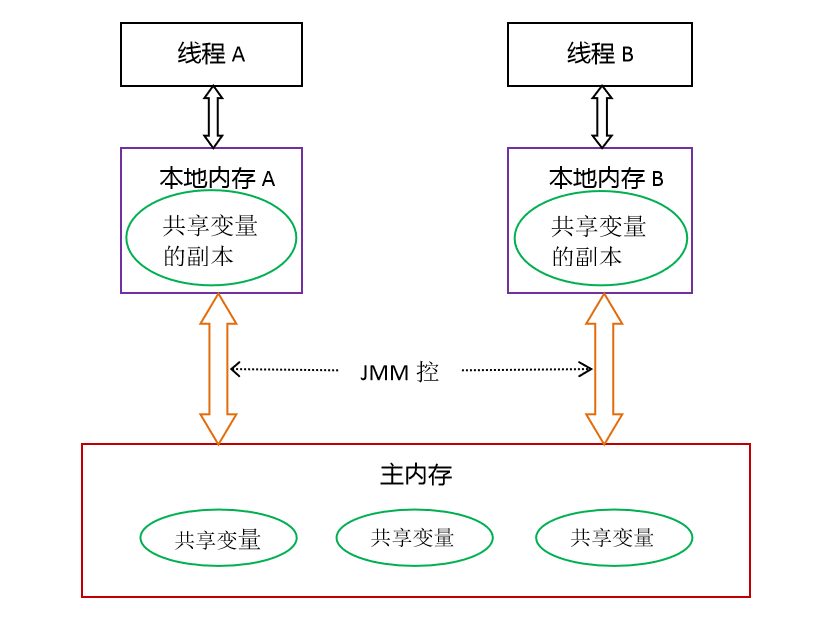
Java的内存模型如上图所示,在多线程进行操作数据的时候,会先从主内存中拷贝一份到自己的工作内存中,在处理数据完成后,再将其写入主内存中,完成操作。
过期数据
当线程读取数据时,可能读取到的是一个过期的数据,除非每一次访问数据都是同步的,否则很肯读取到过期数据。
非原子的64位操作
当一个线程在没有同步的情况下读取变量,它可能会得到一个过期值。但是至少它可以看到某个线程在那里设定的一个真实数值,而不是一个凭空而来的值。这样的安全保证被称为是最低限的安全性(out- of-thin- air safety)
最低限的安全性应用于所有的变量,除了一个例外:没有声明为volatile的64位数值变量(double 和long) 。Java存储模型要求获取和存储操作都为原子的,但是对于非volatile的long和double变量,JVM允许将64位的读或写划分为两个32位的操作。如果读和写发生在不同的线程,这种情况读取-一个非volatile类型long就可能会出现得到一个值的高32位和另一个值的低32位3。因此,即使你并不关心过期数据,但仅仅在多线程程序中使用共享的、可变的long 和double变量也可能是不安全的,除非将它们声明为volatile类型,或者用锁保护起来。
锁和可见性
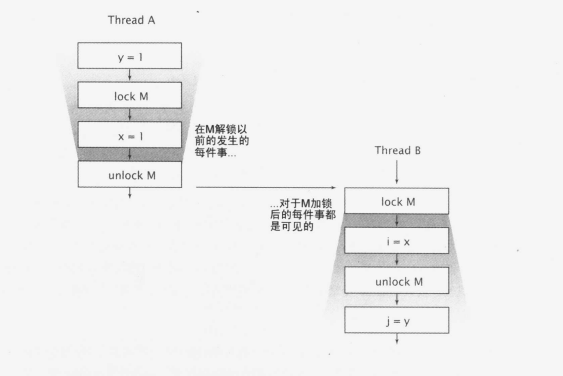
当访问一个共享的可变变量时,为什么要求所有线程由同一个锁进行同步,我们现在可以给出另一个理由一为 了保证一个线程对数值进行的写入,其他线程也都可见。另一方面,如果一个线程在没有恰当地使用锁的情况下读取了变量,那么这个变量很可能是一个过期的数据。
锁不仅仅是关于同步与互斥的,也是关于内存可见的。为了保证所有线程都能够看到共享的、可变变量的最新值,读取和写入线程必须使用公共的锁进行同步.
volatile变量
在Java中volatile关键字确保对一个变量的更新以可预见的方式告知其他线程。
加锁可以保证可见性与原子性; volatile 变量只能保证可见性。
只有满足了下面所有的标准后,你才能使用volatile变量:
- 写入变量时 并不依赖变量的当前值:或者能够确保只有单一的线程修改变量的值:
- 变量不需 要与其他的状态变量共同参与不变约束;
- 而且,访问变量时,没有其他的原因需要加锁。
发布和逸出
发布(publishing)一个对象的意思是使它能够被当前范围之外的代码所使用。比如将一个引用存储到其他代码可以访问的地方,在-一个非私有的方法中返回这个引用,也可以把它传递到其他类的方法中。在很多情况下,我们需要确保对象及它们的内部状态不被暴露(publish)。在另外-些情况下,为了正当的使用目的,我们又的确希望发布一个对象,但是用线程安全的方法完成这些工作时,可能需要同步。如果变量发布了内部状态,就可能危及到封装性,并使程序难以维持稳定:如果发布对象时,它还没有完成构造,同样危及线程安全。一个对象在尚未准备好时就将它发布,这种情况称作逸出(escape) 。
让我们看看一个对象是如何逸出的。
最常见的发布对象方式就是将对象的引用存储到公共静态域中,任何类和线程都可以看到这个域。
1 | |
不要让this引用在构造期间逸出。
3.3 线程封闭
访问共享的、可变的数据要求使用同步。-个可以避免同步的方式就是不共享数据。如果数据仅在单线程中被访问,就不需要任何同步。线程封闭(Thread confinement)技术是实现线程安全的最简单的方式之-。 当对象封闭在一个线程中时,这种做法会自动成为线程安全的,即使被封闭的对象本身并不是。
Swing发展了线程封闭技术。Swing的可视化组件和数据模型对象并不是线程安全的,它们是通过将它们限制到Swing 的事件分发线程中,实现线程安全的。为了正确地使用Swing,运行在不同于事件线程(event thread)的其他线程中的代码不应该访问这些对象(为了简化这些, Swing提供了invokelater 机制,用于在事件线程中安排执行Runnable实例)。
Ad-hoc线程限制
Ad-boc线程限制10 是指维护线程限制性的任务全部落在实现上的这种情况。因为没有可见性修饰符与本地变量等语言特性协助将对象限制在目标线程上,所以这种方式是非常容易出错的。事实上,对于像GUI应用中的可视化组件或者数据模型这些线程限制对象,对它们的引用通常是公用域。
如果决定将一个像GUI这样特定的子系统实现为“单线程化”的子系统,通常就要使用线程限制技术。单线程化子系统有时所带来的简便性的好处远远胜过ad-hoc线程限制的易损性”。
线程限制的一种特例是将它用于volatile 变量。只要你确保只通过单一线程写入共享的volatile变量,那么在这些volaile变量上执行“读-改-写”操作就是安全的。在这种情况下,你就将修改操作限制在单- -的线程中, 从而阻止了竞争条件。并且,可见性保证volatile变量能够确保其他线程能看到最新的值。
鉴于ad-hoc线程限制固有的易损性,因此应该有节制地使用它。如果可能的话,用一种线程限制的强形式(栈限制或者Thread Local)取代它。
栈限制
栈限制是线程限制的一种特例,在栈限制中,只能通过本地变量才可以触及对象。正如封装使不变约束更容易被保持,本地变量使对象更容易被限制在线程本地中。本地变量本身就被限制在执行线程中:它们存在于执行线程栈。其他线程无法访问这个栈。
栈限制(也称线程内部或者线程本地用法,但是不要与核心库类的ThreadLocal混淆)与ad-hoc线程限制相比,更易维护,更健壮。.
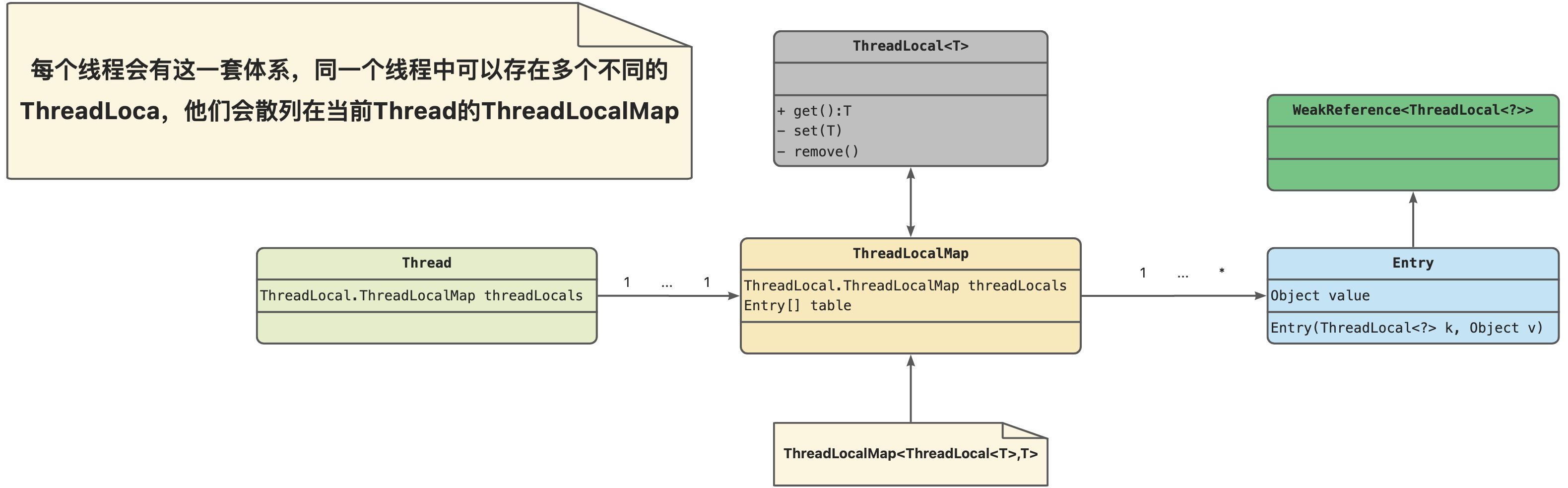
ThreadLocal
一种维护线程限制的更 加规范的方式是使用ThreadLocal,它允许你将每个线程与持有数值的对象关联在一起。ThreadLocal提供了get与set访问器,为每个使用它的线程维护一份单独的拷贝。所以get总是返回由当前执行线程通过set设置的最新值。
线程本地(Thread Local)变量通常用于防止在基于可变的单体(Singleton) 或全局变量的设计中,出现(不正确的)共享。比如说,一个单线程化的应用程序可能会维护-个全局的数据库连接,这个Connection在启动时就已经被初始化了。这样就可以避免为每个方法都传递一个Connection. 因为JDBC规范并未要求Connection;自身一定是线程安全的,因此,如果没有额外的协调时,使用全局变量的多线程应用程序同样不是线程安全的。通过利用ThreadLocal存储JDBC连接,每个线程都会拥有属于自己的Connection.

ThreadLocal的ThreadLocalMap�中key为什么使用WeakReference ?
1 | |
可以看到Entry是继承WeakReference(弱引用类型),其传入的ThreadLocal<?>(也就是key)在GC时会被收集掉,但value并不是,那为啥要这么设计呢 ?
WeakReference的定义是如果没有强引用指向它,在JVM进行GC的时候会被收集掉(无论内存是否满)
设计原理
先来看看ThreadLocal的组成,可以发现ThreadLocal类中的**ThreadLocalMap�是由Thread类持有的**,每个Thread有自己的ThreadLocalMap实例,ThreadLocalMap的键是ThreadLocal,值是 T,也就是说在当前线程中可以存在多个ThreadLoca存储与ThreadLocalMap中。其生命周期也就是说只有线程Thread被销毁了,其ThreadLocalMap才会被回收。
1 | |
get方法,获取值时是通过先拿到当前线程,再获取当前线程中的ThreadLocalMap,再通过当前ThreadLocal类作为key去获取对应的value
1 | |
set方法
1 | |
remove方法
1 | |
从上面的的三个方法中get、set、remove中都会去调用expungeStaleEntry�方法,其实这个方法就是清理无引用的value(或者是被GC收集掉key的value)
现在我们再回过头来看我们的问题 ,为什么ThreadLocalMap的key是weakReference类型的 ?
首先如果我们代码中对ThreadLocal已经无需使用了,那么在ThreadLocalMap中的key也就没有强引用了,所以在GC时就会被收集掉了,同时我们的get、set、remove 方法进行操作时也是根据key==null来清理value的,所以其作用体现在这里。
如果我的ThreadLocal没有被回收但是他的key却被GC收集掉了会不会无法获取到我需要的值?不会的大哥,只要你还有非弱引用指向ThreadLocal就不会被回收的
1 | |
所以说key设置为weakReference是在一定程度上防止发生内存泄露的,方便对象的回收。
Entry为啥还要存储key ? 这个就比较简单了主要是为了解决在我们进行哈希的时候可能会有冲突,ThreadLocal会往后去查找空桶,在get的时候通过key进行匹配。
什么情况下使用ThreadLocal会产生内存泄露 ?这种情况当然是存在的,当你不正确使用时,如直接将ThreadLocal引用指向空,就会导致内存泄露后内存溢出
1 | |
3.4 不可变性
不可变对象永远是线程安全的。
只有满足如下状态,一个对象才是不可变的:
- 它的状态不能在创建后再被修改;
- 所有城都是final类型3:并且,
- 它被正确创建(创建期间没有发生this引用的逸出)。
从技术上讲,不可变对象的城并未全部声明为final类型,这样的情况是可能存在的,string就是这种类。设计这种类依赖于对良性数据竞争的精准分析,还需要对Java存储模型有深入的理解。(满足一 下你的好奇心: string会惰性地 (Lazily)计算哈希值:当第一次调用hashcode时,string计算哈希值,并将它缓存在一个非final域中。之所以可以这样做,仅是因为这个城所表现的非默认的( nondefault)值,在每次计算后都得到相同的结果,因为该结果来自一个已经确定的不可变的状态。但请不要自己这样做! )
Final域
final关键字源于C++的const机制,不过受到了更多的限制。它对不可变性对象的创建提供了支持。final 域是不能修改的(尽管如果final 域指向的对象是可变的,这个对象仍然可被修改),然而它在Java存储模型中还有着特殊的语义。final域使得确保初始化安全性(initialization safety) 成为可能,初始化安全性让不可变性对象不需要同步就能自由地被访问和共享。
3.5 安全发布
不可变对象可以在没有额外同步的情况下,安全地用于任意线程;甚至发布它们时亦不需要同步。
如果一个对象不是不可变的,它就必须被安全地发布,通常发布线程与消费线程都必须同步化。此刻让我们关注一下, 如何确保消费线程能够看到处于发布当时的对象状态;我们要解决对象发布后对其修改的可见性问题。
为了安全地发布对象,对象的引用以及对象的状态必须同时对其他线程可见。
一个正确创建的对象可以通过下列条件安全地发布:
- 通过静态初始化器初始化对象的引用;
- 将它的引用存储到volatile域或AtomicReference;
- 将它的引用存储到正确创建的对象的final域中;
- 或者将它的引用存储到由锁正确保护的城中。
第4章组合对象
4.1设计线程安全的类
三要素
- 确定对象状态由哪些变量构成的。
- 确定限制状态变量的不变约束。
- 制定一个管理并发访问对象状态的策略。
如果对象的域都是基本类型(primitive)的,那么这些域就组成了对象的完整状态。如果一个对象的域引用了其他对象,那么他的状态也同时包含了被引用对象的域。LinkedList的状态包括了所有存储在链表中的节点对象的状态。
同步策略(synchronization policy)
定义了对象如何协调对其状态的访问,并且不会违反他的不变约束或后验条件。它规定了如何把不可变性、线程限制和锁结合起来,从而维护线程的安全性,还指明了哪些锁保护哪些变量。为了保证开发者于维护者可以分析并维护类,应该将类的同步策略写入文档。
4.2实例限制
即使一个对象不是线程安全的,仍有许多技术可以让它安全的用于多线程程序。比如你可以确保它只被单一的线程访问(线程限制),也可以确保所有的访问都正确的被锁保护。
将数据封装走对象内部,把对数据的访问限制在对象的方法上,更易确保线程在访问数据时总能获得正确的锁。
限制性使构造线程安全的类变得更容易,因为类的状态被限制后,分析它的线程安全时,就不必检查完整的程序。
Java监视器模式
线程限制原则的直接推论之一是Java监视器(Java monitor pattern)。遵循Java监视器模式的对象封装了所有的可变状态,并由对象自己的内部锁保护。
私有锁保护状态
1 | |
使用私有锁对象,而不是对象的内部锁(或任何其他可公共访问的锁),有很多好处。私有的锁对象可以封装锁,这样客户代码无法得到它。然而可公共访问的锁允许客户代码涉足它的同步策略一-正 确地或不正确地。客户不正确地得到另一一个对象的锁,会引起活跃度方面的问题。另外要验证程序是正确地使用着一个可公共访问的锁,需要检查完整的程序,而不是一个单独的类。
4.3委托线程安全
可以将线程的安全委托于一些安全的类或者容器、如JUC下的一些并发类。
非状态依赖变量
我们可以将线程安全委托到多个隐含的状态变量上,只要这些变量彼此独立的,这意味组合对象并未增加任何涉及多个状态变量的不变约束。
当委托无法胜任时
如果一个类由多个彼此独立的线程安全的状态变量组成,并且类的操作不包含任何无效状态转换时,可以将线程安全委托给这些状态变量。
4.4向已有的线程安全类添加功能
- 客户端加锁
对于一个由Collections.synchronizedList封装的ArrayList,向原始类中加入方法或者拓展类都不正确,因为客户代码不知道同步封装工厂方法返回List对象的类型。第三个策略是拓展功能,而不是拓展类本身,并将拓展代码置入一个“助手(helper)”类。
1 | |
4.5同步策略的文档化
为类的用户编写类线程安全性担保的文档;为类的维护编写类的同步策略文档。
第5章构建块
5.1同步容器
- Vector
- Hashtable
- Collections.synchronizedXxx工厂方法创建的容器
5.2并发容器
用并发容器替换同步容器,这种做法以很小的风险带来了可拓展性显著的提高。
ConcurrentHashMap
�同步容器类在每个操作的执行期间都持有一个锁。有-些操作,比如HashMap.get或者List.contains,可能会涉及到比预想更多的工作量:为寻找一个特定对象而遍访整个哈希容器或清单,必须调用大量候选对象equals(equals本身还涉及相当数量的计算)。在一个哈希容器中,如果hashCode没有能很好地分散哈希值,元素很可能不均衡地分布到整个容器中:最极端的情况是,一个不良的哈希函数将会把一个哈希表转化为一个线性链表。遍历一个很长的清单并调用其中部分或者全部元素的equals方法,这会花费很长时间,并且在这段时间内,其他线程都不能访问这个容器。
ConcurrentHashMap和HashMap一样是个哈希表,但是它使用了完全不同的锁策略,可以提供更好的并非性和可伸缩性。
总体设计
ConcurrentHashMap的设计主要是对HashMap进行
插入元素分析
1 | |
CopyOnWriteArrayList
CopyOnWriterrayList是同步List的一个并发替代品,通常情况下它提供了更好的并发性,并避免了在迭代期间对容器加锁和复制。( 相似地,CopyOnWriteArraySet是同步set的一个并发替代品。)
“写入时复制(copy-on-write) ”容器的线程安全性来源于这样一个事实,只要有效的不可变对象被正确发布,那么访问它将不再需要更多的同步。**在每次需要修改时,它们会创建并重新发布一个新的容器拷贝,以此来实现可变性**。“写入时复制(copy-on-write)”容器的迭代器保留一个底层基础数组(the backing aray)的引用。这个数组作为迭代器的起点。
5.3阻塞队列和生产者-消费者模式
阻塞队列提供可阻塞的put和take方法,他们与可定时的offer和poll是等价的。如果Queue已经满了,则put方法被阻塞到有用空间。如果Queue是空的那么take方法会被阻塞,直到有元素可用。Queue的长度可以有限也可以无限,无线长度Queue永远不会满,put方法永远不会阻塞。
阻塞队列支持**生产者-消费者设计模式**。

BlockingQueue的实现是SynchronousQueue,它根本上不是一个真正的队列,因为他不会为队列元素维护任何存储空间。不过他维护的是一个排队的线程清单,这些线程等待把元素加入(enqueue)队列或者移出(dequeue)队列。
双端队列
Dequeue是一个双端队列,允许高效的在头和尾分别进行插入和移除。实现有ArrayDeque和LinkedBlockingDeque
5.4阻塞和可中断的方法
线程中断的原因
- 等待I/O操作结束
- 等待获得一个锁
- 等待从Thread.sleep中唤醒
- 等待另一个线程线程的计算结果
Thread提供了Interrupt方法,用来中断一个线程,或者查询某线程是否已经被中断。
5.5 Synchronizer
阻塞队列在容器类中是独一无二的:它们不仅作为对象的容器,而且能够协调生产者线程和消费者线程之间的控制流,这是因为take和put会保持阻止状态直到队列进入了期望的状态(不空也不满)。
Synchronizer是一个对象,它根据本身的状态调节线程的控制流。阻塞队列可以扮演一个Synchronizer的角色;其他类型的Synchronizer包括信号量( semaphore)、关卡( barrier)以及闭锁(latch)。在平台类库中存在一些Synchronizer类;如果这些不能满足你的需要,你同样可以创建-个你自己的Synchronizer。
所有Synchronizer都享有类似的结构特性:它们封装状态,而这些状态决定着线程执行到在某-点时是通过还是被迫等待;它们还提供操控状态的方法,以及高效地等待Synchronizer进入到期望状态的方法。
闭锁
闭锁(latch)是一-种 Synchronizer,它可以延迟线程的进度直到线程到达终止( terminal)状态[CPJ3.4.2] 。一个闭锁工作起来就像- -道大门:直到闭锁达到终点状态之前,门一直是关闭的,没有线程能够通过,在终点状态到来的时候,门开了,允许所有线程都通过。一但闭锁到达了终点状态,它就不能够再改变状态了,所以它会永远保持敞开状态。闭锁可以用来确保特定活动直到其他的活动完成后才发生,比如:
- 确保一个计算不会执行,直到它需要的资源被初始化。一个二元闭锁(两个状态)可以用来表达“资源R已经被初始化”,并且所有需要用到R的活动首先都要在闭锁中等待。
- 确保一个服务不会 开始,直到它依赖的其他服务都已经开始。每-个服务会包含一个相关的二元闭锁;开启服务S会首先开始等待闭锁S中所依赖的其他服务,在启动结束后,会释放闭锁S,这样所有依赖S的服务也可以开始处理了。
- 等待,直到活动的所有部分都为继续处理作好充分准备,比如在多玩家的游戏中的所有玩家是否都准备就绪。这样的闭锁会在所有玩家准备就绪时,达到终点状态。
CountDownLatch
CountDownLatch是一个灵活的闭锁实现,用于, 上述各种情况;允许一个 或多个线程等待一个事件集的发生。闭锁的状态包括一个计数器,初始化为一个正数,用来表现需要等待的事件数。
countDown方法对计数器做减操作,表示一个事件已经发生了,而await方法等待计数器达到零,此时所有需要等待的事件都已发生。如果计数器入口时值为非零,await会一直阻塞直到计数器为零,或者等待线程中断以及超时。
FutureTask
FutureTask同样可以作为闭锁。FutureTask 的计算是通过Callable实现的,它等价于一个可携带结果的Runnable,并且有3个状态:等待、运行和完成。完成包括所有计算以任意的方式结束,包括正常结束、取消和异常。一旦FutureTask进入完成状态,它会永远停止在这个状态上。Future.get的行为依赖于任务的状态。如果它已经完成,get可以立刻得到返回结果,否则会被阻塞直到任务转入完成状态,然后会返回结果或者抛出异常。FutureTask 把计算
1 | |
Executor框架利用FutureTask来完成异步任务,并可以用来进行任何潜在的耗时计算,而且可以在真正上需要计算结果之前就启动他们开始计算。
信号量
计数信号量用来控制能够访问某特定资源的活动的数量,或者同时执行某一给定操作的数量。计数信号量可以用来实现资源池或者给一个容器限定边界。
一个semaphore管理-个有效的许可(permit)集;许可的初始量通过构造函数传递给Semaphore.活动能够获得许可(只要还有剩余许可),并在使用之后释放许可。如果已经没有可用的许可了,那么acquire会被阻塞,直到有可用的为止(或者直到被中断或者操作超时)。release 方法向信号量返回一个许可4。计算信号量的一种退化形式是二元信号量:一个计数初始值为1的Semaphore。二元信号量可用作互斥(mutex) 锁,它有不可重入锁的语意;谁拥有这个唯一的许可, 就拥有了互斥锁。.
关卡
关卡(barrier )类似于闭锁,它们都能够阻塞一组线程, 直到某些事件发生。其中关卡与闭锁关键的不同在于,**所有线程必须同时到达关卡点,才能继续处理。****闭锁等待的是事件;关卡等待的是其他线程。**关卡实现的协议,就像一些家庭成员指定商场中的集合地点:“我们每个人6:00在麦当劳见,到了以后不见不散,之后我们再决定接下来做什么。”
cyclicBarrier允许一个给 定数量的成员多次集中在一个关卡点,这在并行迭代算法中非常有用,这个算法会把一个问题拆分成一系列相互独立的子问题。当线程到达关卡点时,调用await, await会被阻塞,直到所有线程都到达关卡点。如果所有线程都到达了关卡点,关卡就被成功地突破,这样所有线程都被释放,关卡会重置以备下一次使用。如果对await的调用超时,或者阻塞中的线程被中断,那么关卡就被认为是失败的,所有对await未完成的调用都通过BrokenBarrierException终止。如果成功地通过关卡, await为每一个线程返回一个唯一的到达索引号,可以用它来“选举”产生一个领导,在下一次迭代中承担一些特殊工作.CyclicBarrier也允许你向构造函数传递一个关卡行为barrier action) ;这是一个Runnable,当成功通过关卡的时候,会(在一个子任务线程中)执行,但是在阻塞线程被释放之前是不能执行的。
1 | |
5.6为计算结果建立高效、可伸缩的高速缓存
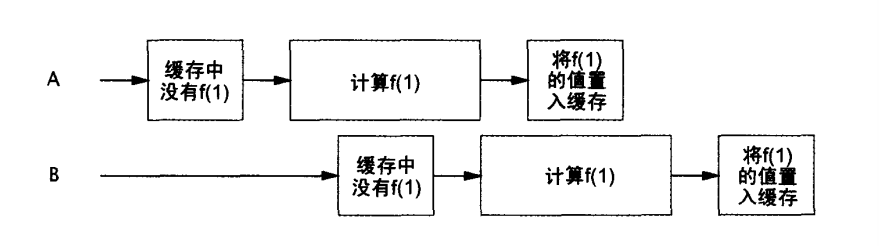
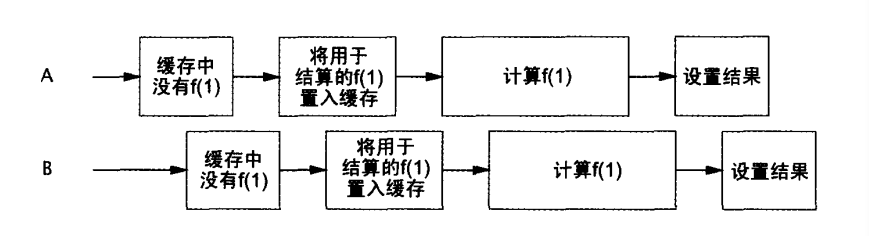
一些总结
- 可变状态,伙计们’!所有并发问题都归结为如何协调访问并发状态。可变状态越少,保证线程安全就越容易。
- 尽量将域声明为final类型,除非它们的需要是可变的。
- 不可变对象天生是线程安全的。不可变对象极大地减轻了并发编程的压力。它们简单而且安全,可以在没有锁或者防御性复制的情况下自由地共享。
- 封装使管理复杂度变得更可行。你固然可以用存储于全局变量的数据来写一个线程安全类。但是你为什么要这样做?在对象中装封数据,让它们能够更加容易地保持不变;在对象中封装同步,使它能够更容易地遵守同步策略。
- 用锁来守护每一个可变变量。
- 对同一不变约束中的所有变量都使用相同的锁。
- 在运行复合操作期间持有锁。
- 在非同步的多线程情况下,访问可变变量的程序是存在隐患的。
- 不要依赖于可以需要同步的小聪明。
- 在设计过程中就考虑线程安全。或者在文档中明确地说明它不是线程安全的。
- 文档化你的同步策略。
第6章 任务执行
6.1在线程中执行任务
1.单线程执行
1 | |
一个web请求的处理包括执行运算和I/O操作.对于一个单线程的服务器,阻塞不仅延迟了当前请求的完成,而且还完全阻止了需要被处理的等待请求.
顺序化处理几乎不能为服务器应用程序提供良好的吞吐量或快速的响应性。不过也有少数的特例—比如,当任务的数量很少但生命周期很长时,或者当服务器只服务于唯一的用户时,服务器在同一时间内只需同时处理一个请求一但是 大多数服务器应用程序都不是以这种方式工作的。
2.显示地为任务创建线程
1 | |
- 执行任务的负载已经脱离 了主线程,这让主循环能够更迅速地重新开始等待下一个连接。这使得程序可以在完成前面的请求之前接受新的请求,从而提高了响应性。
- 并行处理任务, 这使得多个请求可以同时得到服务。如果有多个处理器,或者出于IO未完成、锁请求以及资源可用性等任何因素需要阻塞任务时,程序的吞吐量会得到提高。
- 任务处理代码必须是线程安全的,因为有多个任务会并发地调用它。在中等强度的负载水平下,“ 每任务每线程(thread-per-task) ”方法是对顺序化执行的良好改进。只要请求的到达速度尚未超出服务器的请求处理能力,那么这种方法可以同时带来更快的响应性和更大的吞吐量。
考虑因素:
- 线程生命周期的开销
- 资源消耗量
- 稳定性
顺序执行会产生糟糕的响应性和吞吐量,每个任务创建一个线程会给资源管理带来麻烦.
6.2 Executor框架
1 | |
Executor只是个简单的接口,但它却为一个灵活而且强大的框架创造了基础,这个框架可以用于异步任务执行,而且支持很多不同类型的任务执行策略。它还为任务提交和任务执行之间的解耦提供了标准的方法,为使用Runnable描述任务提供了通用的方式。Executor的实现还提供了对生命周期的支持以及钩子函数,可以添加诸如统计收集、应用程序管理机制和监视器等扩展。
Executor基于生产者-消费者模式
使用线程池的Web Server
1 | |
为每一个任务启动一个新线程的Executor
1 | |
执行策略
将任务的提交与任务的执行体进行解耦,它的价值在于让你可以简单地为-一个类给定的任务制定执行策略,并且保证后续的修改不至于太困难。一个执行策略指明了任务执行的“what, where, when, how”几个因素.
线程池
在线程池中执行任务线程,这种方法有很多“每任务每线程”无法比拟的优势。重用存在的线程,而不是创建新的线程,这可以在处理多请求时抵消线程创建、消亡产生的开销。另一项额外的好处就是,在请求到达时,工作者线程通常已经存在,用于创建线程的等待时间并不会延迟任务的执行,因此提高了响应性。通过适当地调整线程池的大小,你可以得到足够多的线程以保持处理器忙碌,同时可以还防止过多的线程相互竞争资源,导致应用程序耗尽内存或者失败。
类库提供了一个灵活的线程池实现和一些有用的预设配置。你可以通过调用Executors中的某个静态工厂方法来创建一个线程池:
- **newFixedThreadpool**创建一个定长的线程池,每当提交- -个任务就创建-一个线程,直到达到池的最大长度,这时线程池会保持长度不再变化(如果一个线程由于非预期的Exception而结束,线程池会补充一个新的线程)。
- **newCachedThreadPool**创建一个可缓存的线程池,如果当前线程池的长度超过了处理的需要时,它可以灵活地回收空闲的线程,当需求增加时,它可以灵活地添加新的线程,而并不会对池的长度作任何限制。
- **newsingleThreadExecutor**创建-一个 单线程化的executor,它只创建唯-的工作者线程来执行任务,如果这个线程异常结束,会有另一个取代它。executor 会保证任务依照任务队列所规定的顺序(FIFO, LIFO, 优先级)执行。
- **newscheduledThreadPool**创建一个定长的线程池,而且支持定时的以及周期性的任务执行,类似于Timer。
Executor的生命周期
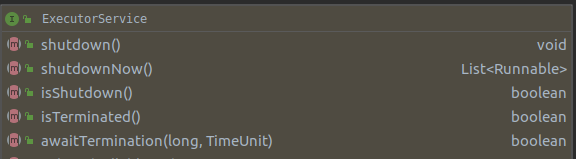
三种生命周期状态: 运行(running),关闭(shutting down),终止(terminated)
案例:支持关闭的Web Server
1 | |
6.3寻找可强化的并行性
- 顺序执行的页面渲染器
- 可携带结果的任务:Callable和Future
- CompletionService的页面渲染器
- 为任务设置时限
围绕任务的执行来构造应用程序,可以简化开发,便于同步。Executor框架有助于你在任务的提交与任务的执行策略之间进行解耦,同时还支持很多不同类型的执行策略。你发现自己为执行任务而创建线程时,可以考虑使用Executor取代以前的方法。把应用程序分解为不同的任务,为了使这一行为产生最大的效益,你必须指明一个清晰的任务边界。在一些应用程序中,存在明显的工作良好的任务边界,然而还有一些程序,你需要作
进一步的分析,以揭示更多可加强的并行性。
第7章 取消和关闭
可取消的:当外部代码能够在活动自然完成之前,把他更改为完成状态,那么这个活动被称为可取消的.
用户请求的取消
用户点击程序界面上的“cancel” 按钮,或者通过管理接口请求取消,比如JMX(Java Management Extensions)。
限时活动。
一个应用程序,需要在有限的时间内搜索问题空间,并且在规定时间内选择最好的解决方案。如果计时器超时,正在搜索的任务会被取消。
应用程序事件
一个应用程序对问题空间进行分解搜索,使不同的任务搜索问题空间中不同的区域。当-一个任务发现了解决方案,所有其他仍在工作的搜索会被取消。
错误
一个Web Crawler 搜索几个相关页面,并把页面或概要数据存储到硬盘。当Crawler的任务遭遇错误(比如,磁盘空间已满),那么所有的搜索任务都会被取消,不过很可能会记录它们当前的状态,这样稍后可以重新启动。
关闭
当一个程序或者服务关闭时,必须对正在处理的和等待处理的工作进行一些操作。一个优雅的关闭,可能允许当前的任务完成;在一个更加紧迫的关闭中,当前的任务就可能被取消了。
1 | |
中断
线程中断是一个协作机制,一个线程给另一个线程发送信号(signal)通知它在方便或者可能的情况下停止正在做的工作,去做其他事情.
调用interrupt并不意味着必然停止目标线程正在进行的工作,它仅仅传递了请求中断的消息.
划重点
我们对中断本身最好的理解应该是:它并不会真正中断一个正在运行的线程:它仅仅发出**中断请求**,线程自己会在下一个方便的时刻中断(这些时刻被称为取消点, eanelltion point)
1 | |
中断策略
因为每一个线程都有其自己的中断策略,所以你不应该中断线程,除非你知道中断对这个线程意味着什么。批评者嘲笑Java的中断工具,因为它没有提供优先中断的能力,而且还强迫开发者处理InterruptedException。但是推迟中断请求的能力使开发者能够制定更灵活的中断策略,从而实现适合于程序的响应性和健壮性之间的平衡。
只有实现了线程中断策略的代码才可以接收中断请求。通用目的的任务和库的代码绝不应该接收中断请求。
处理不可中断阻塞
很多可阻塞的库方法通过提前返回和抛出Interrupt edException来实现对中断的响应,这使得构建可以响应取消的任务更加容易了。但是,并不是所有的阻塞方法或阻塞机制都响应中断:如果一个线程是由于进行同步SocketIO或者等待获得内部锁而阻塞的,那么中断除了能够设置线程的中断状态以外,什么都不能改变。对于那些被不可中断的活动所阻塞的线程,我们可以使用与中断类似的手段,来确保可以停止这些线程。但是这需要我们更清楚地知道线程为什么会被阻塞。
java. IO中的同步Socket I/O.在服务器应用程序中,阻塞I/O最常见的形式是读取和写入Socket.不幸的是,InputStream 和OutputStream中的read和write方法都不响应中断,但是通过关闭底层的Socket, 可以让read或write所阻塞的线程抛出一个SocketException。
java.nio中的同步I/O.中断一个等待InterruptibleChannel的线程,会导致抛出ClosedBy InterruptException,并关闭链路( 也会导致其他线程在这条链路的阻塞,抛出ClosedByInterruptException) 。关闭一个Interrupt ibleChannel导致多个阻塞在链路操作上的线程抛出AsynchronousCloseExcept ion。
大多数标准Channels都实现Inter ruptibl eChannel。
**selector的异步I/O**。 如果一个线程阻塞于Selector.select 方法(在java. nio.channels中),close 方法会导致它通过抛出ClosedselectorException 提前返回。
1 | |
7.2 停止基于线程的服务
正如其他被封装的对象-样,线程的所有权是不可传递的:应用程序可能拥有服务,服务可能拥有工作者线程,但是应用程序并不拥有工作者线程,因此应用程序不应该试图直接停止工作者线程。相反,服务应该提供生命周期方法(iecycle methods)来关闭它自己,并关闭它所拥有的线程:那么当应用程序关闭这个服务时,服务就可以关闭所有的线程了。ExecutorService提供了shutdown 和shutdownNow方法,其他线程持有的服务
也应该都提供类似的关闭机制。
对于线程持有的服务,只要服务的存在时间大于创建线程的方法存在的时间,那么就应该提供生命周期方法。
7.3处理反常的线程终止
当一个单线程化的控制台程序因为未捕获的异常终止的时候,程序停止运行,并产生,了栈追踪,这与典型的程序输出有很大的不同一这是很明显的。并发程序中线程的失败往往就没有这么明显了。栈追踪可能会从控制台输出,但是没有人会去观察控制台,并且,当线程失败的时候,应用程序可能看起来仍在工作,所以它的失败可能就会被忽略。幸运的是,我们有方法可以监测和防止线程从程序中“泄漏”。
导致线程死亡的最主要原因是Runt imeException。因为这些异常表明一个程序错误或者其他不可修复的错误,它们通常是不能被捕获的。它们不会顺着栈的调用传递,此时,默认的行为是在控制台打印栈追踪的信息,并终止线程。
线程非正常退出的后果包括良性的与恶性的,取决于线程在应用程序中的角色,但是程序能跑在50个线程的线程池上,通常也能够安全地跑在49个线程的线程池上。然而在GUI程序中,失去分派事件的线程会非常显著应用程序会停止处理事件,GUI会被冻结。
1 | |
在一个长时间运行的应用程序中,所有的线程都要给未捕获异常设置一个处理器,这个处理器至少要将异常信息记入日志中。
7.4 JVM关闭
JVM既可以通过正常手段关闭,也可以强行关闭。当最后-一个“正常(非精灵)”线程终结时,或者当有人调用了system.exit时,以及通过使用其他与平台相关手段时(比如发送了SIGINT,或键入ctr1-c),都可以开始-一个正常的关闭。尽管JVM可以通过这些标准的首选方法关闭,它仍然能够通过调用Runtime.halt或者“杀死”JVM的操作
系统进程被强行关闭(比如发送SIGKILL)。
守护线程
有时你想要创建一个线程,执行一些**辅助工作**, 但是你不希望这个线程的存在阻碍JVM的关闭。这时你需要用到精灵线程(daemon thread)。
线程被分为两种:普通线程和精灵线程。JVM启动的时创建所有的线程,除了主线程以外,其他的都是精灵线程(比如垃圾回收器和其他类似线程)。当一个新的线程创建时,新线程继承了创建它的线程的后台状态,所以默认情况下,任何主线程创建的线程都是普通线程。
普通线程和精灵线程之间的差别仅仅在于退出时会发生什么。当一个线程退出时,JVM会检查-一个运行中线程的详细清单, 如果仅剩下精灵线程,它会发起正常的退出。当JVM停止时,所有仍然存在的精灵线程都会被抛弃一不会执行 finally块,也不会释放栈一JVM 直接退出。
精灵线程应该小心使用一在任何时候, 几乎没有哪些活动的处理可以在不进行清理的情况下,被安全地抛弃。特别是执行I/O操作的任务运行在精灵线程中是很危险的。精灵线程最好用于“家务管理(housekeeping) ”的任务,比如一个背景线程可以从内存的缓存中周期性地移除过期的访问。
应用程序中,精灵线程不能替代对服务的生命周期恰当、良好的管理。
Finalizer
当我们已经不再需要资源后,垃圾回收器重新获得内存资源是非常有益的,但是一些资源,比如文件或者Socket句柄,当我们不再需要时,必须显式地归还给操作系统。
为了在这方面提供帮助,垃圾回收器对那些具有特殊finalize方法的对象会进行特殊对待:在回收器获得它们后,finalize 被调用,这样就能保证持久化的资源可以被释放**。因为finalizer可以运行在一个 JVM管理的线程中,任何finalizer访问的状态都会被多个线程访问,因此必须被同步。finalizer 运行时不提供任何保证,并且拥有复杂的finalizer会带来对象巨大的性能开销。正确的书写finalizer 也十分困难。在大多数情况下,使用finally块和显式close方法的结合来管理资源,会比使用finalizer起到更好的作用**。当你需要管理对象,并且这个对象持有的资源是通过本地方法获得的,这时会产生独特的异常。鉴于这些原因,和其他些原因,应努力的避免编写或者使用包含finalizer 的类(除非是在平台库的类中) 。
避免使用finalizer。
第8章应用线程池
8.1任务与执行策略间的隐性耦合
并非所有的任务都适合所有的执行策略,有的类型的任务需要明确的指定一个执行策略,包括:
- 依赖性任务.
- 采用线程限制的任务.
- 对响应时间敏感的任务.
- 使用ThreadLocal的任务.
线程饥饿死锁
在线程池中如果一个任务依赖于其他任务的执行,就可能产生死锁.
无论何时,你提交了一个非独立的Executor 任务,要明确出现线程饥饿死锁的可能性,并且,在代码或者配置文件以及其他可以配置Executor的地方,任何有关池的大小和配置约束都要写入文档。
耗时操作
如果任务由于过长的时间周期而阻塞,那么即使不可能出现死锁,线程池的响应性也会变得很差。耗时任务会造成线程池堵塞,还会拖长服务时间,即使小任务也不能幸免。
耗时操作的数目会期望线程有一个稳定的数量,如果线程池的大小相对于这个数字来说太小,那么最后可能所有的线程都会处于运行耗时任务的状态中,从而就会影响响应性。
有一项技术可以用来缓解耗时操作带来的影响,这就是限定任务等待资源的时间,而不要无限制地等下去。大多数平台类库中的阻塞方法,都同时有限时的和非限时两个版本,比如Thread. join、BlockingQueue . put、CountDownLatch . await和Selector . select。
如果等待超时,你可以把任务标识为失败,中止它或者把它重新放回队列,准备之后执行。这样,无论每个任务的最终结果是成功还是失败,该办法都保证了任务总会向前发展,这样可以更快地将线程从任务中解放出来。如果线程池频频被阻塞的任务充满,这同样也可能是池太小的一个信号。
8.2定制线程池的大小
定制线程池考虑的因素:
- 计算环境
- 资源预算
- 任务特性
- CPU个数
- 内存大小
- 应用场景:计算型或I/O型
计算密集型**:N个处理器的系统通常通过使用一个N+1**个线程的线程池来获取最优的利用率(计算密集型的线程恰好在某时因为发生一个页错误或因为其他原因暂停,刚好有一个"额外"的线程,可以确保在这种情况下CPU周期不会中断工作)
**I/O型**:对于包含I/O和其他阻塞操作的任务,不是所有的线程都会在所有的时间被调度,因此需要一个更大的池.
- N=CPU的数量
- U=目标CPU的使用率,0<=U<=1
- W/C=等待时间与计算时间的比率
为了保持处理器达到期望的使用率,最优的池的大小等于:*T=NU*(1+W/C)**;
8.3 配置ThreadPoolExecutor
ThreadPoolExecutor为一些Executor 提供了基本的实现,这些Executor 是由Executors中的工厂newCachedThreadPool、 newFixedThreadPool和newScheduledThreadExecutor返回的。ThreadPoolExecutor是一个灵活的、健壮的池实现,允许各种各样的用户定制。
如果默认的执行策略不能满足你的需要,你可以通过构造函数实例化一个ThreadPoolExecutor,自己定制它直到你满意为止;你可以参考Executors的源代码是如何实现默认配置的执行策略的,然后以它们为起点开始你自己的实现。ThreadPoolExecutor有很多个构造函数.
1 | |
管理队列任务
有限线程池限制了可以并发执行的任务的数量(单线程化的Executor是一个值得注意的特例:它们保证没有并发执行的任务,通过线程限制,提供了获得线程安全的可能性)。
- 无限队列
- 有限队列
- 同步移交
饱和策略
- **AbortPolicy**中止策略,直接抛出RejectedExecutionException,调用者捕获这个异常然后编写自己处理代码
- **CallerRunsPolicyd**调用者运行,既不会丢弃哪个任务,也不会抛出任何异常.把一些任务退会调用者那里,减缓新任务流.
- **DiscardPolicy**遗弃默认放弃这个任务
- **DiscardOldestPolicy**遗弃旧的任务
线程工厂
无论何时,线程池需要创建一个线程, 都要通过一个线程工厂 (thread factory, 参见清单)来完成。默认的线程工厂创建一个新的、非后台(nondaemon) 的线程,并没有特殊的配置。详细指明一个线程工厂,能允许你定制池线程的配置信息。ThreadFactory只有唯一的方法newThread,它会在线程池需要创建一个新线程时调用。
有很多原因需要使用定制的线程工厂。你可能希望为池线程指明一个Uncaught Except ionHandler,或者实例化一个定 制Thread类的实例,比如用来执行调试日志的线程。你也可能希望修改池线程的优先级(通常这不是一个非 常好的主意)或者后台状态(daemon status,同上)。或者你可能只是希望给池线程一个更有意义的名称,来简化对线程转储和错误日志的解释。
1 | |
8.4 扩展ThreadPoolExecutor
ThreadPool Executor的设计是可扩展的,它提供了几个“钩子”让子类去覆写beforeExecute、afterExecute 和terminate这些可以用来扩 展ThreadPoolExecutor行为。
执行任务的线程会调用钩子函数beforeExecute和afterExecute,用它们添加日志、时序、监视器或统计信息收集的功能。无论任务是正常地从run中返回,还是抛出一个异常,afterExecute都会被调用。(如果任务 完成后抛出一一个Error,则afterExecute不会被调用。)如果beforeExecute抛出一个Runt imeExcept ion,任务将不被执行,after Execute也不会被调用。
terminatea钩子会在线程池完成关闭动作后调用,也就是当所有任务都已完成并且所有工作者线程也已经关闭后,会执行terminated. terminated可以用来释放Executor在生命周期里分配到的资源,还可以发出通知、记录日志或者完成统计信息。
8.5 并行递归算法
对于并发执行的任务,Executor框架是强大且灵活的。它提供了大量可调节的选项,比如创建和关闭线程的策略,处理队列任务的策略,处理过剩任务的策略,并且提供了几个钩子函数用于扩展它的行为。然而,和大多数强大的框架-样,草率地将-些设定组合在一起,并不能很好地工作;一些类型的任务需要特定的执行策略,而一些调节参数组合在一起后可能产生意外的结果。
第9章GUI应用程序
9.1 为什么GUI是单线程化的
早期的GUI应用程序就是单线程化的,GUI事件在“主事件循环” 进行处理。现代的GUI框架使用了-一个略微不同的模型:模型创建了一个专门的线程,事件派发线程(event dispatch thread, EDT)来处理GUI事件。
单线程化的GUI 框架并不仅仅存在于Java 中; Qt、 NextStep、 MacOS Cocoa、 xWindows,等等都是单线程化的。也并不缺少反面的尝试;有很多试图写出多线程的GUI框架的努力,最终都由于竞争条件和死锁导致的稳定性问题,又回到了单线程化的事件队列模型的老路上来:**采用一一个专门的线程从队列中抽取事件,并把它们转发给应用程序定义的事件处理器**。(AWT最初曾尝试在某种程度上支持多线程访问,单线程化地实现Swing的决定主要基于AWT中的经验和教训。)
Swing的单线程规则: Swing 的组件和模型只能在事件分派线程中被创建、修改和请求。
9.2 短期的GUI任务
在GUI应用程序中,事件起源于事件线程,冒泡似的传递到达应用程序提供的监听器,监听器进而可能会执行一些影响表现模型 (presentation object) 的运算。为了简单起见,短期的任务可以把全部动作留在事件线程中完成;而对于耗时的任务,则应该将- -些工作负荷分压到另一个线程中。.
9.3 耗时GUI任务
如果所有的任务都是短期的(而且应用程序不存在重要的非GUI的部分) ,那么整个应用程序就可以在事件线程内部运行,你可以完全不必关心线程。但是,成熟的GUI应用程序可能会运行一些耗时的任务,以致于超过了用户预期的时间,比如拼写检查、后台编辑或者获取远程资源。这些任务必须在另外的线程中运行,而使GUI在它们运行中可以作出响应。
9.4 共享数据模型
Swing的表现对象(包括Tabl eModel、TreeModel 这些数据模型)是被限制在事件线程中的。在简单的GUI程序中,所有的可变对象都保存在表现对象中,事件线程之外唯一的线程就只有主线程。强制这些程序遵守单线程规则很容易:不要在主线程中访问数据模型或表现组件(presentation component)。更多的复杂程序可能要从持久化存储中移出或移入数据,比如文件系统、数据库,这就要使用其他线程,以免破坏了响应性。
9.5 其他形式的单线程子系统
线程限制不仅仅限制在GUI系统:无论何时,它都可以用作实现单线程化子系统的便利工具。有时当程序员对避免同步与死锁束手无策的时候,使用线程限制成为了他们不得不使用的办法。比如,一些原生库(native librarie) 要求所有对库的访问,甚至System. loadLibrary加载库时,必须在同一个线程中运行。
借用GUI框架中的方法,你可以简单地为访问原生库创建一个专 门的线程或者一个单线程化的Executor,然后提供一个代理对象拦截所有对线程限制对象的调用,把拦截的调用当作任务提交给前面创建的线程中。Future和newsingleThreadExecutor的组合可以简化这项工作;代理方法调用submit提交任务,然后立即调用Future .get等待结果。(如果线程限制的类实现了一个的接口,你就可以自动完成每次方法向后台线程Executor提交Callable的过程,然后利用动态代理收集结果。) (译注: Java 中的动态代理功能只支持interface。)
第10章 避免活跃度危险
10.1死锁
经典的“哲学家进餐”问题很好地阐示了死锁,尽管这有点影响食欲。5个哲学家一起出门去吃中餐,他们围坐在一个圆桌边。他们有5只筷子(不是5双),每两个人中间放有一只。哲学家边吃边思考,交替进行。每个人都需要获得两只筷子才能吃东西,但是吃后要把筷子放回原处继续思考。有一些管理筷子的算法,使每一个人都能够或多或少, 及时吃到东西(一个饥饿的哲学家试图获得两只邻近的筷子,但是如果其中的一只正在被别人占用,那么他应该放弃其中-一只可用的筷子,等待几分钟再尝试)。
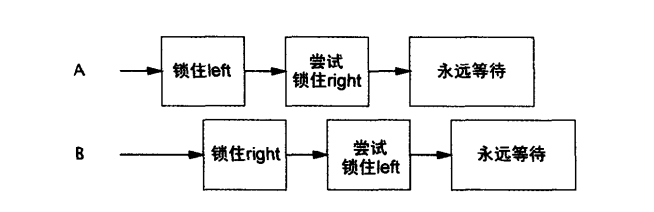
但是这样做可能导致一些哲学家或者所有哲学家都“饿死”(每个人都迅速抓住自己左边的筷子,然后等待自己右边的筷子变为可用,同时并不放下左边的筷子)。这后一种情况,当每个人都拥有他人需要的资源,并且等待其他人正在占有的资源,如果大家一直占有资源,直到获得自己需要却没被占有的其他资源,那么就会产生死锁。
当一个线程永远占有一个锁,而其他线程尝试去获得这个锁,那么它们将永远被阻塞。当线程A占有锁L时,想要获得锁M,但是同时,线程B持有M,并尝试获得L,两个线程将永远等待下去。这种情况是死锁最简单的形式(或称致命的拥抱,**deadly embrace**),
1 | |
1 | |

如果Account具有一一个唯一-的, 不可变的,并具有可比性的key,比如账号,那么制定锁的顺序就更加容易了:通过key来排定对象顺序,这样能省去“加时赛”锁的需要。
协作对象间的死锁
在持有锁的时候调用外部方法是在挑战活跃度问题。外部方法可能会获得其他锁(产生死锁的风险),或者遭遇严重超时的阻塞。当你持有锁的时候会延迟其他试图获得该锁的线程。
开放调用
当调用的方法不需要持有锁时,这被称为开放调用(open call)在程序中尽量使用开放调用。依赖于开放调用的程序,相比于那些在持有锁的时候还调用外部方法的程序,更容易进行死锁自由度( deadlock-freedom)的分析。
资源死锁
当线程间相互等待对方持有的锁,并且谁都不会释放自己的锁时就会发生死锁,当线程持有和等待的目标变为资源时,会发生与之相类似的死锁。
10.2 避免和诊断死锁
如果一个程序一次至多获得一个锁, 那么就不会产生锁顺序死锁。当然,这通常并不现实,但是如果你能够避免这个情况,就能够省去很多工作。如果你必须获得多个锁,那么锁的顺序必须是你设计工作的一部分:尽量减少潜在锁之间的交互数量,遵守并文档化该锁顺序协议,这些缺一不可。
在使用定义良好的锁的程序中,监测代码中死锁自由度的策略分为两个部分:首先识别什么地方会获取多个锁(使这个集合尽量小),对这些示例进行全局的分析,确保它们锁的顺序在程序中保持一致。尽可能使用开放调用,这样做能够从根本上简化分析的难度。
在没有非开放调用的程序中,发现那些获得多重锁的实例是非常简单的,既可以通过复查代码,也可以通过对字节码或源代码自动地进行分析来完成。
- 尝试定时的锁
- 通过线程转存储分析死锁
预防死锁是你面临的最大问题,JVM使用线程转储(thread dump)来帮助你识别死锁的发生。线程转储包括每个运行中线程的栈追踪信息,以及与之相似并随之发生的异常。线程转储也包括锁的信息,比如,哪个锁由哪个线程获得,其中获得这些锁的栈结构,以及阻塞线程正在等待的锁究竟是哪一个。
10.3 其他的活跃度危险
饥饿
当线程访问它所需要的资源时却被永久拒绝,以至于不能再继续进行,这样就发生了饥饿(starvation) ;
最常见的引发饥饿的资源是CPU周期。在Java应用程序中,使用线程的优先级不当可能引起饥饿。在锁中执行无终止的构建也可能引起饥饿(无限循环,或者无尽等待资源),因为其他需要这个锁的线程永远不可能得到它。
抵制使用线程优先级的诱惑,因为这会增加平台依赖性,并且可能引起活跃度问题。大多数并发应用程序可以对所有线程使用相同的优先级。
弱响应性
不良的锁管理也可能引起弱响应性。如果一个线程长时间占有一个锁(可能正在对一个大容器进行迭代,并对每一个元素进行耗时的工作),其他想要访问该容器的线程就必须等待很长时间。
活锁
活愤(livelock)是线程中活跃度失败的另一种形式,尽管没有被阻塞,线程却仍然不能继续,因为它**不断重试相同的操作,却总是失败。活锁通常发生在消息处理应用程序中,如果消息处理失败的话,其中传递消息的底层架构会回退整个事务,并把它置回队首**。如果消息处理程序对某种特定类型的消息处理存在bug,每次处理都会失败,那么每一次这个消息都会被从队列中取出,传递到存在问题的处理器(handler),然后发生事务回退。
因为这条消息又会到队首,处理器会不断被这样重复调用,并返回重复结果。这就是通常称为毒药信息(poison message)的问题。信息处理线程并没有发生阻塞,但是永远都不会前进了。这种形式的活锁通常来源于过渡的错误恢复代码,误将不可修复的错误当作是可修复的错误。
第11章 性能和可伸缩性
11.1 性能的思考
改进性能意味着用更少的资源做更多的事情。“资源” 的概念很广泛,对于给定的活动而言,一些特定的资源通常非常缺乏,无论是CPU周期、内存、网络带宽、I/O 带宽、数据库请求、磁盘空间、以及其他-些资源。当活动的运行因某个特定资源受阻时,我们称之为受限于该资源:受限于CPU,受限于数据库。
引入多线程总会引入一些性能的开销:
- 与协程相关的开销(加锁,信号,内存同步)
- 增加上下文切换
- 线程的创建和消亡
- 调度的开销
应用程序可以从很多个角度来衡量;比如服务时间、等待时间、吞吐量、效率、可伸缩性、生产量。有一些标准(服务时间、等待时间)是用来衡量“有多快”,即给定的任务单元需要多长时间进行处理,得到回馈;另一-些(生产量、吞吐量)用来衡量“有多少”,即限定计算资源的情况下,究竟能够完成多少工作。
可伸缩性指的是:当增加计算资源的时候(比如增加额外CPU数量、内存、存储器、I/O带宽),吞吐量和生产量能够相应地得以改进。
11.2 AmdahI定律
有些问题使用越多的资源就能越快地解决一越 多的工人参与收割庄稼,那么就能越快地完成收获。另-些任务根本就是串行化的一增加更 多的工人根本不可能提高收割速度。如果我们使用线程的重要原因之一是为了支配多处理器的能力,我们必须保证问题被恰当地进行了并行化的分解,并且我们的程序有效地使用了这种并行的潜能。
大多数并发程序都与农耕有着很多相似之处,由一系列并行和串行化的片断组成。Amdahl定律描述了在一个系统中,基于可并行化和串行化的组件各自所占的比重,程序通过获得额外的计算资源,理论上能够加速多少。如果F是必须串行化执行的比重,那么Amdahl定律告诉我们,在一个N处理器的机器中,我们最多可以加速:
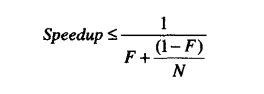
11.3 线程引入的开销
- 切换上下文
- 内存同步
- 阻塞,自旋等待
11.4 减少锁的竞争
我们已经看到串行化会损害可伸缩性,上下文切换会损害性能。竞争性的锁会同时导致这两种损失,所以减少锁的竞争能够改进性能和可伸缩性。访问独占锁守护的资源是串行的一次只能有一个线程访问它。当然,我们有很好的理由使用锁,比如避免数据过期,但是这样的安全性是用很大的代价换来的。对锁长期的竞争会限制可伸缩性。
并发程序中,对可伸缩性首要的威胁是独占的资源锁。
有两个原因影响着锁的竞争性:锁被请求的频率,以及每次持有该锁的时间。如果这两者的乘积足够小,那么大多数请求锁的尝试都是非竞争的,这样竞争性的锁将不会成为可伸缩性巨大的阻碍。但是,如果这个锁的请求量很大,线程将会阻塞以等待锁:在极端的情况下,处理器将会闲置,即使仍有大量工作等着完成。
有3种方式来减少锁的竞争:
- 减少持有锁的时间;
- 减少请求锁的频率;
- 或者用协调机制取代独占锁,从而允许更强的并发性。
- 缩小锁的范围(快进快出)
- 减少锁的粒度
- 分离锁
- 避免热点域
- 独占锁的替代方法
- 检测CPU利用率(不充足负载,I/O限制,外部限制,锁竞争)
- 向对象池说不
11.5 示例:比较Map的性能
单线程化的ConcurrentHashMap的性能要比同步的HashMap的性能稍好一些,而且在并发应用中,这种作用就十分明显了。ConcurrentHashMap 的实现,假定大多数常用的操作都是获取已存在的某个值,因此它的优化是针对get操作,提供最好的性能和并发性。
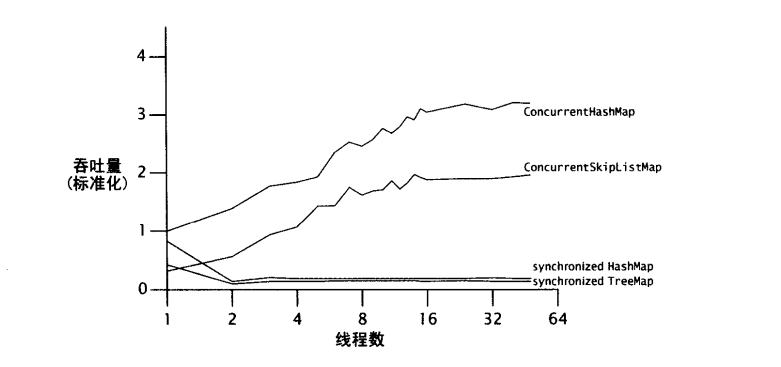
11.6 减少上下文切换的开销
很多任务引入的操作都会发生阻塞;在运行和阻塞这两个状态之间转换需要使用上下文切换。
因为使用线程最主要的目的是利用多处理器资源,在并发程序性能的讨论中,我们通常更多地关注吞吐量和可伸缩性,而没有强调自然服务时间。Amdahl 定律告诉我们,程序的可伸缩性是由必须连续执行的代码比例决定的。因为Java程序中串行化首要的来源是独占的资源锁,所以可伸缩性通常可以通过以下这些方式提升:减少用于获取锁的时间,减小锁的粒度,减少锁的占用时间,或者用非独占或非阻塞锁来取代独占锁。
第12章测试并发程序
- 吞吐:在一个并发任务集里,已完成任务所占的比例:
- 响应性:从请求到完成一些动作之间的延迟(也被称作等待时间) ;
- 可伸缩性:增加更多的资源(通常是指CPU),就能提高(或者缓解短缺)吞吐量。
12.1 测试正确性
为并发类开发单元测试的流程,始于和顺序类相同的分析一-识别出不变约束和后验条件,这些都要接受例行检查。如果幸运的话,它们中的大部分都明确地写在了规约中:余下的时间里,编写测试不亚于一次反复探索规约的历险。
为并发类创建有效的安全测试,其挑战在于:如何在程序出现问题并导致某些属性极度可能失败时,简单地识别出这些受检查的属性来,同时不要人为地让查找错误的代码限制住程序的并发性。最好能做到在检查测试的属性时,不需要任何的同步。
测试应该在多处理器系统上运行,以提高潜在交替运行的多样性。但是,多个CPU未必会使测试更加高效。为了能够最大程度地检测到时序敏感的数据竞争的发生机会,应该让测试中的线程数多于CPU数,这样在任何给定的时间里,都有一些线程在运行,一些被交换出执行队列,这样可以增加线程间交替行为的随机性。
12.2 测试性能
性能测试的第二个目标是为那些基于经验的不同界限一线程数、缓存容量等等选择-一个合适的大小。这些数值可能会非常依赖于平台的特征(比如处理器类型甚至处理器的“stepping level (译注:表示处理器部件生产工艺的,它的版本会随着这一系列处理器生产工艺的改进而增加。)”,处理器的数量,或者内存大小,需要动态地配置,这相当于为它们选择一个合理的值,可以广泛地应用在各种系统中。
- 加入时间特性
- 比较多种算法
- 测试响应性
12.3 避免性能测试的陷阱
- 垃圾回收
- 动态编译
- 代码路径的非真实取样
- 不切实际的竞争程度
- 死代码的消除
12.4 测试方法补遗
测试的目标不是更多地发现错误,而是提高信心,相信代码能够如期地工作。因为设想发现所有bug是不现实的,所以质量审查(quality assurance, QA)计划的目标应该定为利用现有的测试资源,最大程度上获得对代码的信心。并发程序会比顺序程序出更多的问题,所以想要获得同样级别的信心,还需要更多的测试。目前为止,我们已经关注了创建有效的单元测试与性能测试时使用的主要技术。在获得对并发类正确行为的信心时,测试如此重要,但并不是QA的唯方法。
- 代码审查
- 静态分析工具
第13章显式锁
在Java 5.0之前,用于调节共享对象访问的机制只有synchroni zed和volat ile.Java5.0提供了新的选择: Reentrantlock。 与我们已经提到过的机制相反,ReentrantLock并不是作为内部锁机制的替代,而是当内部锁被证明受到局限时,提供可选择的高级特性。
13.1 Lock和ReentrantLock
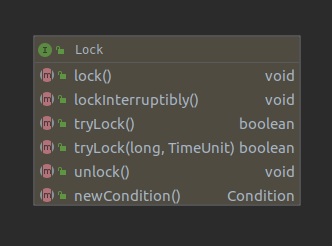
Lock接口,定义了一些抽象的锁操作。与内部加锁机制不同,Lock提供了无条件的、可轮询的、定时的、可中断的锁获取操作,所有加锁和解锁的方法都是显式的。Lock 的实现必须提供具有与内部加锁相同的内存可见性的语义。但是加锁的语义,调度算法,顺序保证,性能特性这些可以不同。
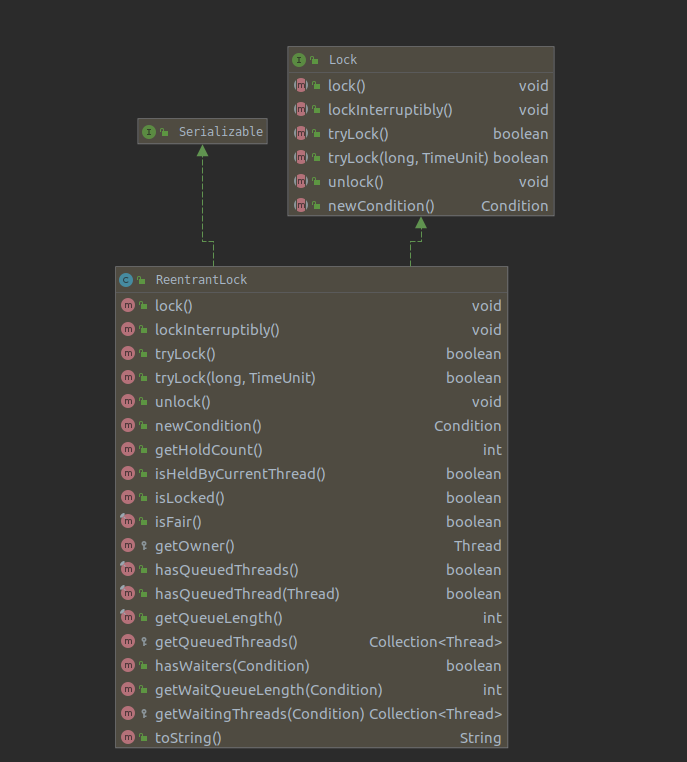
ReentrantLock实现了Lock 接口,提供了与synchroni zed相同的互斥和内存可见性的保证。获得ReentrantLock的锁与进入synchronized块有着相同的内存语义,释放ReentrantLock锁与退出synchronized块有相同的内存语义。
为什么要创建与内部锁如此相似的机制呢?内部锁在大部分情况下都能很好地工作,但是有一些功能上的局限一不能 中断那些正在等待获取锁的线程,并且在请求锁失败的情况下,必须无限等待。内部锁必须在获取它们的代码块中被释放;这很好地简化了代码,与异常处理机制能够进行良好的互动,但是在某些情况下,一个更灵活的加锁机制提供了更好的活跃度和性能。
忘记使用finally释放Lock是一个定时炸弹。当“不幸”发生的时候,你将很难追踪到错误的发生点,因为根本没有记录锁本应被释放的位置和时间。这就是ReentrantLock不能完全替代synchronized的原因:它更加“危险”,因为当程序的控制权离开了守护的块时,不会自动清除锁。尽管记得在finally块中释放锁并不困难,但忘记的可能性仍然存在。
可轮询的和可定时的请求
可定时的与可轮询的锁获取模式,是由**tryLock方法实现,与无条件的锁获取相比,它具有更完善的错误恢复机制**。在内部锁中,死锁是致命的一唯一的恢复方法是重新启动程序,唯一的预防方法是在构建程序时不要出错,所以不可能允许不一致的锁顺序。 可定时的与可轮询的锁提供了另一个选择:可以规避死锁的发生。
可中断的锁获取操作
正如定时锁的获得操作允许在限时活动内部使用独占锁,可中断的锁获取操作允许在可取消的活动中使用。当你正在响应中断的时候,lockInterruptibly方法能够使你获得锁,并且由于它是内置于Lock的,你因此不必再创建其他种类不可中断的阻塞机制。
非块结构的锁
在内部锁中,获取和释放这样成对的行为是块结构的一一总 是在其获得的相同的基本程序块中释放锁,而不考虑控制权是如何退出阻塞块的。自 动释放锁简化了程序的分析,并避免了潜在的代码错误造成的麻烦,但是有时需要更灵活的加锁规则。
13.2 对性能的考量
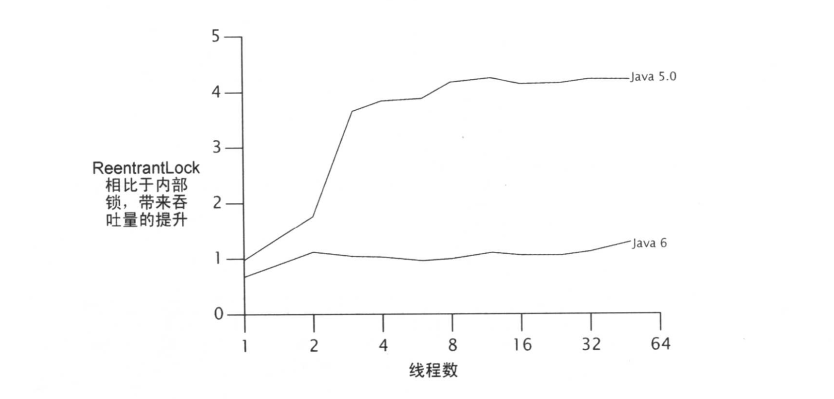
当ReentrantLock被加入到Java 5.0中时,它提供的竞争上的性能要远远优于内部锁。对于同步原语而言,竞态时的性能是可伸缩性的关键:如果有越多的资源花费在锁的管理和调度上,那用留给应用程序的就会越少。更好的实现锁的方法会使用更少的系统调用,发生更少的上下文切换,在共享的内存总线上发起更少的内存同步通信。耗时的操作会占用本应用于程序的资源。
13.3 公平性
ReentrantLock构造函数提供了两种公平性的选择:创建非公平锁(默认)或者公平锁。线程按顺序请求获得公平锁,然而一-个非公平锁允许 “闯入”:当请求这样的锁时,如果锁的状态变为可用,线程的请求可以在等待线程的队列中向前跳跃,获得该锁。(Semaphore同样提供了公平和非公平的获取顺序。)非公平的ReentrantLock并不是
有意鼓励“闯入”一倘若遇到闯入的发生, 它们不会有意避开。在公平锁中,如果锁已经被其他线程占有,新的请求线程会加入到等待队列,或者已经有一些线程在等待锁了 ;在非公平的锁中,线程只有当锁正在被占用时才会等待。
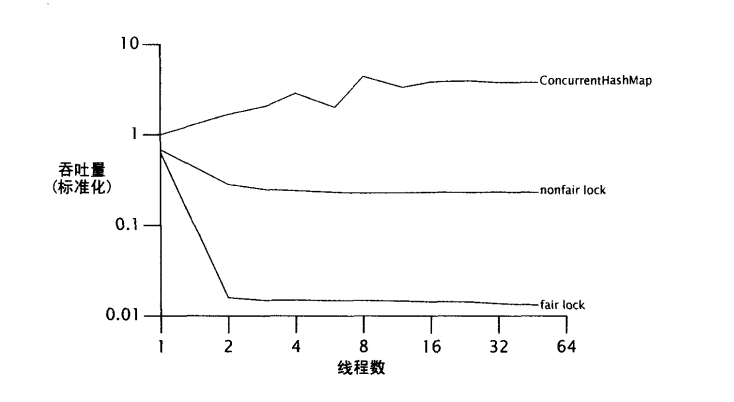
公平锁和非公平锁性能上的对比分析
在多数情况下非公平锁的性能优势超过了公平锁的排队
在激烈竞争的情况下,闯入锁比公平锁性能好的原因之一是:**挂起的线程重新开始,与它真正开始运行,两者之间会产生严重的延迟**。我们假设线程A持有一个锁,线程B请求该锁。因为此时锁正在使用中,所以B会被挂起。当A释放锁后,B重新开始。与此同时,如果C请求这个锁,那么C得到了很好的机会获得这个锁,使用它,并且甚至可能在B被唤醒前就已经释放该锁了。在这样的情况下,各方面都获得了成功: B并没有比其他任何线程晚得到锁,C更早地得到了锁,吞吐量得到了改进。
正如默认的ReentrantLock 一样,内部锁没有提供确定的公平性保证,但是大多数锁实现统计上的公平性保证,在大多数条件下已经足够好了。Java 语言规范并没有要求JVM公平地实现内部锁,JVM 也的确没有这样做。ReentrantLock 并没有减少锁的公平性一它只不过使一 些存 在的部分更显性化了。
13.4 在synchronized和ReentrantLock之间进行选择
在内部锁不能够满足使用时,ReentrantLock 才被作为更高级的工具。当你需要以下高级特性时,才应该使用可定时的、可轮询的与可中断的锁获取操作,公平队列,或者非块结构的锁。否则,请使用synchronized.
- 内部锁与ReentrantLock相比其线程转存储能够显示哪个调用框架获得了锁
13.5 读-写锁
ReentrantLock实现了标准的互斥锁: -次最多只有一个线程能够持有相同ReentrantLock.但是互斥通常作为保护数据一致性的很强的加锁约束,因此过分地限制了并发性。互斥是保守的加锁策略,避免了“写/写”和“写/读”的重叠,但是同样避开了“读/读”的重叠。在很多情况下,数据结构是“频繁被读取”的一它们是可变的, 有的时候会被改变,但多数访问只进行读操作。此时,如果能够放宽,允许多个读者同时访问数据结构就非常好了。只要每个线程保证能够读到最新的数据,并且在读者读取数据的时候没有其他线程修改数据,就不会发生问题。这就是读写锁允许的情况:一个资源能够被多个读者访问,或者被-一个写者访问,两者不能同时进行。
1 | |
读-写锁实现的加锁策略允许多个同时存在的读者,但是只允许一个写者。与Lock一样,ReadWriteLock允许多种实现,造成了性能、调度保证、获取优先、公平性、以及加锁语义等方面的不尽相同。
读取和写入锁之间的互动可以有很多种实现。ReadWriteLock 的-些实现选择如下:
- 释放优先。当写者释放写入锁,并且读者和写者都排在队列中,应该选择哪个读者,写者,还是先请求的那个呢?
- 读者闯入。如果锁由读者获得,但是有写者正在等待,那么新到达的写者应该被授予读取的权力么?还是应该等待?允许读者闯入到写者之前提高了并发性,但是却带来了写.者饥饿的风险。
- 重进入。读取锁和写入锁允许重入吗?
- 降级。如果线程持有写入的锁,它能够在不释放该锁的情况下获得读取锁么?这可能会造成写者“降级”为一个读取锁,同时不允许其他写者修改这个被守护的资源。
- 升级。读取锁能够优先于其他的读者和写者升级为一个写入锁么?大多数读-写锁的实现并不支持升级,因为在没有显式的升级操作的情况下,很容易造成死锁。( 如果两个读者同时试图升级到同一个写入锁,并都不释放读取锁。)
显式的Lock与内部锁相比提供了一些扩展的特性,包括处理不可用的锁时更好的灵活性,以及对队列行为更好的控制。但是ReentrantLock不能完全替代synchronized;只有当你需要synchroni zed没能提供的特性时才应该使用。读写锁允许多个读者并发访问被守护的对象,当访问多为读取数据结构的时候,它具有改进可伸缩性的潜力。
第14章构建自定义的同步工具
14.1 管理状态依赖性
在单线程化的程序中,如果调用一个方法的时候,依赖于状态的先验条件尚未满足(比如“连接池非空”),那么这个先验条件永远无法变为真了。因此,在顺序程序中,如果类的先验条件无法满足,就将它标为失败。但是在并发程序中,基于状态的条件会在其他线程的活动中被改变:一个池在几条指令以前还是空的,现在却可以变为非空,因为另外的线程会归还一个元素。对于并发对象,依赖于状态的方法有时可以在不能满足先验条件的情况下选择失败,不过更好的选择是等待先验条件变为真。
14.2 使用条件队列
条件队列让构建有效且可响应的状态依赖类变得容易,但是把它们用错也很容易;关于如何正确使用它们,存在着很多规则,编译器和平台却并没有强制要求它们。(这是要求你尽量将程序构建于像LinkedBlockingQueue、Latch、 Semaphore 和FutureTask这些类之.上的原因之一; 如果你能避免使用条件队列,可以避免很多麻烦。)
当使用条件等待时( object .wait或者Condition. await ):
- 永远设置一个条件谓词一一- 些对象状态的测试,线程执行前必须满足它;
- 永远在调用wait前测试条件谓词,并且从wait中返回后再次测试;
- 永远在循环中调用wait;
- 确保构成条件谓词的状态变量被锁保护,而这个锁正是与条件队列相关联的;
- 当调用wait、notify或者notifyAll时,要持有与条件队列相关联的锁;并且,
- 在检查条件谓词之后、开始执行被保护的逻辑之前,不要释放锁。
14.3 显式的Condition对象
一个 Condition和一-个 单独的Lock相关联,就像条件队列和单独的内部锁相关联一样;调用与Condition相关联的Lock 的Lock.newCondition方法,可以创建一个Condition。如同Lock提供了比内部加锁要丰富得多的特征集一样,Condition 也提供了比内部条件队列要丰富得多的特征集:每个锁可以有多个等待集、可中断/不可中断的条
件等待、基于时限的等待以及公平/非公平队列之间的选择。
Condition因素出Object监视器方法( wait , notify和notifyAll )成不同的对象,以得到具有多个等待集的每个对象,通过将它们与使用任意的组合的效果Lock个实现。 Lock替换synchronized方法和语句的使用, Condition取代了对象监视器方法的使用。条件(也称为条件队列或条件变量 )为一个线程暂停执行(“等待”)提供了一种方法,直到另一个线程通知某些状态现在可能为真。 因为访问此共享状态信息发生在不同的线程中,所以它必须被保护,因此某种形式的锁与该条件相关联。 等待条件的关键属性是它原子地释放相关的锁并挂起当前线程,就像Object.wait 。
一个Condition实例本质上绑定到一个锁。 要获得特定Condition实例的Condition实例,请使用其newCondition()方法。
例如,假设我们有一个有限的缓冲区,它支持put和take方法。 如果在一个空的缓冲区尝试一个take ,则线程将阻塞直到一个项目可用; 如果put试图在一个完整的缓冲区,那么线程将阻塞,直到空间变得可用。 我们希望在单独的等待集中等待put线程和take线程,以便我们可以在缓冲区中的项目或空间可用的时候使用仅通知单个线程的优化。 这可以使用两个Condition实例来实现。
1 | |
危险警告:wait.notify和noti fyAll在Condition对象中的对等体是await、signal和signalAll.但是,Condition 继承于Object,这意味着它也有wait和notify方法。一定要确保使用了正确的版本await 和signal.
在使用显式的Condition和内部条件队列之间作出选择,与你在ReentrantLock和synchronized之间进行选择是一样的: 如果你需要使用需要一些高级特性, 比如使用公平队列或者让每个锁对应多个等待集,这时使用Condition要好于使用内部条件队列。(如果你需要ReentrantLock的高级特性,并已经在使用它,那么你已经作出了选择。)
14.4 剖析Synchronizer
ReentrantLock和Semaphore这两个接口有很多共同点。这些类都扮演了“阀门”的角色,每次只允许有限数目的线程通过它;线程到达阀门后,可以允许通过(lock 或acquire成功返回),可以等待(lock 或acquire阻塞),也可以被取消(tryLock 或tryAcquire返回false,指明在允许的时间内,锁或者“许可”不可用)。更进一步,它们都允许可中断的、不可中断的、可限时的请求尝试,它们也都允许选择公平、非公平的等待线程队列。给出了这个共同点后,你可能认为Semaphore是实现于ReentrantLock之上的,或者可能ReentrantLock是作为只有一个许可的semamaphore实现的。这是完全可以的;一个很常见的练习就是使用lock 实现一个计数信号量,以及使用计数信号量实现一个lock。
事实上,它们的实现都用到一个共同的基类,AbstractQueuedsynchronizer (AQS)一和其 他很多的Synchronizer一样oAQS是一个用来构建锁和Synchronizer的框架,令人惊讶的是,使用AQS能够简单且高效地构造出应用广泛的大量的synchronizer.不仅ReentrantLock和Semaphore是构建于AQS上的,其他的还有CountDownLatch、
ReentrantReadWr iteLock、SynchronousQueue 1和FutureTask。
14.5 AbstractQueuedSynchronizer
一个基于AQS的Synchronizer所执行的基本操作,是一些不同形式的获取( acquire)和释放(release) 。获取操作是状态依赖的操作,总能够阻塞。借助锁和信号量,“ 获取”的含义变得相当直观一获取 锁或者许可一并 且调用者可能不得不去等待,直到Synchronizer处于可发生的状态。Count DownLatch的请求意味着“等待,直到闭锁到达它的终止态”,FutureTask则意味着“等待,直到任务已经完成”。“释放” 不是一个可阻塞的操作;“释放” 可以允许线程在请求执行前阻塞。
为了让一个类具有状态依赖性,它必须拥有一些状态。同步类中有一些状态需要管理,这项任务落在了AQS上:**它管理一个关于状态信息的单一整数,状态信息可以通过protected类型的getstate、setstate和compareAndSetstate等方法进行操作**。这可以用于表现任何状态;例如,ReentrantLock 用它来表现拥有它的线程已经请求了多少次锁,Semaphore 用它来表现剩余的许可数,FutureTask 用它来表现任务的状态(尚未开始、运行、完成和取消)。Synchronizer 也可以自己管理- - 些额外的状态变量;例如,ReentrantLock保存了当前锁的所有者的追踪信息,这样它就能区分出是重进入的(reentrant)还是竞争的(contended) 条件锁。

支持独占获取的synchronizer应该实现tryAcquire 、tryRelease 和isHeldExclusively这几个受保护的方法,而支持共享获取的Synchronizer应该实现tryAcquireShared和tryReleaseShared。 AQS中的acquire,、acqui reShared、release和releaseShared这些方法,会调用在Synchronizer子类中这些方法的版本(tryAcquire、tryAcquireShared等等),以此决定是否执行该操作。Synchronizer的子类会根据其acquire 和release 的语意,使用getstate、 setstate以及compareAndSetState来检查并更新状态状态,然后通过返回的状态值告知基类这次“获取”或“释放”的尝试是否成功。举例来说,从tryAcquireShared返回一个负值,说明获取操作失败;返回零说明Synchronizer是被独占获取的;返回正值说明synchronizer. 是被非独占获取的。对于tryRelease和tryReleaseShared方法来说,如果能够释放一些正在尝试获取synchronizer的线程,解除这些线程的阻塞,那么这两个方法将返回true。
为了简化锁的实现,以支持条件队列(就像ReentrantLock),AQS还提供了一些机制,用于创建与synchronizer相关联的条件变量。
1 | |
14.6 java.til.concurrent的Synchronizer类中的AQS
- ReentrantLock
- Semaphore
- CountDownLatch
- FutureTask
- ReentrantReadWriteLock
如果你需要实现一个依赖于状态的类如果不能满足依赖于状态的前提条件,类的方法必须阻塞–最佳的策略通常是将它构建于现有的库类之上,比如Semaphore、BlockingQueue或者CountDownLatch,例如187页的ValueLatch那样。但是,有时现有的库类不能提供足够的功能;在这种情况之下,你可以使用内部条件队列、显式Condition对象或者Abst ractQueuedSynchronizer,来构建属于自己的synchronizer.由于“管理状态的独立性”机制必须紧密依赖于“确保状态一致性” 机制,所以内部条件队列与内部锁紧密地绑定到了-起。类似地,显式的Condition是与显式的Lock也是紧密地绑定到- -起的,相比于内部条件队列,它还提供了一个可扩展的特征集,包括“多等待集每锁”,可中断或不可中断的条件等待,公平或非公平的队列,以及基于最终时限的等待。
第15章原子变量与非阻塞同步机制
15.1 锁的劣势
当频繁地发生锁的竞争时,调度真正用于工作的开销间的比值很可观.
volatile变量与锁相比是更轻量的同步机制,因为它们不会引起上下文的切换和线程调度。然而,volatile 变量与锁相比有一些局限性:尽管它们提供了相似的可见性保证,但是它们不能用于构建原子化的复合操作。
加锁还有其他的缺点。当一一个线程正在等待锁时,它不能做任何其他事情。如果- -个线程在持有锁的情况下发生了延迟(原因包括页错误、调度延迟,或者类似情况),那么其他所有需要该锁的线程都不能前进了。如果阻塞的线程是优先级很高的线程,持有锁的线程优先级较低,那么会造成严重问题一性能风险,被称为优先级倒置( priority inversion)。即使更高的优先级占先,它仍然需要等待锁被释放,这导致它的优先级会降低至与优先级较低的线程的水平.
15.2 硬件对并发的支持
独占锁是一项悲观的技术一它 假设最坏情况(如果你不锁门,捣蛋鬼就会闯入,并破坏物品的秩序),并且会通过获得正确的锁来避免其他线程的打扰,直到作出保证才能继续进行。
对于细粒度的操作,有另外一种选择通常更加有效一乐观的解 决方法。凭借新的方法,我们可以指望不受打扰地完成更新。这个方法依赖于冲突监测,从而能判定更新过程中是否存在来自于其他成员的干涉,在冲突发生的情况下,操作失败,并会重试(也可能不重试)。这个乐观的方案就好比我们常说的:“宽恕 比准许更容易”,其中“更容易”意味着“更有效率”。
针对多处理器系统设计的处理器提供了特殊的指令,用来管理并发访问的共享数据。早期处理器具有原子化的测试并设量r ( test-and-set),获取并增加(fetch-and-increment)以及交换(swap)指令,这些对于实现互斥已经足够了,并能够用于实现更成熟的并发对象。如今,几乎所有现代的处理器都具有-些形式的原子化的读-改写指令,比如比较并交换(compare-and-swap)和加链搂/存储条件(load-linked/store conditional)操作系统和JVM使用这些指令来实现锁和并发的数据结构,但是直到Java5.0以前这些还不能直接为Java类所使用。
15.3 原子变量类
原子变量是更佳的volatile
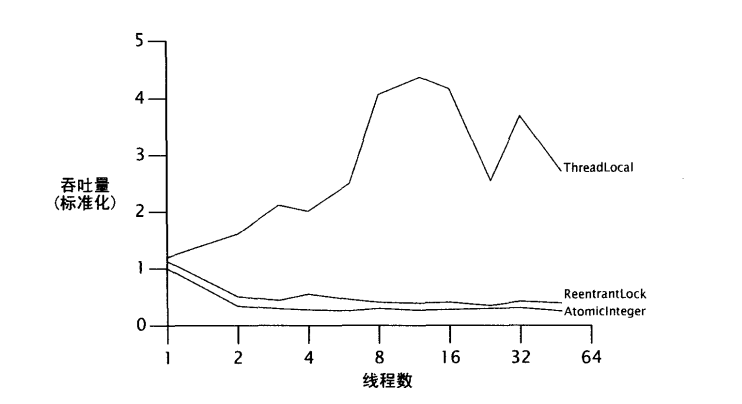
Lock和AtomicInteger在激烈竞争下的性能比较
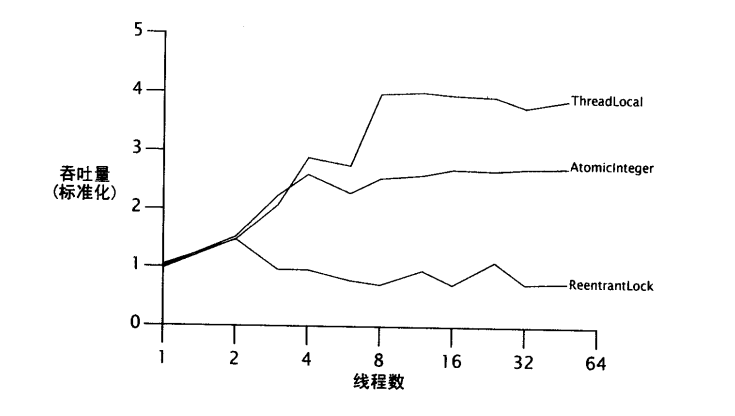
Lock和AtomicInteger在中等竞争下的性能比较
15.4 非阻塞算法
基于锁的算法会带来-些活跃度失败的风险。如果线程在持有锁的时候因为阻塞I/O,页面错误,或其他原因发生延迟,很可能所有线程都不能前进了。一个线程的失败或挂起不应该影响其他线程的失败或挂起,这样的算法被称为非阻塞(nonblocking)算法;如果算法的每一步骤中都有一-些线程 能够继续执行,那么这样的算法称为债自由(lock-free)算法。在线程间使用CAS进行协调,这样的算法如果能构建正确的话,它既是非阻塞的,又是锁自由的。非竞争的CAS总是能够成功,如果多个线程以一个CAS竞争,总会有一个胜出并前进。非阻塞算法对死锁和优先级倒置有“免疫性”(但它们可能会出现饥饿和活锁,因为它们允许重进入)。到目前为止,我们已经见到一个非阻塞算法:CasCounter.好的非阻塞算法已经在多种常见的数据结构上现身,包括栈、队列、优先级队列、哈希表.
ABA问题
ABA问题是因为在算法中误用比较并交换而引起的反常现象,节点被循环使用(主要存在于不能被垃圾回收的环境中)。CAS有效地请求“V的值仍为A么?”,并且如果成立就继续处理更新。在大多数情况下,包括这一章展示的例子,已经足够使用了。但是有时我们还想询问“V在我上次观察过后发生了改变么?”在某些算法中,把V的值由A转换为B,再转换为A仍然记为一次改变, 需要我们重新进行算法中的某些步骤。
算法中如果进行自身链接节点对象的内存管理,那么可能出现ABA问题。在这种情况下,即使列表的头仍然指向之前观察到的节点,这也不足以说明列表的内容没有发生改变。如果让垃圾回收器为你管理链表的节点,仍然不能避免ABA问题,还有-一个相对简单的解决方案:更新一对值,包括引用和版本号,而不是仅更新该值的引用。即使值由A改为B,又再改回A,版本号也是不同的。AtomicstampedReference (以及它的同系AtomicMarkableReference)提供了一对变量原子化的条件更新AtomicstampedReference更新对象引用的整数对,允许“版本化”引用是能够避免 ABA问题的。类似地,Atomi cMarkableReference :更新一个对象引用的布尔对,它能够用于一些算法,使节点在被标记为“deleted”后仍保留在列表中。
非阻塞算法通过使用低层级并发原语,比如比较并交换,取代了锁。原子变量类向用户提供了这些低层级原语,也能够当作“更佳的volatile 变量”使用,同时提供了整数类和对象引用的原子化更新操作。非阻塞算法在设计和实现中很困难,但是在典型条件下能够提供更好的可伸缩性,并能更好地预防活跃度失败。从JVM的一个版本到下一个版本间并发性能的提升很大程度上来源于非阻塞算法的使用,包括在JVM内部以及平台类库。
第16章Java存储模型
16.1 什么是存储模型
JMM
重排序
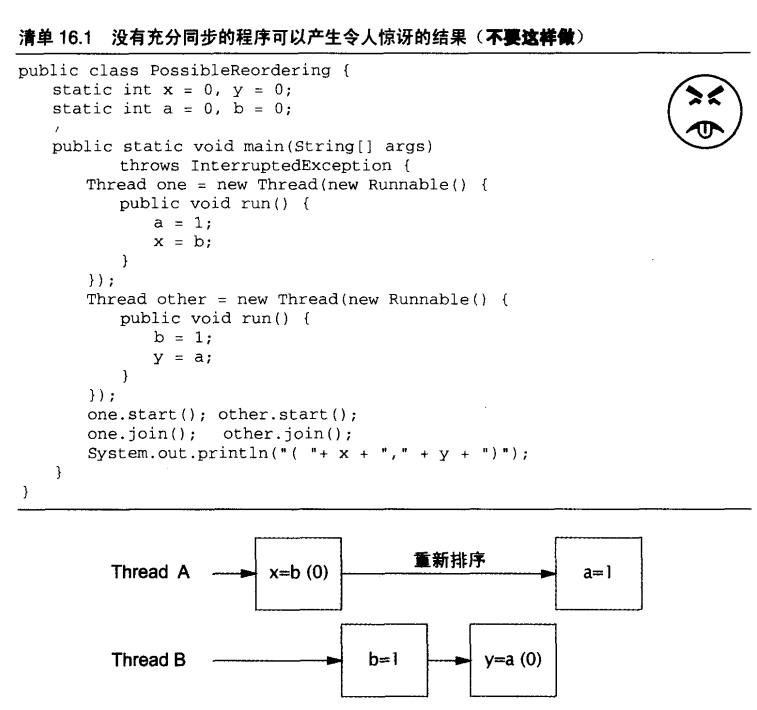
happens-before的法则包括:
- 程序次序法则:线程中的每个动作A都happens-before于该线程中的每一个动作B,其中,在程序中,所有的动作B都出现在动作A之后。
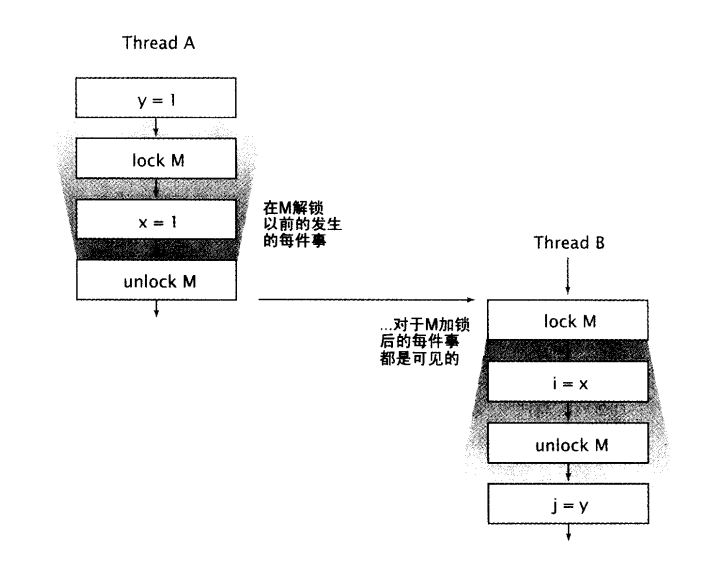
- 监视器锁法则:对一个监视器锁的解锁happens-before 于每一个后续对同一监视器锁的加锁。
- volatile变量法则:对volatile 域的写入操作happens-before于每一个后续对同一域的读操作”。
- 线程启动法则:在一个线程里,对Thread. start的调用会happens -before于每一个启动线程中的动作。
- 线程终结法则:线程中的任何动作都happens before于其他线程检测到这个线程已经终结、或者从Thread.join调用中成功返回,或者Thread. isAlive返回false.
- 中断法则:一个线程调用另一个线程的interrupt happens-before 于被中断的线程发现中断(通过抛出InterruptedException, 或者调用isInterrupted 和interrupted)。
- 终结法则:一个对象的构造函数的结東happens-before于这个对象finalizer的开始。
- 传递性:如果A happens-before于B,且B happens-before于C,则Ahappens-before于C.
16.2 发布
在缺少happens-before关系的情况下,存在重排序的可能性。这就解释了为什么如果在没有充分同步的情况下就发布-个对象,会导致另外的线程看到一个部分创建对象。新对象的初始化涉及到写入变量一新对 象的域。类似地,引用的发布涉及到写入另一个变量一新对 象的引用。如果你不能保证布共享引用happens-before于另外的线程加载这个共享引用,那么写入新对象的引用与写入对象域(从消费该对象的线程的角度看)可以被重排序。在这种情况下,另一个线程可以看到对象引用的最新值,不过也看到一些或全部对象状态的过期值一个部分创建对象。
双重锁检查(double checked locking)
DCL声称是“鱼与熊掌可兼得”的最佳典范一-惰性 初始化在通常的代码路径下,不需要在同步上花费时间。它运作的方式是,首先检查在没有同步的情况下检查是否需要初始化,如果;resource不等于null,就用它。否则,就进行同步,并再次检查Resource是否需要同步,以保证只有唯一的线程真正地初始化了共享的Resource。 通常的代码路径一获取一个已经构建的Resource的引用并没有用到同步。
16.3 初始化安全性
初始化安全可以保证,对于正确创建的对象,无论它是如何发布的,所有线程都将看到构造函数设置的final域的值。更进一步,一个正确创建的对象中,任何可以通过其final堿触及到的变量(比如一一个final数组中的元素,或者一个final域引用的HashMap里面的内容),也可以保证对其他线程都是可见的“。
