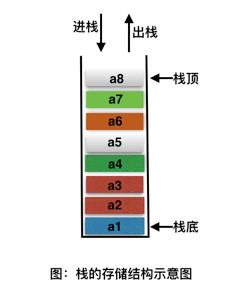
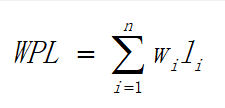栈(stack) 栈(stack)是限制插入和删除只能在一 个位置上进行的表,该位置是表的末端,叫做栈顶(top)。它是后进先出(LIFO)的。对栈的基本操作只有 push(进栈)和 pop(出栈)两种, 前者相当于插入,后者相当于删除最后的元素。
特点: 先进后出
堆(heap) 定义:完全二叉树的数组对象,将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。 n个元素的序列{k1,k2,ki,…,kn}当且仅当满足下关系时,称之为堆。(ki = k2i,ki >= k2i+1), (i = 1,2,3,4…n/2)
特点: 非线性数据结构,相当于一维数组,有两个直接后继。常见的堆有二叉堆、斐波那契堆等。
堆上浮
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution {public void upAdjust (int [] array) {int childIndex = array.length - 1 ;int parentIndex = (childIndex - 1 ) / 2 ;int temp = array[childIndex];while (childIndex > 0 && temp < array[parentIndex]) {1 ) / 2 ;
堆下沉
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution {public void downAdjust (int [] array, int parentIndex, int length) {int temp = array[parentIndex];int childIndex = 2 * parentIndex + 1 ;while (childIndex < length) {if (childIndex + 1 < length && array[childIndex + 1 ] < array[childIndex]) {if (temp < array[childIndex]) break ;2 * childIndex + 1 ;
普通队列(queue) 队列是一种特殊的 线性表 ,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。
特点: 后进先出
优先队列(PriorityQueue)
无论入队顺序如何,都是当前最大的元素优先出队
无论入队顺序如何,都是当前最小的元素优先出队
优先队列代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 public class PriorityQueue {private int [] array;private int size;public PriorityQueue () {new int [32 ];public void enQueue (int key) {if (size >= array.length) {public int deQueue () throws Exception {if (size <= 0 ) {throw new Exception ("the queue is empty !" );int head = array[0 ];0 ] = array[--size];return head;private void upAdjust () {int childIndex = size - 1 ;int parentIndex = (childIndex - 1 ) / 2 ;int temp = array[childIndex];while (childIndex > 0 && temp > array[parentIndex]) {2 ;private void downAdjust () {int parentIndex = 0 ;int temp = array[parentIndex];int childIndex = 1 ;while (childIndex < size) {if (childIndex + 1 < size && array[childIndex + 1 ] > array[childIndex]) {if (temp >= array[childIndex])break ;2 * childIndex + 1 ;private void resize () {int newSize = this .size * 2 ;this .array = Arrays.copyOf(this .array, newSize);public static void main (String[] args) throws Exception {PriorityQueue priorityQueue = new PriorityQueue ();3 );5 );10 );2 );7 );" 出队元素:" + priorityQueue.deQueue());" 出队元素:" + priorityQueue.deQueue());
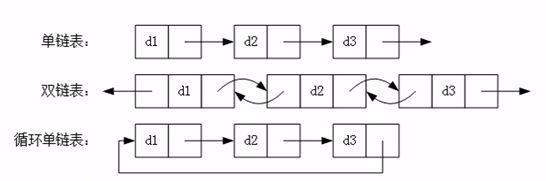
链表(Link) 链表是一种数据结构,和数组同级。比如,Java 中我们使用的 ArrayList,其实现原理是数组。而LinkedList 的实现原理就是链表了。链表在进行循环遍历时效率不高,但是插入和删除时优势明显。
特点: 插入、修改速度快、查询速度慢
散列表(Hash Table) 散列表(Hash table,也叫哈希表)是一种查找算法,与链表、树等算法不同的是,散列表算法在查找时不需要进行一系列和关键字(关键字是数据元素中某个数据项的值,用以标识一个数据元素)的比较操作。
散列表算法希望能尽量做到不经过任何比较,通过一次存取就能得到所查找的数据元素,因而必须要在数据元素的存储位置和它的关键字(可用 key 表示)之间建立一个确定的对应关系,使每个关键字和散列表中一个唯一的存储位置相对应。因此在查找时,只要根据这个对应关系找到给定关键字在散列表中的位置即可。这种对应关系被称为散列函数(可用 h(key)表示)。
用的构造散列函数的方法有:
树结构(Tree)
计算机科学中的树
二叉树
二叉树/二叉查找树/笛卡尔树/Top tree
自平衡二叉查找树
AA树/AVL树/红黑树/伸展树/树堆/节点大小平衡树
B树
B树/B+树/B*树/Bx树/UB树/2-3树/2-3-4树/(a,b)-树/Dancing tree/ H树
Trie
前缀树/后缀树/基数树
空间划分树
四叉树/八叉树/k-d树/vp-树/R树/R*树/R+树/X树/M树/线段树/希尔伯特R树/优先R树
非二叉树
Exponential tree/Fusion tree/区间树/PQ tree/Range tree/SPQR tree/Van Emde Boas tree
其他类型
堆/散列树/Finger tree/Metric tree/Cover tree/BK-tree/Doubly-chained tree/iDistance/Link-cut tree/树状数组
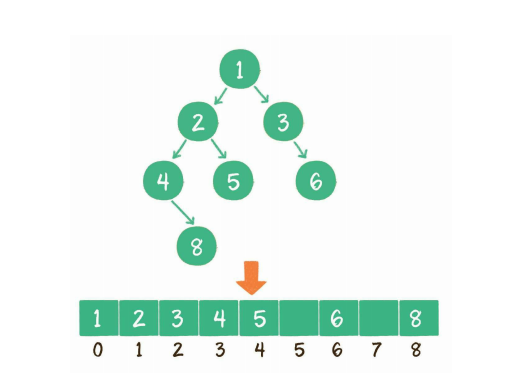
两种存储结构:链表和数组
数组表示按照二叉树深度优先存入二维数组
父节点下标=parentparent+1 parent+2
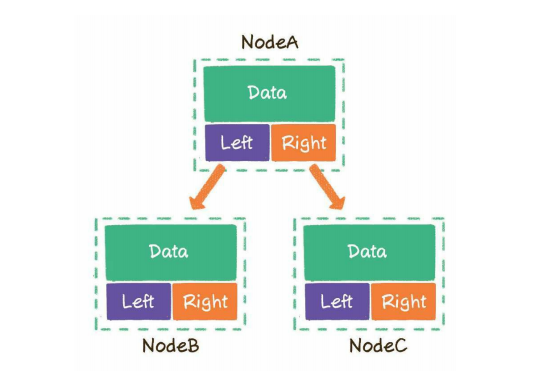
left指向左子树,right指向右子树
二叉树(Binary tree) 定义: 由一个称为根(root)的元素及两个不相交的、被分别称为左子树和右子树的二叉树组成,是有序树
graph TB;
A((1))-->B((2))
A((1))-->C((3))
B((2))-->E((4))
B((2))-->F((5))
C((3))-->G((6))
C((3))-->H((7))
平衡二叉树(Balance Tree)
任意节点的子树的高度差都小于等于1,并且左右两个子树都是一棵平衡二叉树。
详细内容
完全二叉树 定义:叶子结点只能出现在最下层和次下层,且最下层的叶子结点集中在树的左部。
graph TB;
A((1))-->B((2))
A((1))-->C((3))
B((2))-->E((4))
B((2))-->F((5))
C((3))-->G((6))
C((3))-->H((7))
E((4))-->i((8))
E((4))-->j((9))
F((5))-->k((10))
特点:
完全二叉树判定算法思路
1 2 3 4 5 6 7 判断一棵树是否是完全二叉树的思路
满二叉树(Full Binary Tree) 定义:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果一个二叉树的层数为K,且结点总数是(2^k) -1 ,则它就是满二叉树。
graph TB;
A((1))-->B((2))
A((1))-->C((3))
B((2))-->E((4))
B((2))-->F((5))
C((3))-->G((6))
C((3))-->H((7))
特点:一个层数为k的满二叉树的叶子结点个数(也就是最后一层):2^(k-1)
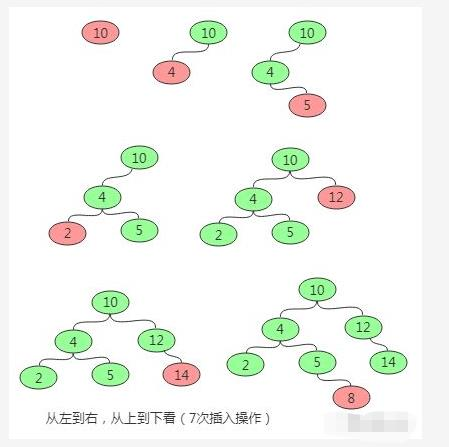
二叉排序树(Binary Sort Tree) 定义:左子树所有节点值小于它的根节点值,且右子树所有节点值大于它的根节点值,则这样的二叉树就是排序二叉树。
插入操作
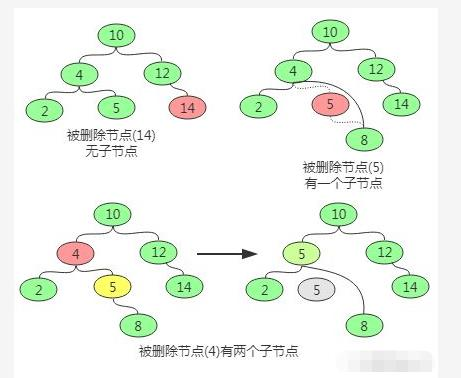
删除操作
删除操作主要分为三种情况,即要删除的节点无子节点,要删除的节点只有一个子节点,要删除的节点有两个子节点。
对于要删除的节点无子节点可以直接删除,即让其父节点将该子节点置空即可。
对于要删除的节点只有一个子节点,则替换要删除的节点为其子节点。
对于要删除的节点有两个子节点,则首先找该节点的替换节点(即右子树中最小的节点),接着替换要删除的节点为替换节点,然后删除替换节点。
查询操作
查找操作的主要流程为:先和根节点比较,如果相同就返回,如果小于根节点则到左子树中递归查找,如果大于根节点则到右子树中递归查找。因此在排序二叉树中可以很容易获取最大(最右最深子节点)和最小(最左最深子节点)值。
它能确保任何一个结点的左右子树的高度差小于两倍。
详细参考
红黑树(Red-Black-Tree) R-B Tree,全称是 Red-Black Tree,又称为“红黑树”,它一种特殊的二叉查找树(近似平衡的二叉搜索树)。红黑树的每个节点上都有存储位表示节点的颜色,可以是红(Red)或黑(Black)。
红黑树的特性
(1)每个节点或者是黑色,或者是红色。
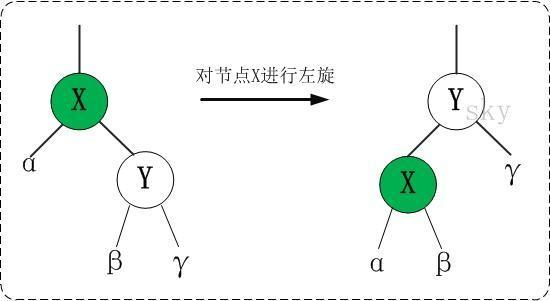
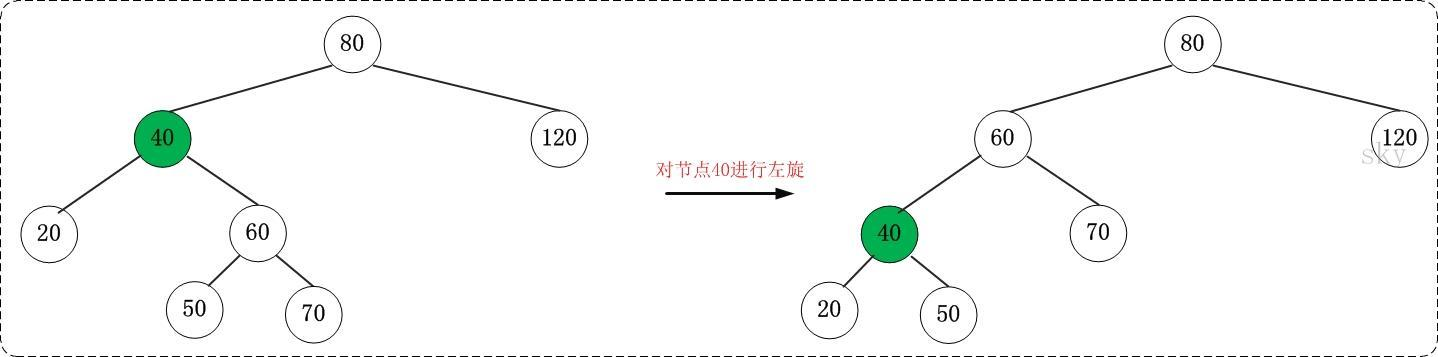
左旋
对 x 进行左旋,意味着,将“x 的右孩子”设为“x 的父亲节点”;即,将 x 变成了一个左节点(x成了为 z 的左孩子)!。 因此,左旋中的“左”,意味着“被旋转的节点将变成一个左节点”。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 LEFT-ROTATE(T, x)
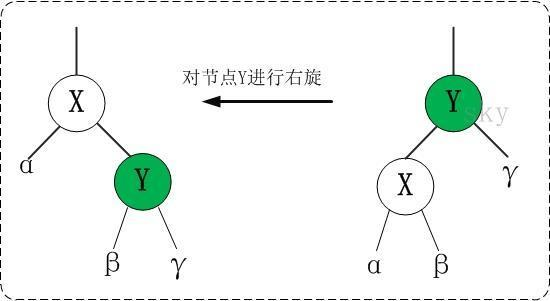
右旋
对 x 进行右旋,意味着,将“x 的左孩子”设为“x 的父亲节点”;即,将 x 变成了一个右节点(x成了为 y 的右孩子)! 因此,右旋中的“右”,意味着“被旋转的节点将变成一个右节点”。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 RIGHT-ROTATE(T, y)
添加
第一步: 将红黑树当作一颗二叉查找树,将节点插入。
第二步:将插入的节点着色为”红色”。根据被插入节点的父节点的情况,可以将”当节点 z 被着色为红色节点,并插入二叉树”划分为三种情况来处理。
1 情况说明:被插入的节点是根节点。
处理方法:直接把此节点涂为黑色。
2 情况说明:被插入的节点的父节点是黑色。
处理方法:什么也不需要做。节点被插入后,仍然是红黑树。
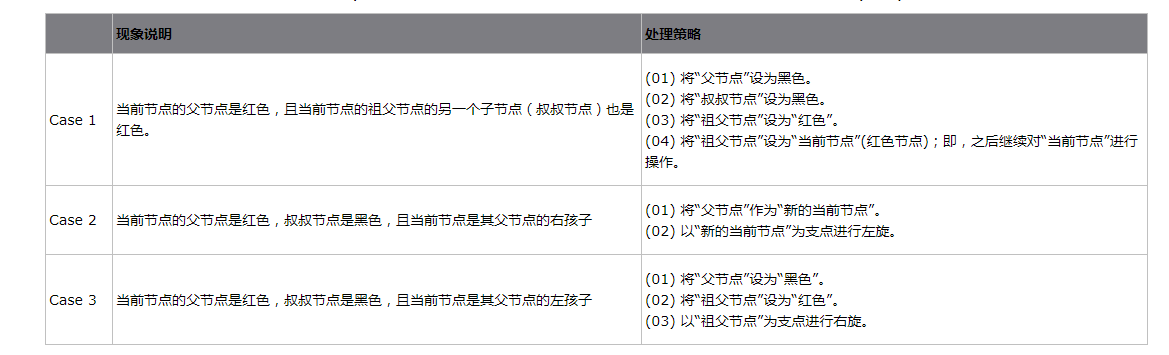
3 情况说明:被插入的节点的父节点是红色。这种情况下,被插入节点是一定存在非空祖父节点的;进一步的讲,被插入节点也一定存在叔叔节点(即使叔叔节点为空,我们也视之为存在,空节点本身就是黑色节点)。理解这点之后,我们依据”叔叔节点的情况”,将这种情况进一步划分为 3种情况(Case)。
第三步: 通过一系列的旋转或着色等操作,使之重新成为一颗红黑树。
删除
第一步:将红黑树当作一颗二叉查找树,将节点删除。这和”删除常规二叉查找树中删除节点的方法是一样的”。分 3 种情况:
第二步:通过”旋转和重新着色”等一系列来修正该树,使之重新成为一棵红黑树。
因为”第一步”中删除节点之后,可能会违背红黑树的特性。所以需要通过”旋转和重新着色”来修正该树,使之重新成为一棵红黑树。
选择重着色 3 种情况。
1 情况说明:x 是“红+黑”节点。
处理方法:直接把 x 设为黑色,结束。此时红黑树性质全部恢复。
2 情况说明:x 是“黑+黑”节点,且 x 是根。
处理方法:什么都不做,结束。此时红黑树性质全部恢复。
3 情况说明:x 是“黑+黑”节点,且 x 不是根。
处理方法:这种情况又可以划分为 4 种子情况。这 4 种子情况如下表所示:
AVL VS Red Balck Tree
参考资料
代码实现
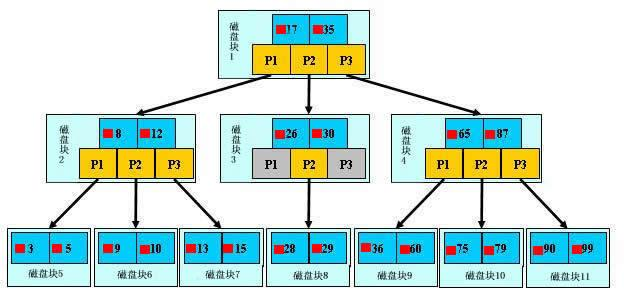
B-Tree B-tree 又叫平衡多路查找树。一棵 m 阶的 B-tree (m 叉树)的特性如下(其中 ceil(x)是一个取上限的函数):
树中每个结点至多有 m 个孩子;
除根结点和叶子结点外,其它每个结点至少有有 ceil(m / 2)个孩子;
若根结点不是叶子结点,则至少有 2 个孩子(特殊情况:没有孩子的根结点,即根结点为叶子结点,整棵树只有一个根节点);
所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部结点或查询失败的结点,实际上这些结点不存在,指向这些结点的指针都为 null);
每个非终端结点中包含有 n 个关键字信息: (n,P0,K1,P1,K2,P2,……,Kn,Pn)。其中:
a) Ki (i=1…n)为关键字,且关键字按顺序排序 K(i-1)< Ki。
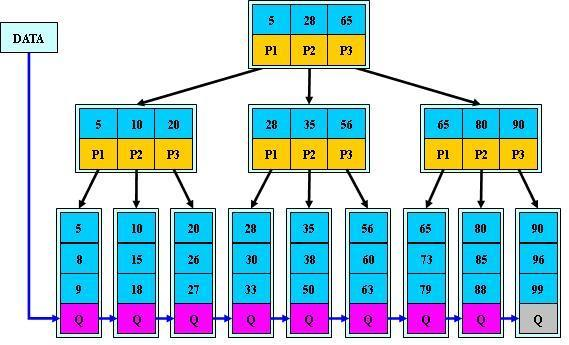
一棵 m 阶的 B+tree 和 m 阶的 B-tree 的差异在于:
B+树(B+Tree) 参考
B_树(B_Tree) 参考
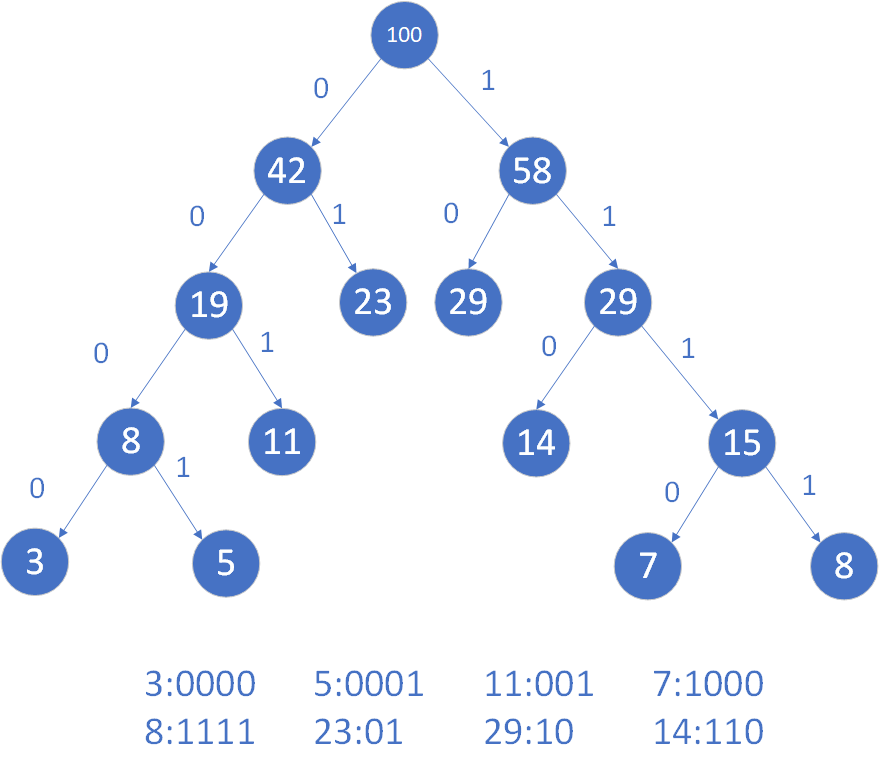
哈夫曼树
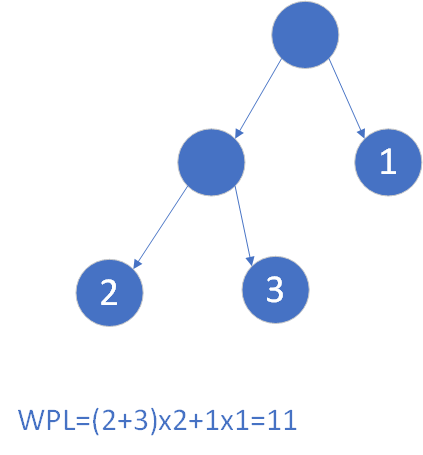
给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
设二叉树具有n个带权值的叶结点,那么从根结点到各个叶结点的路径长度与相应结点权值的乘积的和,叫做二叉树的带权路径长度。
对于具有n个叶子结点的哈夫曼树,共有2n-1个结点
1 2 3 4 5 6 7 typedef struct{
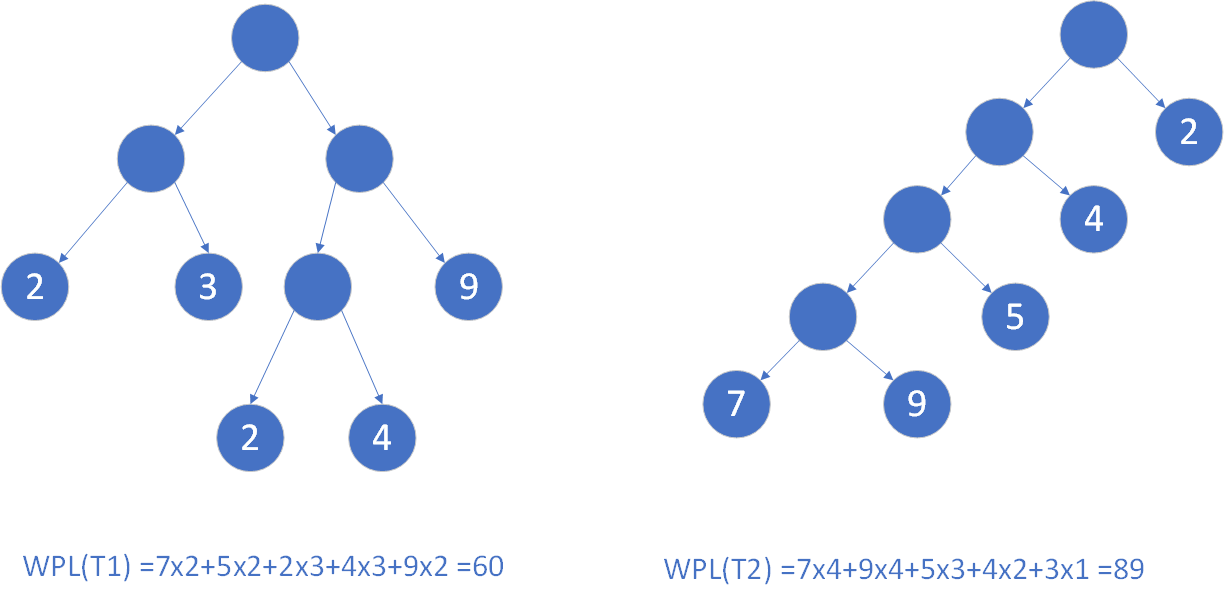
相同的叶结点构造出不同的二叉树
具有最小带权路径长度的二叉树称为哈夫曼树(也称最优树)
构造哈夫曼树的原则:
1 2 权值越大的叶结点越靠近根结点。
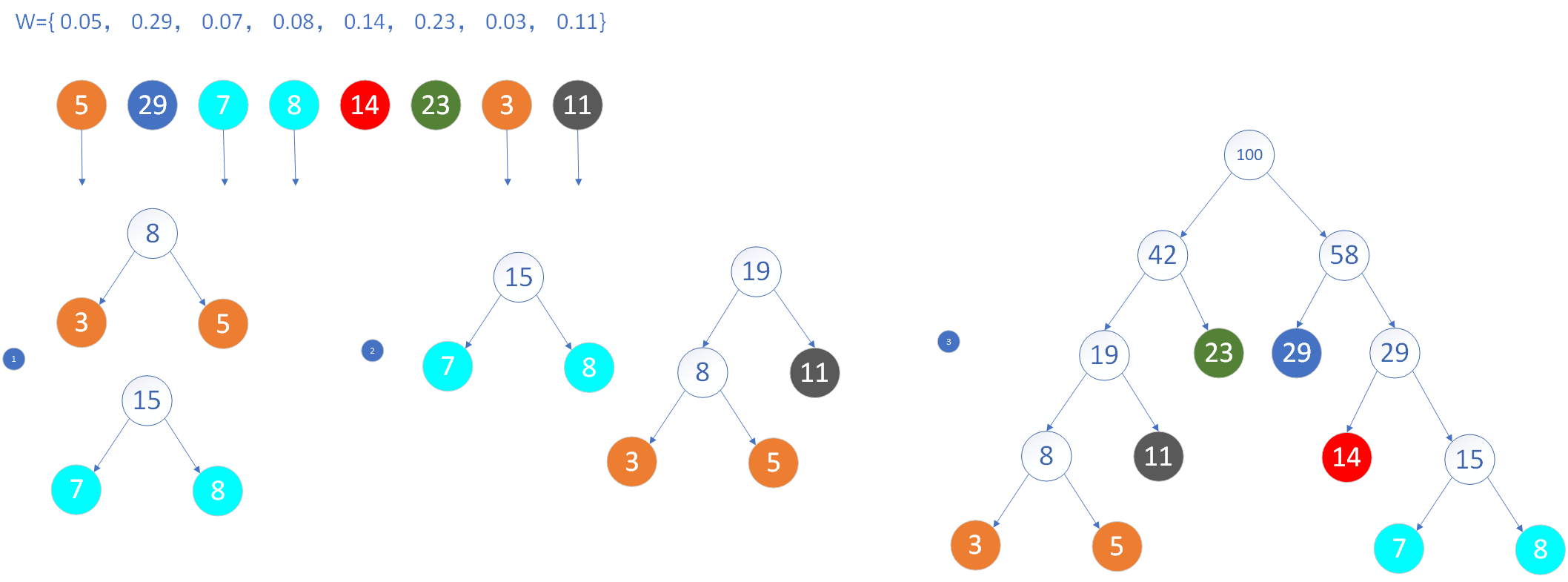
构造哈夫曼树的过程:
1 2 3 4 (1)给定的n个权值{W1,W2,…,Wn}构造n棵只有一个叶结点的二叉树,从而得到一个二叉树的集合F={T1,T2,…,Tn}。
哈夫曼树的特点:
1 2 n1 = 0:因为每次两棵树合并。
哈夫曼编码
规定哈夫曼树中的左分支为0,右分支为1,则从根结点到每个叶结点所经过的分支对应的0和1组成的序列便为该结点对应字符的编码。这样的编码称为哈夫曼编码。
哈夫曼编码特点:权值越大的字符编码越短,反之越长。哈夫曼编码属0、1二进制编码
在一组字符的哈夫曼编码中,不可能出现一个字符的哈夫曼编码是另一个字符哈夫曼编码的前缀。哈夫曼编码也称为前缀编码。
位图(graph)
位图的原理就是用一个 bit 来标识一个数字是否存在,采用一个 bit 来存储一个数据,所以这样可以大大的节省空间。 bitmap 是很常用的数据结构,比如用于 Bloom Filter 中;用于无重复整数的排序等等。bitmap 通常基于数组来实现,数组中每个元素可以看成是一系列二进制数,所有元素组成更大的二进制集合。
参考资料
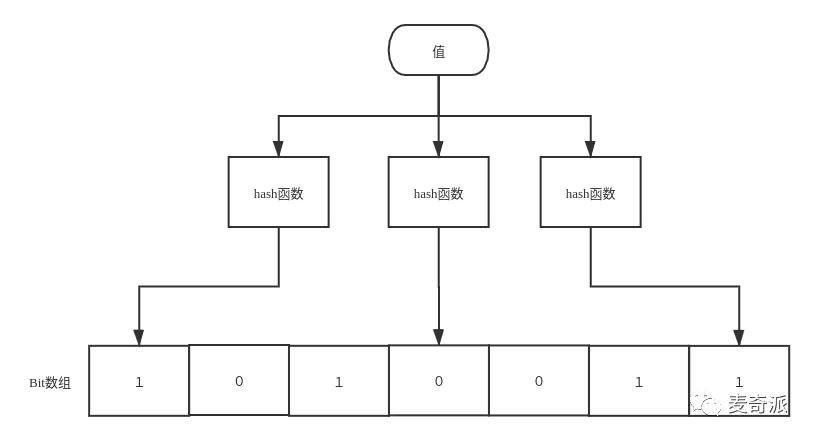
布隆管理器(Bloom Filter) 布隆过滤器是Bloom于1970年提出的,其由二进制向量(或者位数组)和一系列随机映射函数(哈希函数)两个部分组成的数据结构。
位数组中的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1。这样申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 kb ≈ 122kb 的空间
代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 package main;import java.io.Serializable;import java.nio.charset.Charset;import java.security.MessageDigest;import java.security.NoSuchAlgorithmException;import java.util.BitSet;import java.util.Collection;public class BloomFilter <E> implements Serializable {private static final long serialVersionUID = -2326638072608273135L ;private BitSet bitset;private int bitSetSize;private double bitsPerElement;private int expectedNumberOfFilterElements;private int numberOfAddedElements;private int k; static final Charset charset = Charset.forName("UTF-8" );static final String hashName = "MD5" ; static final MessageDigest digestFunction;static { try {catch (NoSuchAlgorithmException e) {null ;public BloomFilter (double c, int n, int k) {this .expectedNumberOfFilterElements = n;this .k = k;this .bitsPerElement = c;this .bitSetSize = (int ) Math.ceil(c * n);0 ;this .bitset = new BitSet (bitSetSize);public BloomFilter (int bitSetSize, int expectedNumberOElements) {this (bitSetSize / (double ) expectedNumberOElements, expectedNumberOElements, (int ) Math.round((bitSetSize / (double ) expectedNumberOElements)* Math.log(2.0 )));public BloomFilter (double falsePositiveProbability, int expectedNumberOfElements) {this (Math.ceil(-(Math.log(falsePositiveProbability) / Math.log(2 )))/ Math.log(2 ), int ) Math.ceil(-(Math.log(falsePositiveProbability) / Math.log(2 )))); public BloomFilter (int bitSetSize, int expectedNumberOfFilterElements, int actualNumberOfFilterElements, BitSet filterData) {this (bitSetSize, expectedNumberOfFilterElements);this .bitset = filterData;this .numberOfAddedElements = actualNumberOfFilterElements;public static long createHash (String val, Charset charset) {return createHash(val.getBytes(charset));public static long createHash (String val) {return createHash(val, charset);public static long createHash (byte [] data) {long h = 0 ;byte [] res;synchronized (digestFunction) {for (int i = 0 ; i < 4 ; i++) {8 ;int ) res[i]) & 0xFF ;return h;@Override public boolean equals (Object obj) {if (obj == null ) {return false ;if (getClass() != obj.getClass()) {return false ;final BloomFilter<E> other = (BloomFilter<E>) obj;if (this .expectedNumberOfFilterElements != other.expectedNumberOfFilterElements) {return false ;if (this .k != other.k) {return false ;if (this .bitSetSize != other.bitSetSize) {return false ;if (this .bitset != other.bitsetthis .bitset == null || !this .bitset.equals(other.bitset))) {return false ;return true ;@Override public int hashCode () {int hash = 7 ;61 * hash + (this .bitset != null ? this .bitset.hashCode() : 0 );61 * hash + this .expectedNumberOfFilterElements;61 * hash + this .bitSetSize;61 * hash + this .k;return hash;public double expectedFalsePositiveProbability () {return getFalsePositiveProbability(expectedNumberOfFilterElements);public double getFalsePositiveProbability (double numberOfElements) {return Math.pow((1 - Math.exp(-k * (double ) numberOfElementsdouble ) bitSetSize)), k);public double getFalsePositiveProbability () {return getFalsePositiveProbability(numberOfAddedElements);public int getK () {return k;public void clear () {0 ;public void add (E element) {long hash;String valString = element.toString();for (int x = 0 ; x < k; x++) {long ) bitSetSize;int ) hash), true );public void addAll (Collection<? extends E> c) {for (E element : c)public boolean contains (E element) {long hash;String valString = element.toString();for (int x = 0 ; x < k; x++) {long ) bitSetSize;if (!bitset.get(Math.abs((int ) hash)))return false ;return true ;public boolean containsAll (Collection<? extends E> c) {for (E element : c)if (!contains(element))return false ;return true ;public boolean getBit (int bit) {return bitset.get(bit);public void setBit (int bit, boolean value) {public BitSet getBitSet () {return bitset;public int size () {return this .bitSetSize;public int count () {return this .numberOfAddedElements;public int getExpectedNumberOfElements () {return expectedNumberOfFilterElements;public double getExpectedBitsPerElement () {return this .bitsPerElement;public double getBitsPerElement () {return this .bitSetSize / (double ) numberOfAddedElements;
优点
占用空间小,节省内存空间。
查询效率高,相对于普通的容器结构。
缺点
原理
1.当元素加入布隆过滤器的时候,会对元素进行哈希运算,得到其哈希值(有几个函数得到几个哈希值)
特点
应用场景
防止恶意请求,缓存穿透,垃圾邮件,黑名单。
去重功能。
实际应用
比特币网络
分布式系统(Map-Reduce) - Hadoop、Search engine
Redis缓存
垃圾邮件、评论等的过滤
最近使用缓存(LRU Cache)
两个要素: 大小、替换策略
HashTable + Double LinkedList
O(1)查询、O(1)修改、更新
LRU Cache
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 public class LRUCache {class DLinkedNode {int key;int value;public DLinkedNode () {public DLinkedNode (int _key, int _value) {private Map<Integer, DLinkedNode> cache = new HashMap <Integer, DLinkedNode>();private int size;private int capacity;private DLinkedNode head, tail;public LRUCache (int capacity) {this .size = 0 ;this .capacity = capacity;new DLinkedNode ();new DLinkedNode ();public int get (int key) {DLinkedNode node = cache.get(key);if (node == null ) {return -1 ;return node.value;public void put (int key, int value) {DLinkedNode node = cache.get(key);if (node == null ) {DLinkedNode newNode = new DLinkedNode (key, value);if (size > capacity) {DLinkedNode tail = removeTail();else {private void addToHead (DLinkedNode node) {private void removeNode (DLinkedNode node) {private void moveToHead (DLinkedNode node) {private DLinkedNode removeTail () {DLinkedNode res = tail.prev;return res;
参考资料 数据结构-在线演示